- The paper introduces multicalibration techniques that enhance LLM confidence scores in predicting code correctness across varied benchmarks.
- It compares methods like IGLB and LINR against traditional calibration, achieving improvements up to 58.4% in prediction accuracies.
- Results highlight the importance of using code attributes such as complexity, length, and language for accurate uncertainty estimation.
Multicalibration for LLM-based Code Generation
The paper "Multicalibration for LLM-based Code Generation" (2512.08810) explores the concept of multicalibration in the context of LLMs for code generation. Given the increasing adoption of AI-generated code, it is crucial to ensure that confidence scores provided by code-generating LLMs accurately reflect the likelihood that the code is correct. This paper focuses on enhancing the calibration of LLM outputs by considering additional problem-specific attributes. The authors investigate four distinct multicalibration approaches, using factors related to code complexity, length, and the programming language employed, across various function synthesis benchmarks.
Introduction and Background
LLMs have revolutionized software development, enabling the rapid generation and modification of code. However, the reliability of these models remains a concern due to their probabilistic nature, which can lead to decreased code quality. Calibration and uncertainty estimation are two strategies intended to address these concerns. Calibration aims to ensure that a model's confidence score corresponds accurately to the actual likelihood of correctness. Uncertainty estimation identifies predictions that are less reliable, thereby streamlining code review processes. Nevertheless, much of the research in this area has focused on tasks other than code generation, such as natural language understanding.
The paper argues for a nuanced approach to the calibration of code LLMs based on multicalibration, a technique introduced by Hébert-Johnson et al. Multicalibration extends standard calibration to multiple intersecting groups, capturing a variety of nuanced factors such as code complexity and programming language. To the best of the authors' knowledge, this study is the first to apply multicalibration to code generation tasks. Several multicalibration approaches are evaluated, grouping coding exercises by metrics such as complexity, code length, and the programming language used.
Methodology and Approach
The study utilizes three state-of-the-art code LLMs: Qwen3 Coder, GPT-OSS, and DeepSeek-R1-Distill. The effectiveness of multicalibration is tested against traditional calibration methods like Platt Scaling and Histogram Binning. The paper focuses on deriving initial confidence metrics from token likelihoods and applies multicalibration by evaluating the models on datasets including the multilingual benchmarks MultiPL-E and McEval, as well as the LiveCodeBench dataset.
Initial confidence scores are computed as the average likelihood of generated tokens. Then, multicalibration is applied through methods like Group-Conditional Unbiased Regression (LINR, LOGR) and Iterative Grouped Linear Binning (IGLB). IGLB, in particular, proved robust in handling the intersecting groups of varying characteristics.
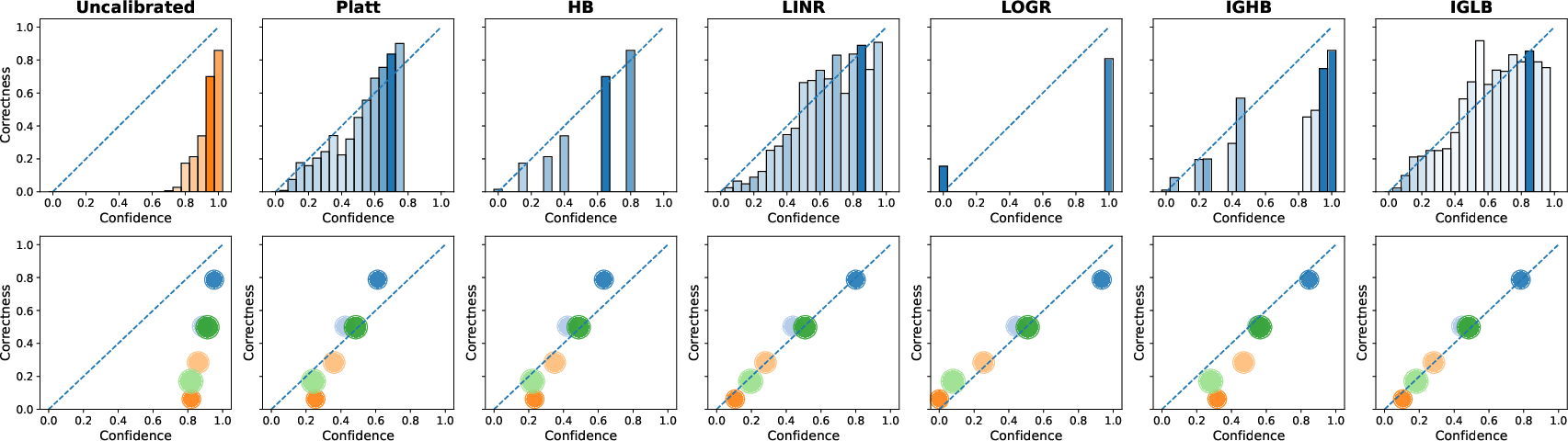
Figure 1: Top: Reliability diagrams for Qwen3 Coder on LiveCodeBench. Well-calibrated models fit the identity line, while deviations from the diagonal indicate miscalibration. Bin size is encoded by color intensity. Bottom: Mean predicted scores versus accuracies across clustered groups. LINR and IGLB achieve the best calibration.
Experimental Results
The experiments demonstrate that multicalibration can markedly enhance the calibration of LLMs. Specifically, in contrast to uncalibrated models, significant improvements were observed in distinguishing correct from incorrect code. Post-hoc calibration through traditional and multicalibration methods yielded accuracies ranging from 72.5% to 95.5% in various contexts, showcasing improvements of up to 58.4%.
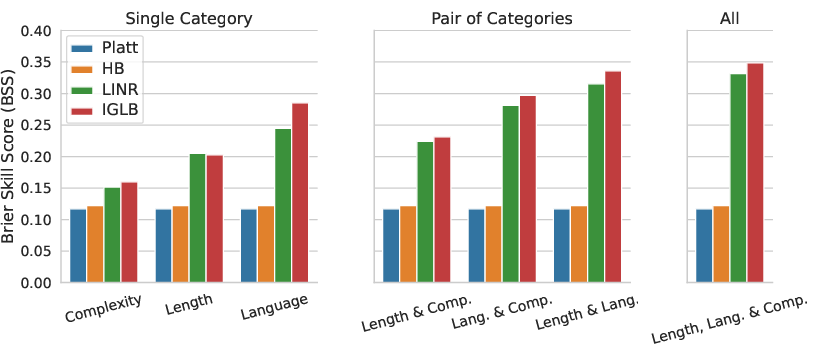
Figure 2: Ablation experiments evaluating different group combinations on McEval. Results are averaged over the three LLMs.
IGLB and LINR consistently achieved top performance, emphasizing the efficacy of multicalibrated models. Through the use of structured group information, these techniques significantly reduced calibration error and increased predictive accuracy. Ablation studies revealed that language and length were the most impactful groupings, demonstrating their complementary nature in improving calibration.
Conclusion and Future Work
The findings underscore the importance of considering additional attributes beyond raw token likelihoods for calibrating LLM-generated code. The paper introduces multicalibration as a promising avenue for enhancing confidence estimation in LLMs, thereby facilitating their adoption in real-world software development tasks.
Future research could extend these findings by exploring alternative initial scoring methods and wider applications such as repository-level code generation or program repair. By providing a rigorous methodological framework and open access to the dataset and code, the authors pave the way for continued exploration in this underserved but essential area.