- The paper introduces SE-Jury, an LLM-as-Ensemble-Judge metric that integrates diverse evaluation strategies to closely align with human judgment.
- It employs a dynamic team formation to select tailored evaluation strategies, optimizing both cost and performance across various software engineering tasks.
- Empirical results show significant improvements, with correlation gains up to 140.8% over traditional metrics, enhancing evaluations for code generation and repair.
An LLM-as-Judge Metric for Bridging the Gap with Human Evaluation in SE Tasks
In the pursuit of minimizing human involvement in evaluating software engineering (SE) tasks, the study introduces SE-Jury, an LLM-as-Ensemble-Judge metric designed to narrow the gap with human evaluations. This approach leverages various evaluation strategies to enhance accuracy in assessing the correctness of generated software artifacts. The discussion that follows elaborates on the framework's architecture, the diverse strategies it employs, and its empirical performance.
Introduction
With the increasing complexity in software generation tasks—ranging from code snippets to automated repairs and summarizations—the necessity for accurate, scalable evaluation mechanisms is paramount. Human evaluations, while accurate, are costly and time-consuming. Automatic metrics, though scalable, fail to achieve human-level understanding due to their reliance on syntactic similarity measures like BLEU or embedding-based assessments. SE-Jury is positioned to address these limitations by integrating multiple evaluation strategies that mimic a human-like understanding of correctness.
Framework of SE-Jury
The SE-Jury framework is architecturally inspired by legal tribunals that employ experts from various domains to reach a consensus. It consists of three core stages:
- Diverse Evaluation Strategies: This stage conceptualizes five distinct strategies, each offering different perspectives on evaluating SW artifacts, from "Direct Assess" to "Generate Tests and Assess."
- Dynamic Team Formation: Rather than applying all strategies universally, this mechanism dynamically selects an appropriate sub-team of strategies tailored to the task and dataset characteristics, thereby optimizing both cost and performance.
- Correctness Score Generation: The selected team evaluates each task, and an ensemble of scores is integrated into a singular judgment, transforming into the final metric aligned closely with human judgment.
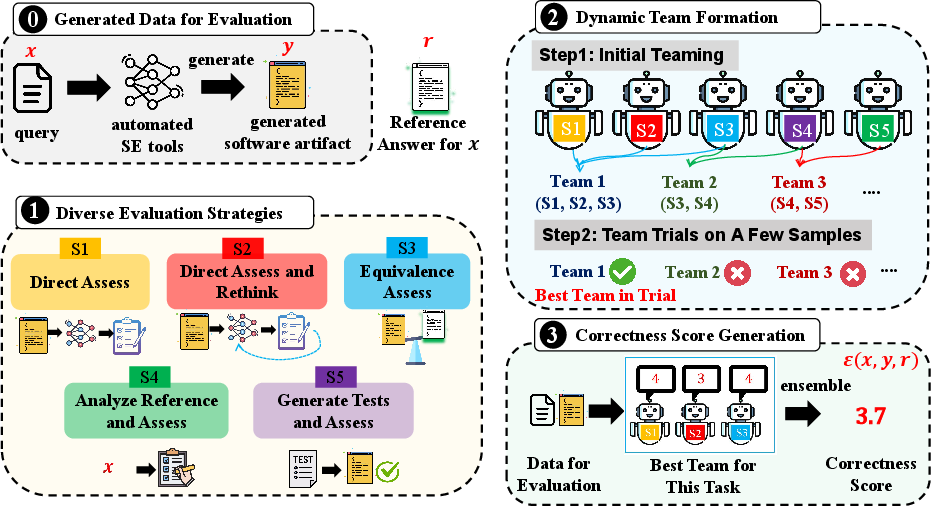
Figure 1: Overview of SE-Jury.
Evaluation Strategies in Detail
Direct Assess and Rethink
Strategies involve an initial pass where LLMs evaluate code and a second phase where these assessments are reevaluated. It reflects human reevaluation processes aimed at mitigating initial biases or oversights.
Equivalence Assess
This strategy assesses the artifact's correctness by comparing its functional equivalence to known reference solutions. It tests semantic equivalence to ensure that even syntactically dissimilar artifacts that serve the intended functionality receive appropriate acknowledgment.
Analyze and Test Evaluation
More concretely, SE-Jury involves creating synthetic tests where original test cases are absent, using reference solutions as the baseline. This novel angle addresses environments lacking exhaustive testing resources.
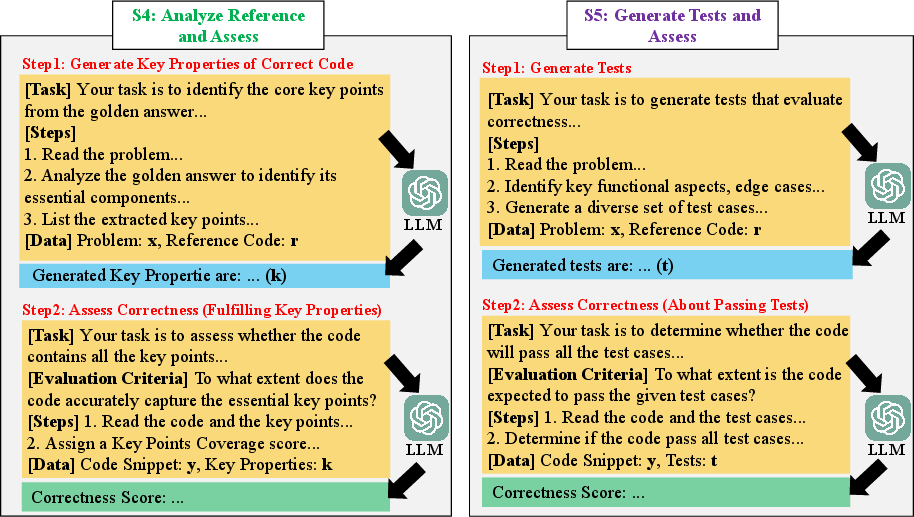
Figure 2: Prompt Designs of Strategy 4 and Strategy 5.
SE-Jury demonstrates substantial success across multiple SE benchmarks, including code generation in Python and Java, automated program repair, and code summarization. Evaluations show impressive statistical correlations (Kendall's τ and Spearman's rs) between SE-Jury's scores and human evaluations. Specifically, it reports correlation improvements ranging from 29.6% to 140.8% compared to traditional metrics, with particular robustness in code generation and repair assessments.
Conclusion
SE-Jury advances the current landscape of evaluating software generation by effectively capturing aspects of correctness that traditional automatic metrics overlook, particularly in their reliance on syntax over semantic accuracy. The framework's thoughtful incorporation of diverse evaluative strategies and its dynamic team selection have made a definitive stride towards achieving human-parity in SE task evaluations.
In future research, extending these approaches to capture non-functional attributes such as code efficiency and resourcefulness can create even more holistic assessment tools.