- The paper introduces a multi-agent testbed, WereWolf-Plus, that provides refined role-specific metrics and enhanced evaluation compared to DSGBench.
- It employs diverse roles and modular configurations to assess AI agents’ social reasoning, cooperation, and strategic decision-making.
- Experimental results show that the Deepseek-V3 model outperforms other LLMs through effective experience-retrieval augmentation strategies.
Highlights of "WereWolf-Plus: An Update of Werewolf Game setting Based on DSGBench"
The paper "WereWolf-Plus: An Update of Werewolf Game setting Based on DSGBench" introduces an advanced multi-agent testbed, WereWolf-Plus, designed to evaluate the strategic reasoning of LLM-based agents in complex social settings. WereWolf-Plus extends the limitations of existing platforms by providing a multi-model, multi-dimensional evaluation of agents engaged in the Werewolf game. Using a framework that supports heterogeneous role assignments and enriched evaluation metrics, the study aims to assess key capabilities such as social reasoning, cooperation, and strategic influence.
Framework Overview and Features
The foundation of WereWolf-Plus is a robust simulation environment that adheres closely to the standard roles and rules of the Werewolf game. The framework facilitates scenarios with varied roles such as Seer, Witch, Hunter, Guard, and Sheriff, thus enabling a nuanced analysis of agents' skills across differing roles.
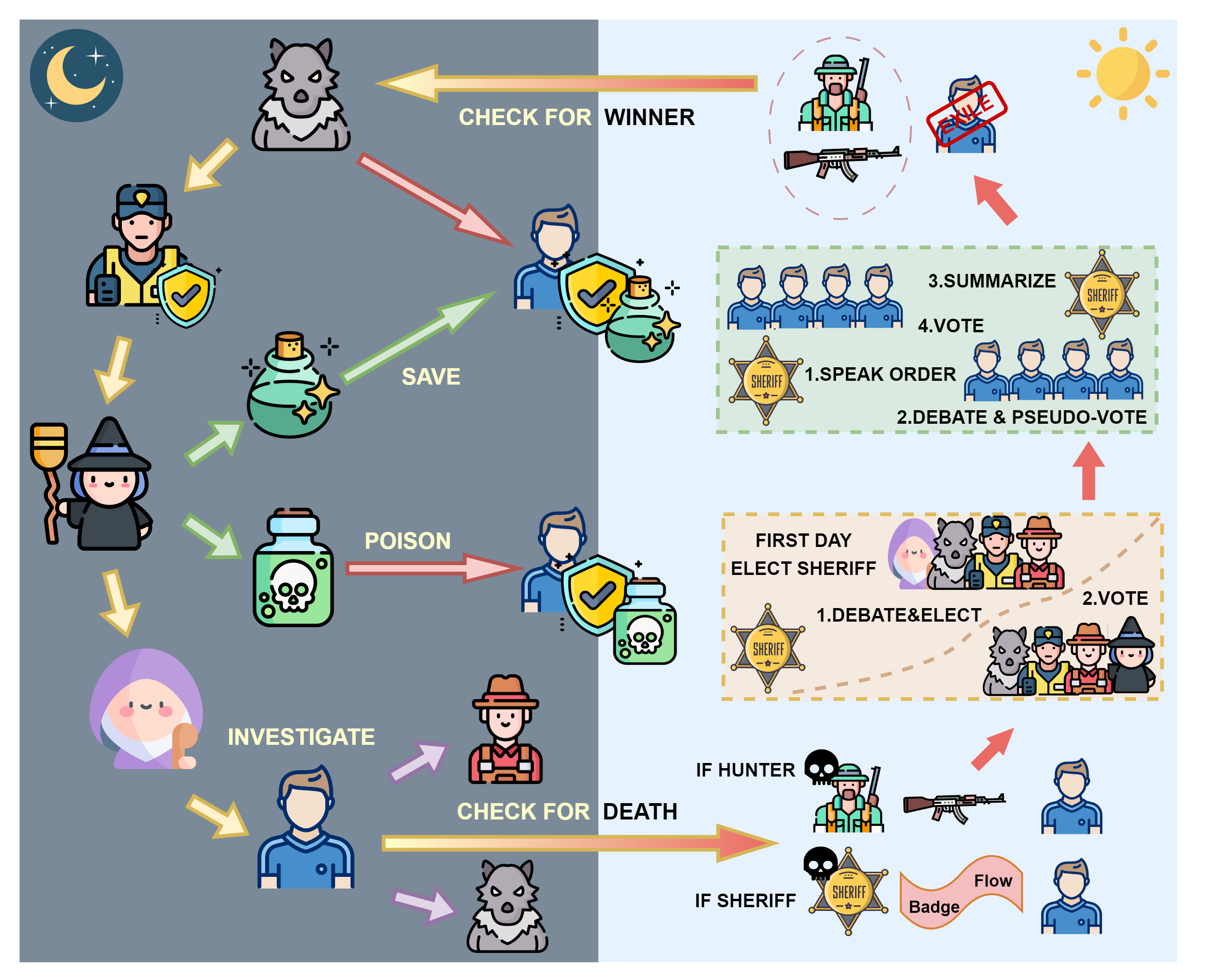
Figure 1: The Complete Game Flow of WereWolf-Plus.
Key features include role-specific evaluations and agent models configured to reflect a spectrum of reasoning and cooperation strategies. Crucially, the simulation environment is highly extensible, supporting a wide array of configurations and customized model assignments.
Quantitative Evaluation Metrics
The paper proposes distinct character-oriented and player-oriented metrics that effectively capture the intricate dynamics of Werewolf gameplay. Metrics include:
- Seer Success Rate: Tracks how often the Seer identifies a werewolf.
- Witch Effectiveness: Assesses the Witch's decisions in saving or eliminating players.
- Sheriff Influence Score: Measures the change in player votes influenced by the sheriff's recommendations.
These metrics offer comprehensive insights into role-specific performances, aiding in identifying strengths and weaknesses in the agents’ decision-making processes.
Improvements Over DSGBench
WereWolf-Plus addresses significant gaps identified in previous benchmarks such as DSGBench. It ensures enhanced evaluation depth through:
- Complete inclusion of additional roles and game configurations.
- A set of refined assessment metrics tailored for each role, improving diagnostic precision.
- Improved modularity and rule adherence, thereby ensuring robustness and accuracy of simulations.
Experimental Insights
Experiments conducted demonstrated that the Deepseek-V3 model performs consistently better across varied roles when compared to other LLM models such as Doubao and GPT-4o-mini. The use of an experience-retrieval augmentation mechanism effectively boosted agents' strategic reasoning by leveraging historical interaction data to inform future decision-making.
Conclusion and Future Directions
WereWolf-Plus stands as a critical advancement for testing LLM agents within a social deduction game environment. By enabling precise evaluation and strategic refinement, this platform opens avenues for exploring cooperative and competitive interactions in AI. Future research could expand by incorporating more diverse strategic scenarios, exploring cross-agent dynamics, and refining retrieval strategies for enhanced decision-making.
In summary, the study provides a comprehensive framework for evaluating AI's social intelligence, offering a path forward in developing agents capable of nuanced interaction and strategic reasoning.