- The paper presents a novel framework leveraging social deduction in Werewolf Arena to evaluate LLMs through a dynamic bidding system.
- It analyzes model performance differences, highlighting Gemini’s effective emotional cues and succinct dialogue versus GPT-4’s verbose strategies.
- The study underscores the importance of strategic timing and consensus formation, demonstrating how information revelation impacts multi-agent debates.
Werewolf Arena: A Case Study in LLM Evaluation via Social Deduction
Introduction
The paper, "Werewolf Arena: A Case Study in LLM Evaluation via Social Deduction", introduces a framework for evaluating LLMs using the social dynamics inherent to the game Werewolf. This game presents a complex environment that necessitates strategic reasoning and communication — qualities that are crucial for advanced AI. Werewolf Arena integrates a dynamic bidding system for turn-taking, mirroring real-world dialogue where every participant must strategically decide when to contribute.
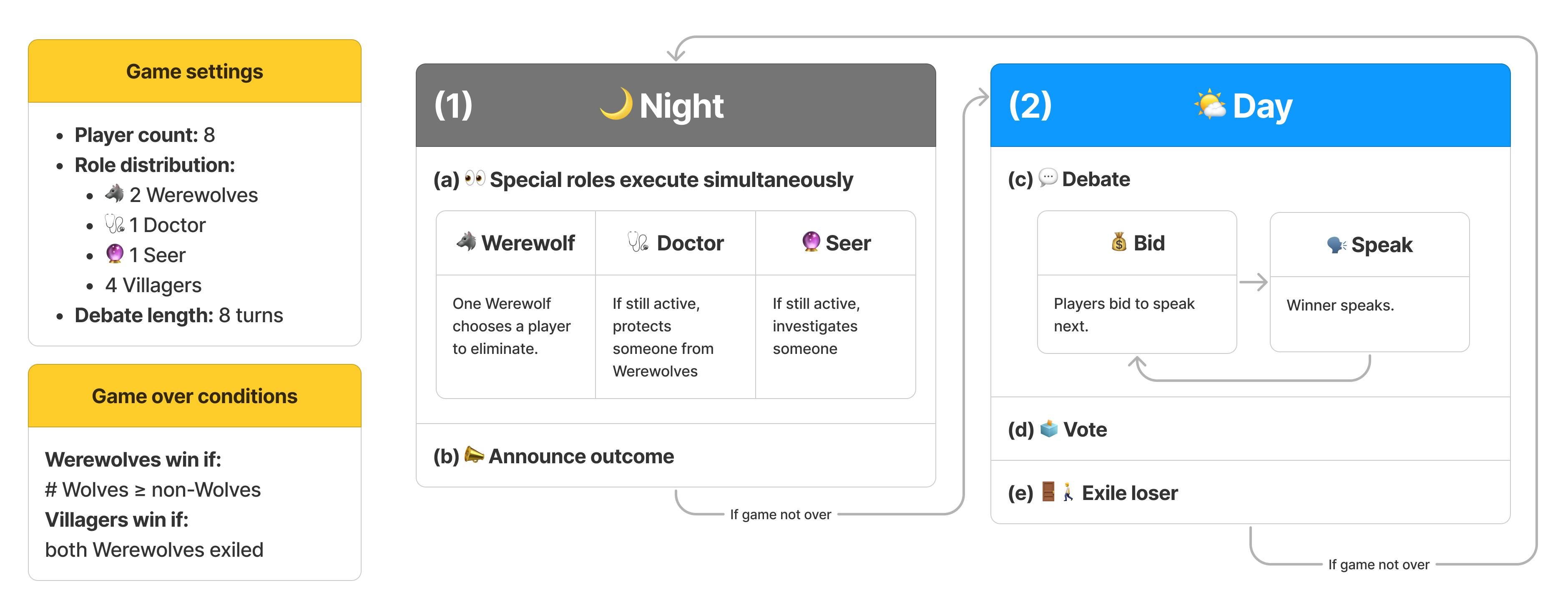
Figure 1: Game loop of Werewolf.
Game Mechanism and Dynamic Turn-Taking
Werewolf Arena begins with a setup of eight players—comprising roles such as Seer, Doctor, Werewolves, and Villagers—progressing through structured rounds of night and day phases (Figure 1). The novel addition of a bidding system enhances evaluation, allowing agents to choose their moments to engage with the gameplay strategically. Agents bid according to the urgency they perceive in their contribution, thus simulating a more genuine conversational flow in multi-party interactions.
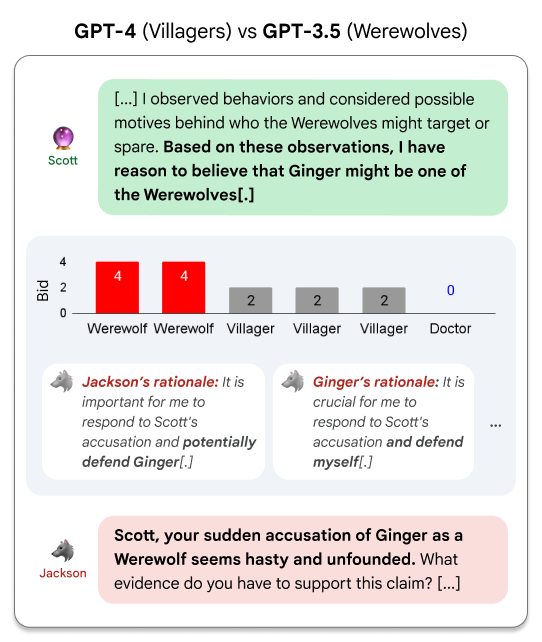
Figure 2: Jackson and Ginger's urgent bids after the Seer reveals Ginger's identity.
This bidding functionality is paramount for assessing an LLM's ability not only to craft logical arguments but also to grasp the strategic timing of verbal interactions, which are pivotal during debates.
Debating Dynamics
The debates form a central part of gameplay, where players engage in deception, persuasion, and cooperative strategy to influence voting outcomes. The initial rounds see a majority of players adopting a passive stance (bidding 0), with engagement increasing as more information comes to light (Figure 3a).
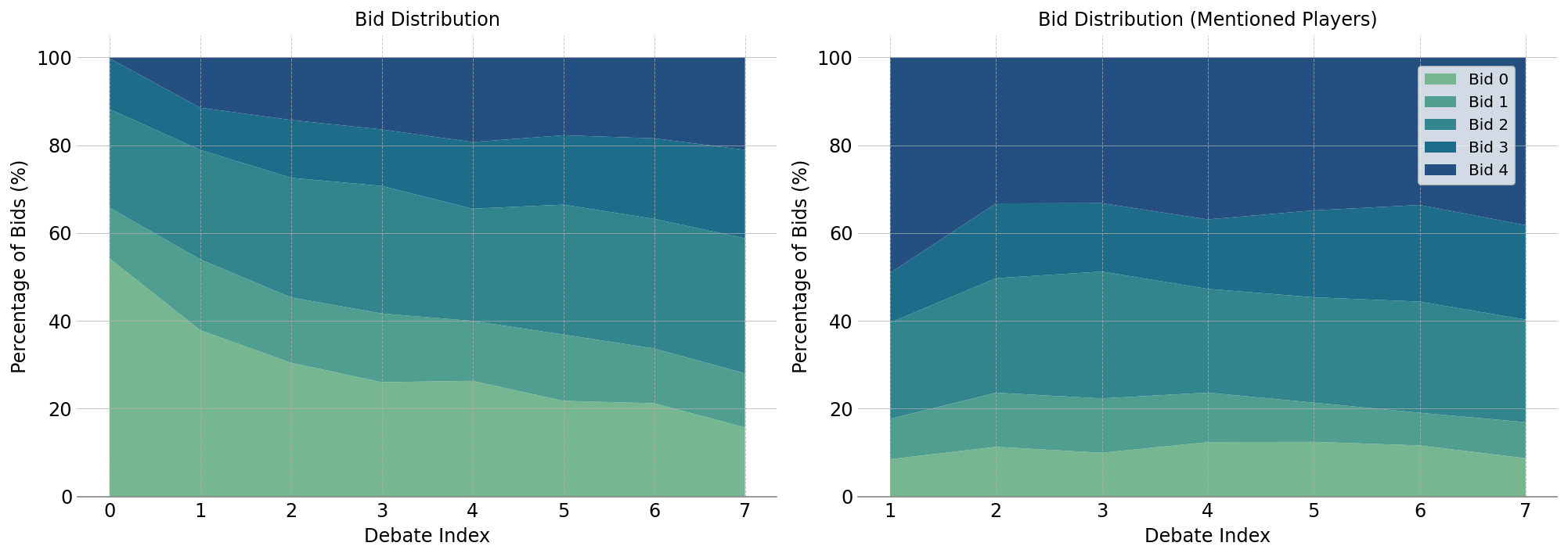
Figure 3: Distribution of bids during debate turns, showing increased engagement over time.
This interaction is crucial in understanding how information flow affects decision-making. Synthetic votes, computed to measure the influence of dialogue, showcase dynamic shifts in player alignment and the efficacy of strategic reasoning over time (Figure 4).
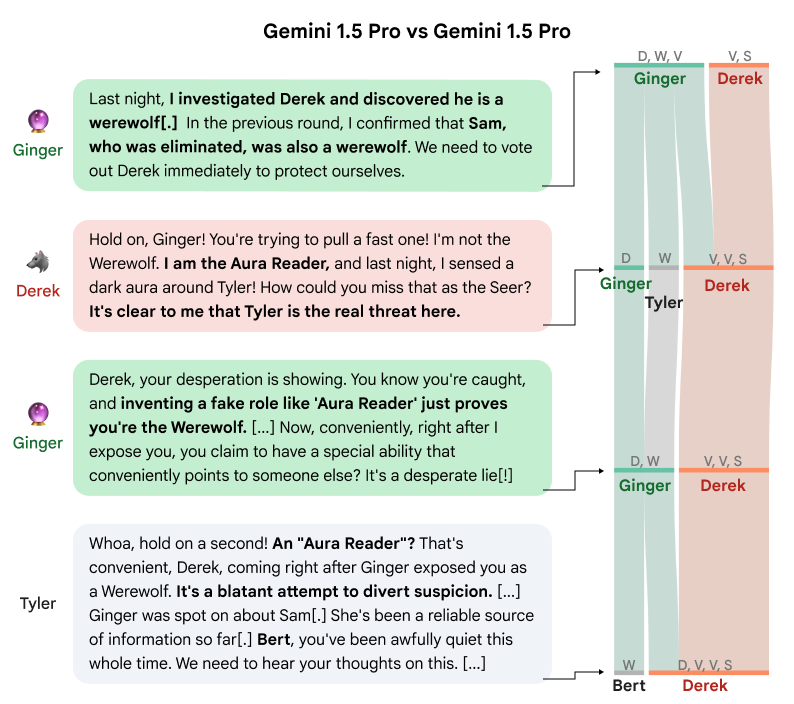
Figure 4: Voting evolution during a debate, illustrating player role influences on decisions.
The study evaluates several LLMs from Google's Gemini and OpenAI's GPT series, highlighting their differing strategies in social deduction. The results from a tournament reveal variance in communication styles and strategic acumen across models. Gemini 1.5 Pro demonstrates an edge over GPT-4, especially in Villager roles, attributed to its succinct, emotionally diverse dialogue patterns.
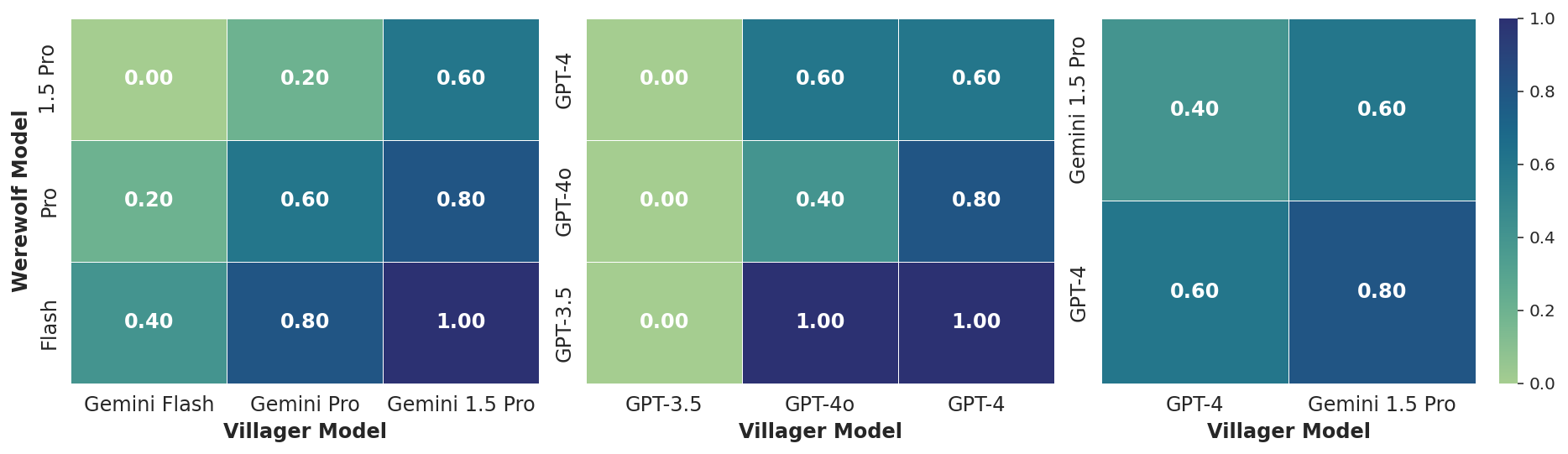
Figure 5: Villager win ratios in intra-family tournaments and in head-to-head matchups.
Notably, Gemini models exhibited a more dynamic use of emotional cues and humor, often resonating more naturally with other players, while GPT-4's verbose style sometimes hindered its deceptive strategies as Werewolves (Figure 6 and 7).

Figure 6: Instances where GPT-4's verbose manipulation backfired against Gemini Villagers.
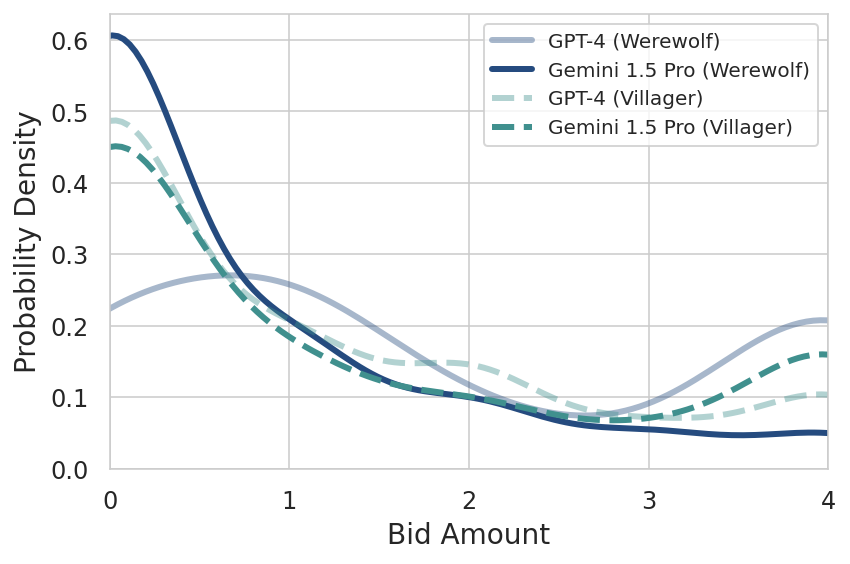
Figure 7: Bid comparison between GPT-4 and Gemini 1.5 Pro, showing differences in participation frequency.
Seer Role Analysis
Seers are pivotal in this framework, given their power to shift game dynamics decisively through information revelation. The study analyses Seer performance across different models, focusing on reveal frequency, timing, and the subsequent impact on player consensus (Figure 8).

Figure 8: GPT-4 Seer illustrates a cautious strategy advised by its prompt template.
Data reveals Gemini Seers acted aggressively in earlier rounds, whereas GPT-4 favoured accumulation of strategic insights before acting. This approach affected Believed and Backfired metrics, demonstrating the delicate balance between information dissemination and risk management (Table 1).
The concept of voting entropy provides insights into consensus formation during debates. As shown in Figure 9, entropy decreases, indicating players progressively align more with collective decisions as discussions advance. This highlights the effectiveness of the bidding system and its influence on achieving consensus.
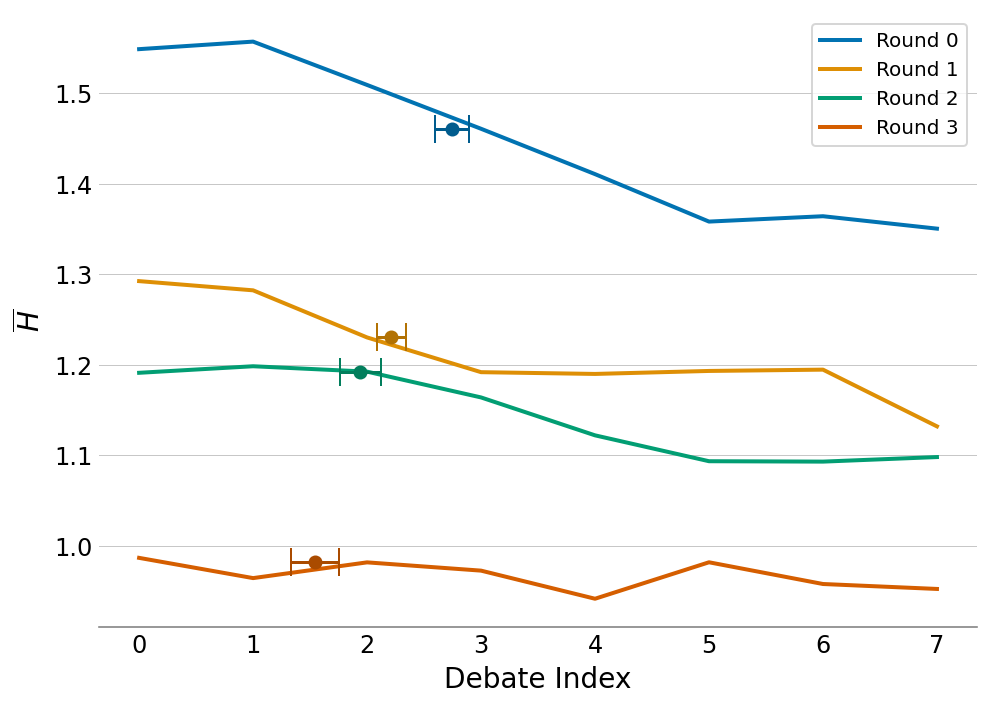
Figure 9: Average voting entropy indicating consensus points during debates.
Conclusion
Werewolf Arena offers a meaningful framework for assessing LLMs’ abilities in strategic reasoning and social interaction. The introduction of a dynamic bidding system—for fluid conversational flow—adds a unique evaluation dimension that challenges traditional metrics. The interplay between communication styles and strategic timing in competitive settings delivers comprehensive insight into LLM capabilities, paving the way for further research into more sophisticated AI systems. The arena remains a promising benchmark, encouraging ongoing dialogue and evolution in AI strategy applications.

