- The paper introduces AdaDec, an adaptive decoding framework that uses Shannon entropy to pause and rerank, reducing semantic errors in code generation.
- The study shows that high token uncertainty correlates with logic drift at various code positions, enabling targeted interventions during decoding.
- Experimental results demonstrate significant Pass@1 improvements across benchmarks with only a 7.59% pause rate, balancing accuracy and efficiency.
Adaptive Decoding with Uncertainty Guidance for Code Generation
Overview of the Paper
The paper "Towards Better Code Generation: Adaptive Decoding with Uncertainty Guidance" (2506.08980) addresses challenges in code generation using LLMs, specifically focusing on the decoding process that converts learned representations into executable code. Conventional decoding strategies such as greedy decoding do not account for the high-uncertainty decision points that can lead to semantic errors in code. This paper introduces AdaDec, an adaptive framework using model-specific uncertainty thresholds and a lookahead-based pause-and-rerank mechanism to improve code generation accuracy.
AdaDec targets high-uncertainty steps by employing Shannon entropy as a metric to dynamically pause decoding and rerank candidate tokens only when necessary. This selective approach reduces computational overhead and improves efficiency. Significant improvements are reported across different LLMs and benchmark datasets, demonstrating AdaDec's effectiveness compared to prior adaptive decoding strategies like AdapT.
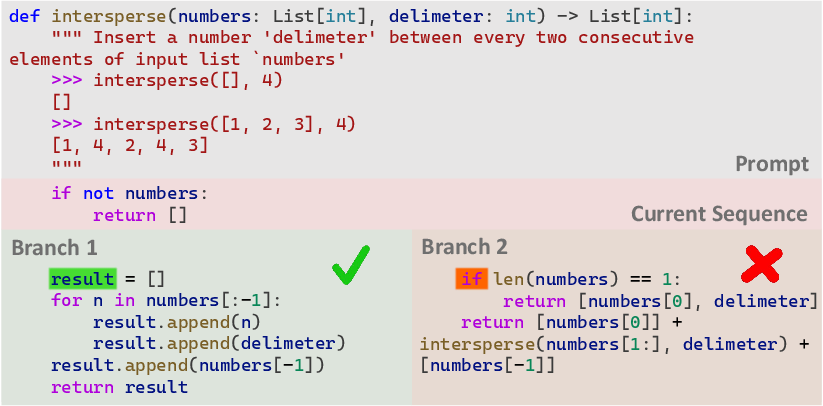
Figure 1: Illustration of irreversible semantic errors in code due to high-uncertainty points.
Empirical Analysis of Token Uncertainty
The paper conducts an empirical study to analyze token-level uncertainty during the decoding process. Token misranking at high-uncertainty positions often results in logic drift, suggesting that Shannon entropy can serve as an effective signal for detecting such errors. Two key findings emerge:
- Location of Logic Drifts: Most logic drift points occur at the beginning of a line, although a significant portion also occurs within lines. Therefore, interventions should focus on a broader range of tokens rather than just line-initial tokens.
- Entropy and Drift Points: Statistical analysis shows that drift points are associated with high entropy values, indicating a strong correlation between Shannon entropy and the likelihood of misranking tokens.
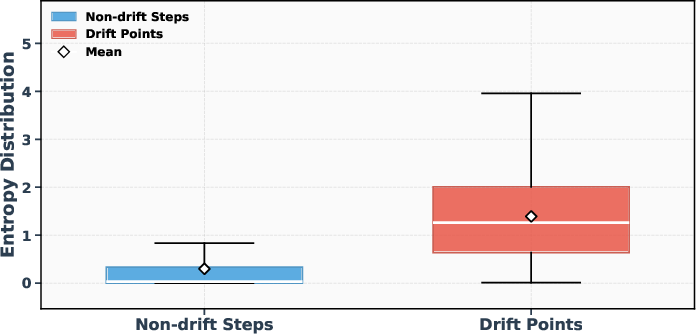
Figure 2: Entropy comparison between drift points and non-drift decoding steps.
AdaDec Framework
AdaDec incorporates a pause-then-rerank mechanism triggered by uncertainty signals indicated by Shannon entropy. When entropy exceeds a learned threshold, decoding pauses to rerank candidates using a lookahead scoring strategy inspired by A* search heuristics. The logistic regression approach to threshold learning enhances adaptability across different model types.
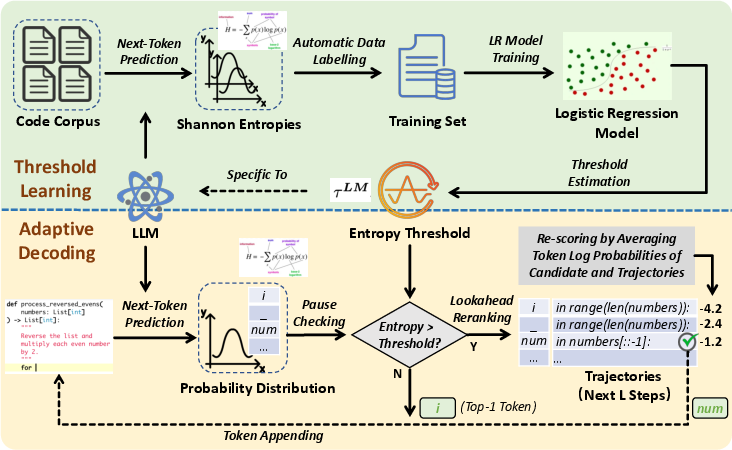
Figure 3: Approach Overview of AdaDec.
The lookahead mechanism evaluates candidate continuations based on token probabilities over a specified length, balancing immediate likelihood with expected future trajectory quality. This ensures that token selection incorporates both local coherence and longer-term sequence predictions.
Experimental Results
AdaDec is benchmarked on HumanEval+, MBPP+, and DevEval datasets, showing substantial gains in Pass@1 accuracy across several LLMs. The framework consistently outperforms greedy decoding and the AdapT method, underscoring the reliability of uncertainty-guided strategies in code generation.
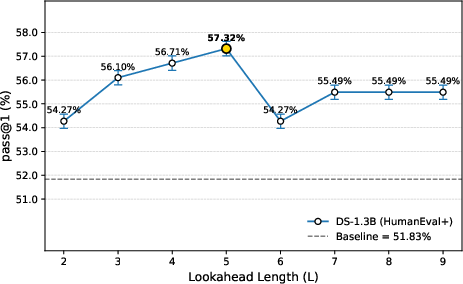
Figure 4: Pass@1 Performance of the DS-1.3B Model on the HumanEval+ Dataset Under Different Lookahead Length (L) Configurations.
Despite introducing additional latency during reranking, AdaDec maintains efficiency via selective intervention at high-uncertainty points, with pause rates averaging 7.59%. This balance between computational cost and performance improvement is critical for large-scale code generation applications.
Conclusion and Implications
AdaDec demonstrates the value of adaptive decoding frameworks that leverage token uncertainty for improving code generation accuracy. The paper's empirical findings on token uncertainty and its integration into decoding create pathways for further research into uncertainty modeling and dynamic thresholding mechanisms. Enhancements in token-level uncertainty modeling can substantially benefit not only code generation tasks but also broader LLM applications where precision and fidelity are paramount.
This work opens avenues for future exploration into richer uncertainty signals and adaptive strategies in LLM-based text generation contexts beyond code, hinting at broader applicability across diverse language modeling tasks.