The End of Manual Decoding: Towards Truly End-to-End Language Models
Abstract: The "end-to-end" label for LLMs is a misnomer. In practice, they depend on a non-differentiable decoding process that requires laborious, hand-tuning of hyperparameters like temperature and top-p. This paper introduces AutoDeco, a novel architecture that enables truly "end-to-end" generation by learning to control its own decoding strategy. We augment the standard transformer with lightweight heads that, at each step, dynamically predict context-specific temperature and top-p values alongside the next-token logits. This approach transforms decoding into a parametric, token-level process, allowing the model to self-regulate its sampling strategy within a single forward pass. Through extensive experiments on eight benchmarks, we demonstrate that AutoDeco not only significantly outperforms default decoding strategies but also achieves performance comparable to an oracle-tuned baseline derived from "hacking the test set"-a practical upper bound for any static method. Crucially, we uncover an emergent capability for instruction-based decoding control: the model learns to interpret natural language commands (e.g., "generate with low randomness") and adjusts its predicted temperature and top-p on a token-by-token basis, opening a new paradigm for steerable and interactive LLM decoding.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
When we ask a LLM to write or solve something, its final wording depends a lot on “decoding settings” such as temperature and top‑p. Think of these like two knobs: one controls how adventurous the model is (temperature), and the other controls how many likely choices it keeps in mind (top‑p). Today, people usually set these knobs by hand, and they use the same settings for an entire answer. That’s slow, fussy, and often not ideal, because different moments in a single answer may need different levels of creativity or caution.
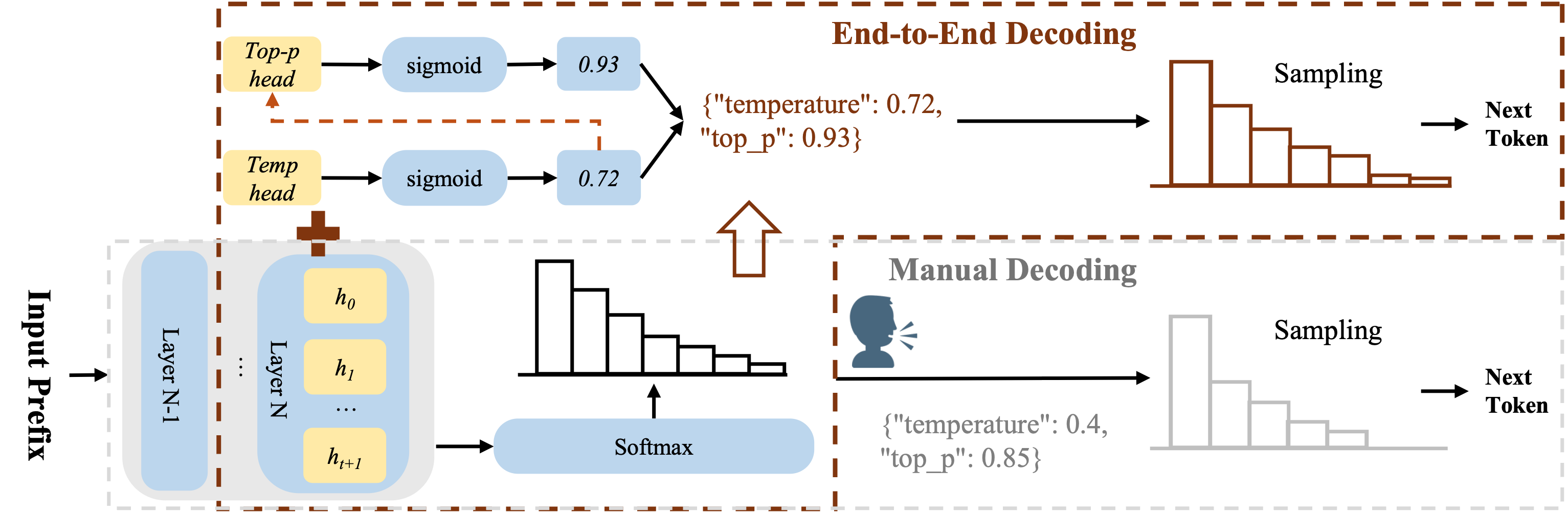
This paper introduces AutoDeco, a way for the model to control those knobs by itself, step by step, as it writes. The model adds two tiny “helper heads” that look at its current internal state and predict the best temperature and top‑p for the very next token. This makes text generation truly end‑to‑end: the model decides both what to say and how to say it, on the fly, without human trial‑and‑error.
What questions were the researchers trying to answer?
- Can an LLM learn to set its own decoding knobs (temperature and top‑p) for each token, even though there’s no “correct label” that tells us the perfect values?
- Can this self‑control be added without slowing generation down?
- Will this dynamic decoding actually beat common static settings, and even come close to the best possible hand‑tuned settings?
- Can the model react to plain-English instructions like “be less random” and adjust those knobs in real time?
How did they do it?
First, a quick explainer:
- Temperature: Higher temperature = more randomness and creativity; lower temperature = safer, more predictable choices.
- Top‑p (also called “nucleus sampling”): The model keeps just enough likely options to reach a chosen probability mass p (for example, 0.9), and ignores the rest. It’s like keeping only the most plausible words until you’ve covered 90% of the probability.
What AutoDeco adds:
- Two small prediction heads (tiny neural networks) are attached to the LLM. At each step of writing, these heads look at the model’s hidden state (its current “thoughts”) and predict the best temperature and top‑p for the next token. This happens inside the normal forward pass, so it’s fast.
The training trick:
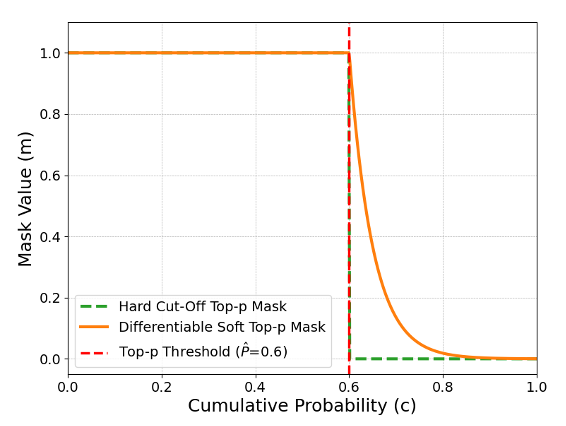
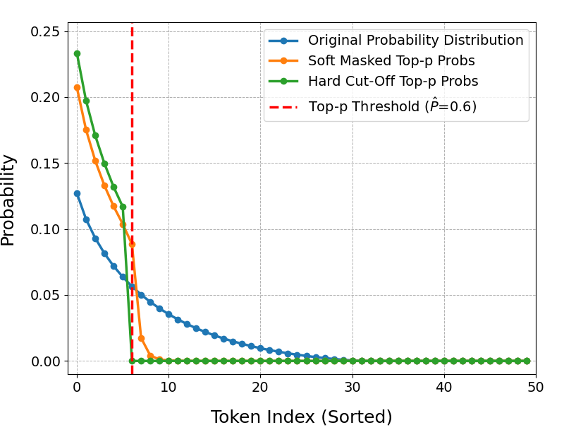
- The normal top‑p method uses a hard cutoff (everything outside the nucleus is dropped), which blocks gradients and makes learning hard.
- The authors replace that hard cutoff with a smooth, “soft top‑p” during training. Imagine a dimmer switch instead of a light switch: tokens outside the nucleus aren’t instantly thrown away—they’re smoothly faded out. Because this is smooth, gradients can flow, so the model can learn which temperatures and top‑p values help it predict the right next token.
- They freeze the base LLM and only fine‑tune the two helper heads for a short time. To avoid bad habits:
- They mask out many “easy” tokens where the base model already does great, so the heads learn more from tricky parts.
- They reweight learning so the model doesn’t overreact with huge temperatures on uncertain tokens.
Inference (using the model):
- During generation, for each token the LLM: 1) computes its hidden state, 2) the helper heads predict temperature and top‑p for that moment, 3) those values are used immediately to shape the next-token probabilities.
- This adds only about 1–2% extra time and barely any extra memory, so it remains practical.
What did they find, and why is it important?
Across eight benchmarks and several model families (including Llama, Qwen, and GPT-style models), AutoDeco:
- Consistently beats common defaults like Greedy Search and “Temperature=1, Top‑p=1.”
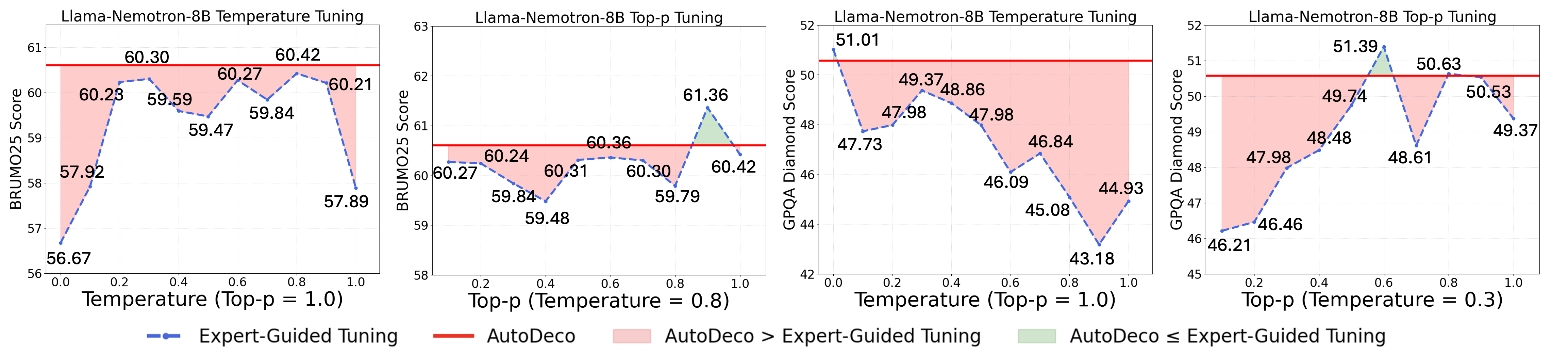
- Performs about as well as an “oracle-tuned” baseline where someone cheats by picking the best static settings after seeing the test set. In real life you can’t do that, so getting near that level without cheating is a big deal.
- Generalizes beyond math (where it was trained) to other areas like general question answering, code, and instruction following—showing the idea is broadly useful.
- Stays efficient: about 1–2% extra latency, tiny memory increase, and essentially the same FLOPs.
- Works even if you use only one head (just temperature or just top‑p): each alone gives solid gains, and using both together is best.
- Improves not only “best of 1” answers but also higher “best of k” settings (like pass@16 or pass@64), where the relative error reduction can be even bigger.
A surprising bonus: With simple instructions like “make the output less random,” the model lowers its predicted temperature and top‑p during writing. After a small amount of targeted training, this behavior becomes reliable, meaning the model can be steered in natural language to be more or less creative on the fly.
What does this mean for the future?
AutoDeco moves LLMs closer to being truly end‑to‑end: instead of humans fiddling with global knobs and hoping for the best, the model adjusts itself moment by moment. That means:
- Less manual tuning for developers.
- More consistent quality across different tasks and phases of an answer (explore early, be precise at the end).
- A new, intuitive way to steer output with plain-English instructions about style (like “high diversity” or “low randomness”).
The authors plan to go further by training the base model and the helper heads together. That could make instruction-based control even more precise and unlock finer control over style, creativity, and reliability—all without slowing generation down.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored, framed to guide follow-up research:
- Scope of controllable decoding: Only temperature and top-p are learned; no exploration of other widely used controls (e.g., top-k, frequency/presence penalties, repetition penalties, length penalties, bad-words constraints, beam/contrastive/diverse decoding, logit bias). What additional controls provide the largest marginal gains when learned dynamically?
- Training–inference mismatch: The heads are trained with a differentiable “soft” top-p but inference appears to use standard (hard) nucleus filtering. What is the impact of this mismatch on stability and final accuracy, and does replacing hard top-p at inference with the soft variant help or hurt?
- Differentiability assumptions: The training pipeline depends on sorting and cumulative sums to build the nucleus, operations that are only piecewise differentiable. How sensitive is learning to this approximation (e.g., under near-ties)? Are there lower-variance or provably unbiased gradient estimators for nucleus selection?
- Sensitivity to soft top-p steepness: No ablation on the decay parameter α that controls mask sharpness. What α schedules (or learnable α) yield the best trade-off between gradient quality and faithfulness to hard top-p?
- Objective misalignment: The heads are trained via token-level cross-entropy under teacher forcing, while evaluation uses sampled long-form generation. Does optimizing sequence-level metrics (e.g., pass@1/pass@k, reward-model scores) via RL or off-policy learning on reject-trajectory data outperform CE-only training?
- Exposure bias for control heads: Because the base model is frozen and training is on ground-truth continuations, predicted decoding parameters may not reflect the distributions encountered during sampling. Can on-policy training or mixed teacher-forcing + sampled targets reduce this bias?
- Data/domain bias: Heads are trained on math reject trajectories (DeepMath-103K) from four models. How do results change with multi-domain, multi-task training (e.g., dialogue, summarization, translation, safety), and with multilingual data?
- Missing multilingual evaluation: All reported results appear to be in English. Do dynamic decoding policies transfer to non-English inputs and multilingual LLMs?
- Lack of safety/factuality analysis: Increasing per-token stochasticity can amplify hallucinations or toxicity. How do dynamic parameters affect factuality (e.g., TruthfulQA, FactScore), toxicity, bias, and safety guardrail adherence?
- Vulnerability to adversarial control: Natural-language “make it more random” commands could be exploited to bypass safety or consistency. What guardrails or privilege controls are needed to prevent prompt-based manipulation of decoding parameters?
- Precision of instruction-based control: The model responds directionally to “high/low diversity” commands but lacks fine-grained or numeric control. Can training achieve calibrated targets (e.g., “temperature 0.35”), and can absolute control be verified reliably?
- Interpretability of learned policies: When and why does the model raise or lower temperature/top-p (e.g., early exploration vs final-answer consolidation, high-entropy contexts, token difficulty)? Provide quantitative analyses linking predictions to entropy, position, uncertainty, or content type.
- Missing baselines for adaptive decoding: No comparison to simple dynamic heuristics (e.g., entropy-based temperature scaling, linear or cosine temperature schedules, per-step top-p schedules) or recent adaptive methods (e.g., Latent Preference Optimization for decoding). Do learned heads still outperform strong hand-crafted dynamic schedules?
- Architectural alternatives: The top-p head conditions on predicted temperature; no ablation isolates this dependency. Is the coupling necessary or optimal, and do shared or per-layer heads improve results?
- Extensibility beyond final hidden state: Only the final token representation is used. Would incorporating additional features (e.g., token position, historical entropy, logits dispersion, verifier scores) or multi-layer signals yield stronger control?
- Interaction with other decoding algorithms: Compatibility and performance are untested with contrastive decoding, speculative decoding, grammar-constrained decoding, or tool-calling pipelines. Do dynamic T/P help or interfere with these methods?
- Inference-system coverage: Overhead is measured on a single stack/model (R1-Distill-Qwen-7B) and modest context lengths (≤24k). What happens under high-throughput batched serving, streaming, multi-GPU inference, vLLM/TensorRT-LLM backends, very long contexts (≥1M tokens), and heterogeneous hardware?
- Large-model validation: Heads are released for ≥100B-scale models but not evaluated. Do gains, overhead, and control fidelity persist (or improve) at frontier scales?
- Sample efficiency and compute trade-offs: Appendix reports pass@k, but there is no analysis of sample efficiency (accuracy per unit compute, tokens-to-correct) or how dynamic decoding changes solution lengths, verbosity, or chain-of-thought structure.
- Calibration and uncertainty: Dynamic temperature scaling likely affects probability calibration. What is the effect on ECE/Brier/token-level calibration, and can calibration-aware training improve both accuracy and uncertainty estimates?
- Robustness to distribution shift and noise: No tests with adversarial/noisy prompts, domain drift, or instruction conflicts. How stable are T/P predictions under stress, and can robustness be improved (e.g., via adversarial training)?
- Range constraints and regularization: The mapping and ranges for temperature/top-p are not fully specified. How are bounds enforced, and how sensitive are results to range/regularization choices (e.g., clipping vs squashing transforms)?
- Cross-model transfer: Heads are trained per base model. Can a decoding controller trained on one backbone transfer to others (same/different families, sizes), or be trained as a universal plug-in?
- Production considerations: A “1-line change” claim may not hold across serving stacks where decoding is external to the model forward pass. What is required for seamless adoption in common inference libraries and hosted services?
- Theory and guarantees: The paper posits a “meta-skill of how to generate” but provides no theoretical account of when dynamic decoding helps or harms. Can we formalize conditions under which adaptive stochasticity improves sequence-level objectives?
Glossary
- AutoDeco: A proposed architecture that lets an LLM learn and control its own decoding parameters dynamically during generation. "This paper introduces AutoDeco, a novel architecture that enables truly “end-to-end” generation by learning to control its own decoding strategy."
- Beam Search: A deterministic decoding algorithm that keeps the top-k partial sequences at each step to explore a larger search space. "Another classic one is beam search, which maintains a “beam” of k most probable partial sequences to explore a larger search space"
- Calibrated Uncertainty: A modeling notion where uncertainty estimates are used judiciously to adjust behavior (e.g., temperature) rather than reacting to outliers. "This teaches the head to apply high temperatures more judiciously in situations of calibrated uncertainty, rather than being skewed by outlier signals."
- Contrastive Decoding: A method that steers a larger model away from generic text using a smaller guidance model. "More recently, Contrastive Decoding uses a smaller “amateur” model to steer a larger “expert” model away from generic text"
- Contrastive Search: A deterministic decoding technique that penalizes repetitions and overly similar tokens to improve open-ended text quality. "A more recent line of deterministic methods, Contrastive Search\citep{su2022contrastive, su2022}, directly optimizes for open-ended generation quality by penalizing tokens that are too similar to previous tokens, effectively mitigating the degeneration problem."
- Cross-Entropy Loss: A standard objective for training probabilistic models by comparing predicted distributions with ground-truth labels. "A natural approach would be to optimize the temperature and top-p heads directly from the final cross-entropy loss of the generated tokens."
- Dynamic Fine-Tuning: A training approach that re-weights losses to focus on tokens with reliable prior signals, improving robustness. "We incorporate Dynamic Fine-Tuning ~\citep{wu2025generalizationsftreinforcementlearning}, which re-weights the training loss to focus on tokens where the model has a reasonable prior."
- Easy-Token Masking: A debiasing training trick that down-weights or masks loss on positions where the base model already predicts the correct token greedily. "Easy-Token Masking. For many tokens, the base model's greedy prediction already matches the ground-truth."
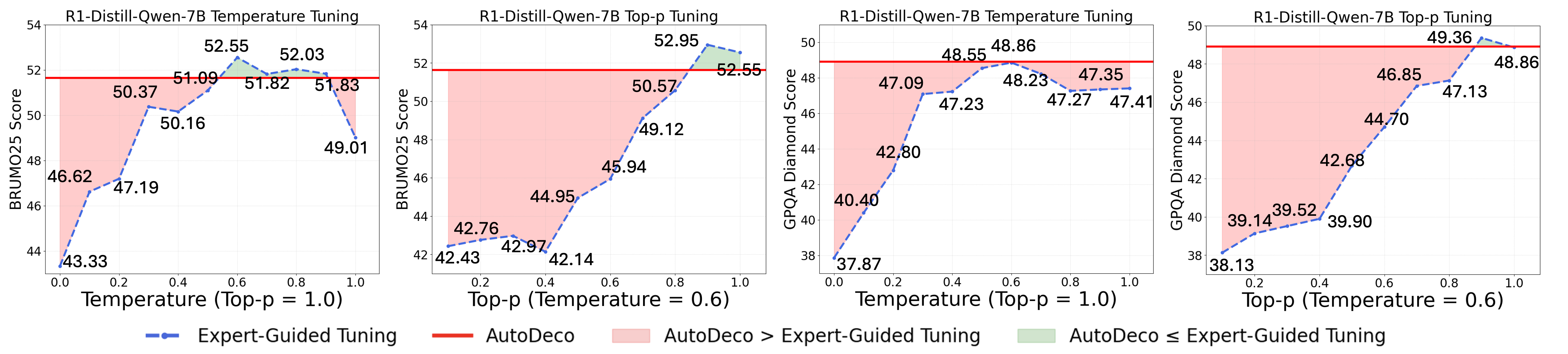
- Expert-Guided Tuning: A baseline that finds optimal static decoding parameters via exhaustive search, often unrealistically using test-set information. "we also compare against an Expert-Guided Tuning."
- FLOPs: A measure of computational cost (floating-point operations) used to assess efficiency. "The FLOPs are virtually identical to the baseline, and the memory footprint increases by a mere 4 MB"
- Forward Pass: The computation that maps inputs through the model to outputs without backpropagation, used here to predict both logits and decoding parameters. "allowing the model to self-regulate its sampling strategy within a single forward pass."
- Greedy Search: A deterministic decoding method that selects the single highest-probability token at each generation step. "The most fundamental of these is Greedy Search, which selects the token with the highest probability at each step."
- Hidden State: The internal representation produced by the model at each token step, used to predict decoding parameters. "At each decoding step, these AutoDeco heads leverage the model's current hidden state to dynamically predict the optimal sampling parameters for the next token."
- Instruction-Based Decoding Control: The capability to interpret natural language commands to adjust decoding parameters like temperature and top-p on the fly. "Crucially, we uncover an emergent capability for instruction-based decoding control: the model learns to interpret natural language commands (e.g., “generate with low randomness”)"
- Latency: The time delay introduced by computation; here, the overhead added by AutoDeco during inference. "This architecture results in a negligible latency overhead, typically adding only 1-2% to the total generation time."
- lm_head: The final linear layer that projects hidden states to logits over the vocabulary. "In parallel, the standard lm_head computes the logits while the AutoDeco heads predict the dynamic parameters."
- Logits: Unnormalized scores over the vocabulary that are transformed into probabilities during decoding. "we augment the standard transformer with lightweight heads that, at each step, dynamically predict context-specific temperature and top-p values alongside the next-token logits."
- Mixture-of-Experts (MoE): A model architecture that routes inputs among multiple expert subnetworks to improve capacity and efficiency. "An advanced MoE architecture instruct model from Qwen3."
- Non-differentiable: Operations that do not allow gradients to be computed for optimization, breaking end-to-end training. "Its “hard cutoff”—retaining only the smallest set of tokens whose cumulative probability exceeds a threshold—is a non-differentiable operation"
- Nucleus Sampling (Top-p): A stochastic truncation strategy that samples from the smallest set of tokens whose cumulative probability exceeds p. "Nucleus Sampling (top-p)\citep{holtzmancurious} selects the smallest set of tokens whose cumulative probability exceeds a threshold p."
- Oracle-Tuned Baseline: A benchmark using hyperparameters tuned with test-set access, representing an unrealistically strong static method. "achieves performance comparable to an oracle-tuned baseline derived from “hacking the test set”—a practical upper bound for any static method."
- Oversampling: Drawing many samples per instance to estimate metrics like Pass@1 more reliably. "Pass@1 accuracy, estimated via oversampling with 128 samples per problem"
- Pass@1 Accuracy: The probability that at least one of the generated outputs (with one sample) is correct. "Pass@1 accuracy, estimated via oversampling with 128 samples per problem"
- Pass@: The probability that at least one of k samples contains a correct answer; used to assess sampling performance. "pass@ ()"
- Plug-and-Play LLMs: A method that uses attribute models to steer generation toward desired properties without retraining the main model. "Early examples include Plug-and-Play LLMs, which leverage attribute models to steer generation towards desired topics"
- Ranking Loss: A loss that encourages ordered preferences (e.g., higher temperatures under “high diversity” commands than baseline). "We developed a targeted training strategy, augmenting a subset of prompts with diverse “decoding-control commands” and applying a ranking loss."
- ReLU: A non-linear activation function whose value is zero for negative inputs; here used in a differentiable top-p mask. "this formulation ensures that for tokens inside the nucleus (where ), the ReLU term is zero"
- Reject Sampling: A data-generation process where sampled outputs are filtered (rejected) based on criteria, producing trajectories for training. "The AutoDeco heads are trained on a specialized dataset of reject sampling trajectories."
- Soft Top-p: A differentiable approximation to top-p truncation that smoothly decays probabilities beyond the threshold, enabling end-to-end training. "we introduce a novel, differentiable “soft” top-p mechanism that is used during training"
- Speculative Decoding: An acceleration technique where a faster draft model proposes tokens that a larger model then verifies. "Similarly, Speculative Decoding utilizes a faster “draft” model to generate sequences of tokens that are then verified by the larger model"
- Temperature-Scaled Probabilities: Adjusting logits by a temperature parameter before softmax to control randomness. "Temperature-Scaled Probabilities: First, we scale the predicted logits to compute the initial probability distribution using the predicted temperature ."
- Top-k Sampling: A truncation method that restricts sampling to the k most probable tokens. "Top-K sampling\citep{fan2018hierarchical} restricts the sampling pool to the most likely tokens"
- Top-p Sampling: A truncation method that selects tokens until their cumulative probability reaches p, with hard cutoff in standard form. "Traditional top-p sampling methods assign a probability of zero to all tokens beyond the top-p threshold"
- Verification Methods: Techniques for checking or validating generated content or proposals during decoding. "There is also an art to verification methods~\citep{liu2025trust}."
Practical Applications
Overview
This paper introduces AutoDeco: lightweight prediction heads added to transformer LLMs that dynamically estimate token-level decoding parameters (temperature and top‑p) during generation. A differentiable “soft” top‑p enables end‑to‑end training of these heads, and the approach yields consistent improvements across math, QA, code, and instruction-following benchmarks with only ~1–2% latency overhead. AutoDeco also exhibits an emergent ability to follow natural-language commands that steer decoding (e.g., “low diversity”), hinting at a new class of user-controllable, end‑to‑end generation systems.
Below are practical applications derived from the paper’s findings, methods, and innovations.
Immediate Applications
The following applications can be implemented with the released code/models and existing inference stacks, typically via a minor integration (e.g., a “1‑line change”) and brief fine‑tuning of AutoDeco heads.
- Auto-decoding for LLM APIs and platforms
- Sector: software, cloud platforms
- Application: Replace static decoding defaults with AutoDeco-enabled dynamic decoding to automatically adapt randomness per token and per prompt, removing laborious manual sweeps of temperature/top‑p.
- Tools/products/workflows: “Decoding-as-a-Plugin” for vLLM/TGI/Hugging Face; an SDK that provides drop‑in AutoDeco heads for supported model families (Llama, Qwen, GPT‑OSS).
- Assumptions/dependencies: Requires integration into inference server; minor latency budget (~1–2%); brief fine‑tuning of heads on in-domain trajectories.
- Enterprise chatbot reliability hardening
- Sector: customer support, enterprise IT
- Application: Dynamically lower randomness in sensitive phases (policy explanations, billing adjustments) and allow higher diversity in empathetic conversational segments; increase Pass@1 for task-critical responses.
- Tools/products/workflows: Policy-aware decoding wrapper that maps intent segments to natural-language “low randomness” control prompts or explicit decoding toggles.
- Assumptions/dependencies: Domain prompts may be shorter (benefit smaller); requires intent classification to trigger control phrases.
- Coding assistants with staged exploration/exploitation
- Sector: developer tools
- Application: Use high temperature/top‑p during ideation (candidate solutions) and suppress randomness when finalizing code blocks or test cases; improve code correctness without losing creativity.
- Tools/products/workflows: IDE plugin that logs and visualizes token-level temperature/top‑p traces; CI-integrated “deterministic finalization.”
- Assumptions/dependencies: Gains depend on longer reasoning traces; baseline model’s coding quality still governs results.
- Retrieval-augmented generation (RAG) answer hygiene
- Sector: enterprise search, knowledge management
- Application: Reduce hallucination risk by lowering temperature when citing facts and raising it for paraphrase/summarization components.
- Tools/products/workflows: RAG pipeline adapter that automatically switches decoding strategy based on retrieval confidence scores.
- Assumptions/dependencies: Requires access to retrieval confidence/score signals; careful calibration to avoid over-determinism.
- Tuneless prompt engineering
- Sector: content creation, marketing
- Application: Replace manual temperature/top‑p tuning with natural-language directives (“be safe,” “be more novel”) to steer style; consistent with observed 95%+ directional control after targeted training.
- Tools/products/workflows: UI “certainty/creativity” sliders mapped to meta-commands; analytics to track average predicted T/p changes.
- Assumptions/dependencies: Paper notes limited absolute control without joint training; targeted fine‑tuning improves consistency.
- Automated A/B testing elimination for decoding
- Sector: MLOps, model evaluation
- Application: Stop exhaustive grid searches across temperature/top‑p; AutoDeco learns per-token decoding strategy that approximates oracle-tuned static settings.
- Tools/products/workflows: Evaluation harness with AutoDeco logs; benchmarking dashboards for Pass@k tracking.
- Assumptions/dependencies: Requires collecting reject-sampling trajectories or reusing provided datasets; may keep a fallback static configuration.
- Task-agnostic assistant deployment across domains
- Sector: horizontal LLM deployment (HR, finance ops, procurement)
- Application: Single model that adapts decoding to user queries (math, QA, policy text, summaries) without per-task parameter switching.
- Tools/products/workflows: “One-model-many-tasks” service using AutoDeco as default decoder.
- Assumptions/dependencies: Generalization shown despite math-only training, but benefits vary by task length and base model.
- Safety-aware generation guardrails
- Sector: trust & safety, compliance
- Application: Reduce randomness when safety detectors (PII, toxicity, ungrounded claims) fire; higher determinism for compliance‑critical outputs.
- Tools/products/workflows: Safety middleware that programmatically injects “low diversity” commands at runtime.
- Assumptions/dependencies: Requires robust detectors; need logging for auditability of decoding parameter traces.
- Academic reproducibility and analysis tooling
- Sector: academia, research
- Application: Record token-level temperature/top‑p predictions to study exploration/exploitation dynamics and decoding’s effect on Pass@k.
- Tools/products/workflows: Instrumentation library that exports parameter sequences; comparative studies with static baselines.
- Assumptions/dependencies: Must store traces to ensure reproducible runs; per-token control complicates deterministic reproduction unless seeded and logged.
- Domain-tailored heads via quick fine-tuning
- Sector: industry labs, consultancy
- Application: Train AutoDeco heads on domain-specific trajectories (legal drafting, healthcare summarization) to match oracle-like performance without test-set hacking.
- Tools/products/workflows: “Head fine‑tuning kit” with easy-token masking and dynamic fine‑tuning losses.
- Assumptions/dependencies: Needs domain trajectories and modest GPU time; frozen backbone can limit absolute control.
- Instruction-following reliability for evaluations
- Sector: education, assessments
- Application: Lower randomness for rubric-aligned answers; increase diversity for creative writing assignments.
- Tools/products/workflows: Evaluation system augmented with decoding control prompts per rubric item.
- Assumptions/dependencies: Instruction-following gains depend on prompt length and model family.
- Backend cost optimization (compute and human time)
- Sector: operations, finance
- Application: Reduce time spent on manual sweeps; near-baseline FLOPs and memory usage ensure predictable cost with small latency increase.
- Tools/products/workflows: Cost tracking dashboards showing reduced tuning cycles and improved first-pass accuracy.
- Assumptions/dependencies: The ~1–2% latency overhead must fit SLAs; expected improvements should justify integration effort.
Long-Term Applications
These applications require further research, scaling, or broader platform changes—often involving joint training of base LLMs with AutoDeco heads, extended control dimensions, or larger model evaluations.
- Jointly trained end-to-end controllable LLMs
- Sector: software, cloud platforms
- Application: Train base LLM + AutoDeco heads together to achieve precise absolute control over decoding via natural language (e.g., true “near‑zero randomness” on request).
- Tools/products/workflows: Integrated training pipelines; preference optimization combined with decoding-control losses.
- Assumptions/dependencies: Requires substantial compute; robust datasets for control commands; careful stability monitoring.
- Multi-parameter decoding control (beyond temperature/top‑p)
- Sector: LLM systems, research
- Application: Add heads for top‑k, beam size, repetition penalties, reasoning effort. Token-level control could regulate chain-of-thought length or tool-calling aggressiveness.
- Tools/products/workflows: “Decoding Control Suite” offering fine-grained sliders/API; per-step tool selection thresholds.
- Assumptions/dependencies: Non-differentiable operations may need new soft relaxations; user interfaces must prevent misconfiguration.
- Risk-aware “hallucination thermostat”
- Sector: healthcare, legal, finance, public sector
- Application: Continuously monitor factuality/risk signals and lower randomness mid-generation when risk spikes; log control decisions for audits.
- Tools/products/workflows: Compliance-grade observability; certified audit trails; policy engines mapping risk to decoding adjustments.
- Assumptions/dependencies: High-quality risk/factuality detection; regulatory acceptance of dynamic control mechanisms.
- Adaptive decoding in autonomous agents and robotics
- Sector: robotics, industrial automation
- Application: Modulate exploration/exploitation in language-driven planners (higher diversity for planning/search; low randomness for actuation commands).
- Tools/products/workflows: Agent frameworks with decoding governors; safety interlocks that clamp randomness on critical actions.
- Assumptions/dependencies: Reliable grounding and control; safety certification; integration with perception/action stacks.
- Personalized decoding profiles
- Sector: consumer apps, education, mental health support
- Application: Learn user-specific preferences for creativity vs certainty; adapt decoding automatically across tasks (study aids vs creative writing).
- Tools/products/workflows: Preference learning modules; profile-aware decoders; UI controls for per-user settings.
- Assumptions/dependencies: Privacy-preserving preference storage; fairness considerations; opt‑in mechanisms.
- Cross-model and MoE decoding orchestration
- Sector: large-scale LLM services
- Application: Coordinate decoding behavior across mixture-of-experts or multi-model ensembles; unify exploration/exploitation policies system-wide.
- Tools/products/workflows: Orchestration layer that harmonizes per-expert heads; dynamic routing informed by decoding signals.
- Assumptions/dependencies: Complex system integration; performance validation at scale.
- Decoding-aware RL training for reasoning models
- Sector: research, advanced model training
- Application: Integrate AutoDeco signals into RL reward shaping, teaching models when to explore vs exploit for higher Pass@k without sacrificing Pass@1.
- Tools/products/workflows: RL pipelines that log and optimize decoding parameters; curriculum strategies for difficult tokens.
- Assumptions/dependencies: Stable training objectives; high-quality reward models; extensive experimentation.
- Standardization and policy frameworks for steerable decoding
- Sector: policy, governance
- Application: Define guidelines on allowable user control of randomness in high-stakes settings; mandate logging of decoding parameters for audits.
- Tools/products/workflows: Industry standards; certification programs; compliance toolkits for parameter traceability.
- Assumptions/dependencies: Multi-stakeholder consensus; alignment with sector-specific regulations.
- Energy-efficient model operations via reduced tuning
- Sector: energy, sustainability, cloud operations
- Application: Lower energy usage by eliminating large-scale hyperparameter sweeps and reducing reruns; operationalize dynamic decoding to reduce trial-and-error compute.
- Tools/products/workflows: Sustainability metrics dashboards; cost–benefit analyses tied to reduced tuning cycles.
- Assumptions/dependencies: Organizational adoption; measurable baselines; data for before/after comparisons.
- Decoding analytics and interpretability dashboards
- Sector: MLOps, observability
- Application: Visualize token-level temperature/top‑p over time; correlate with errors, hallucinations, and user satisfaction; diagnose failure modes.
- Tools/products/workflows: Parameter tracing, alerts for anomalous decoding; model health reports.
- Assumptions/dependencies: Secure logging; performance impact must remain minimal; effective UX for complex signals.
Notes on Feasibility
- Integration effort is modest for supported model families, but inference server modifications may be needed.
- Benefits are strongest for tasks with multi-step or long-form generation; shorter prompts show smaller gains.
- The paper’s emergent natural-language control is directional and consistent after targeted training but not yet precise in absolute magnitude; joint training is the likely path to fine-grained control.
- Training heads requires domain trajectories; transfer across domains is promising but not guaranteed and should be validated.
- Safety-critical deployments must incorporate auditing of decoding parameters and policies to constrain user-driven randomness changes.
Collections
Sign up for free to add this paper to one or more collections.