- The paper demonstrates that LLMs, especially GPT-4-turbo, can automate code evaluation but frequently misclassify correctness, as shown by low agreement metrics.
- The paper reveals that using automated chain-of-thought prompting improves judgment accuracy across multiple LLMs for both code generation and summarization tasks.
- The paper uncovers a negative bias against human-written code, emphasizing the need for hybrid evaluation systems combining LLM judgments with human oversight.
Evaluating LLM-as-a-Judge for Code Generation and Summarization
Introduction and Motivation
The paper systematically investigates the effectiveness of LLMs as automated judges for two core software engineering tasks: code generation and code summarization. The motivation stems from the inadequacy of standard quantitative metrics (e.g., BLEU, ROUGE) for evaluating generative code tasks, and the impracticality of large-scale human evaluation. The study aims to determine whether LLMs can reliably assess the quality of code and code summaries, potentially enabling scalable, automated evaluation pipelines.
Experimental Design
LLMs and Datasets
Eight LLMs were evaluated, including DeepSeek Coder (1.3B, 6.7B, 33B), CodeLlama (7B, 13B, 34B), GPT-3.5-turbo, and GPT-4-turbo. All models were instruction-tuned and trained on code corpora. The code generation task used the CoderEval benchmark (184 Java, 190 Python problems after quality filtering), while code summarization used a new dataset of 1,163 summaries (Java and Python), each rated by three human experts.
Judging Protocols
For code generation, LLMs were prompted to judge the correctness of candidate implementations (either LLM- or human-generated) given only the problem description and function signature, without access to reference implementations. Four prompt variants were tested, with "automated Chain-of-Thought" (CoT) prompting yielding the best results.
For code summarization, LLMs rated summaries on content adequacy, conciseness, and fluency/understandability using four prompt variants. The "zero-shot" prompt was most effective for the best-performing LLMs.
Results: Code Generation Judging
Judgment Success Rates and Agreement
Larger LLMs (notably GPT-4-turbo) almost always produced valid judgments, while smaller models failed in up to 15% of cases. However, the ability to output a judgment did not equate to correctness. Cohen's Kappa agreement between LLM judgments and test suite outcomes was low for all models, with GPT-4-turbo achieving the highest scores (Java: 0.21, Python: 0.10), barely reaching the "fair" agreement threshold.
Confusion Matrix Analysis
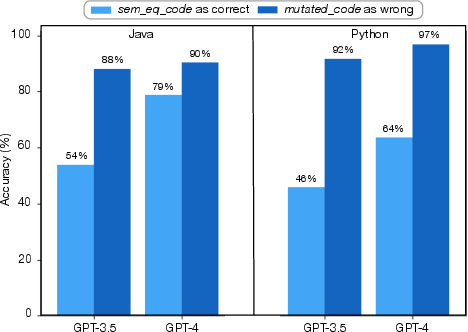
Figure 1: Code generation: Results of the mutants injection and semantically-equivalent code transformations applied on true positives.
Confusion matrices revealed that even GPT-4-turbo frequently misjudged code correctness. For Java, GPT-4-turbo correctly identified 72% of correct implementations but misclassified 50% of incorrect ones as correct. For Python, the model misjudged 35% of incorrect implementations as correct and only correctly classified 46% of correct implementations. This indicates a strong tendency to overestimate correctness, especially for LLM-generated code.
Robustness and Error Analysis
Mutation analysis, involving the injection of semantic bugs and semantically-equivalent transformations, showed that GPT-4-turbo could identify injected bugs in 97% of Python and 88% of Java cases, but failed to consistently recognize semantically-equivalent code as correct (only 64% for Python, 79% for Java). Manual error analysis attributed false positives mainly to uncaught wrong behaviors and lack of context, while false negatives were often due to hallucinations or misunderstanding code statements.
Self-Bias
Statistical analysis found minimal self-bias in GPT-4-turbo's judgments, but a significant negative bias against human-written code: LLMs systematically underestimated the correctness of human code compared to LLM-generated code, with large effect sizes.
Results: Code Summarization Judging
Judgment Success Rates and Agreement
For code summarization, only the largest models (GPT-3.5-turbo, GPT-4-turbo) produced judgments with meaningful agreement to human ratings. Krippendorff's α for GPT-4-turbo reached 0.58–0.63 for content adequacy (Java/Python), indicating moderate agreement, and 0.36–0.40 for conciseness, with lower but still positive agreement for fluency/understandability.
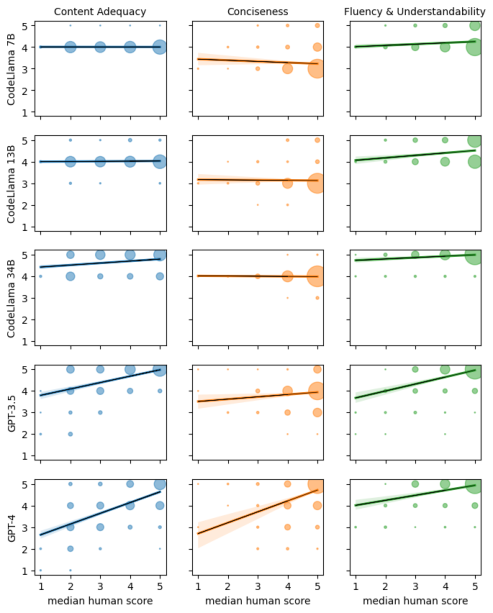
Figure 2: Code summarization (Java): Scatterplots relating human to LLM judgments. The three quality criteria subject of the judgment are shown as columns, while the judging LLMs are rows. Within each scatterplot the median of the ratings provided by the three human judges is on the x-axis, and the score assigned by the LLM is on the y-axis.
Scatterplots (Figure 2) confirmed that only GPT-4-turbo's ratings correlated with human judgments, especially for content adequacy. Smaller models (CodeLlama family) acted as near-constant classifiers, showing no meaningful relationship to human ratings.
Self-Bias
No significant self-bias was observed in GPT-4-turbo's summary judgments. However, all LLMs tended to overestimate the quality of LLM-generated summaries relative to human-written ones, mirroring the trend observed in code correctness judgments.
Human vs. LLM-Generated Summaries
An unexpected finding was that human raters assigned higher content adequacy scores to GPT-4-turbo-generated summaries than to human-written ones, suggesting that LLMs may now surpass average human performance in code summarization for certain metrics.
Implications and Limitations
Practical Implications
- Code Generation: Even the strongest LLMs (GPT-4-turbo) are unreliable as sole judges of code correctness, with high rates of both false positives and negatives. This limits their utility for automated code review, bug triage, or large-scale code evaluation without human oversight or robust test suites.
- Code Summarization: GPT-4-turbo demonstrates moderate agreement with human judgments, especially for content adequacy, making it a viable candidate for scalable evaluation of code summarization systems. This is particularly relevant given the poor correlation between human judgment and standard metrics like BLEU or ROUGE.
Theoretical Implications
The results highlight the limitations of current LLMs in code reasoning and understanding, especially for correctness verification. The observed negative bias against human code suggests that LLMs may be overfitting to the statistical regularities of their own generations, raising questions about the generalizability of LLM-based evaluation.
Limitations
- The study is limited to Java and Python, and to the specific tasks of code generation and summarization.
- Only general-purpose, instruction-tuned LLMs were evaluated; fine-tuned judge models may yield different results.
- Test suite quality and human rating subjectivity, while mitigated, remain potential sources of bias.
Future Directions
- Fine-tuning smaller LLMs specifically for code judgment tasks may improve their reliability and cost-effectiveness.
- Extending the evaluation to other code-related tasks (e.g., bug-fixing, code review) and programming languages.
- Investigating hybrid evaluation pipelines combining LLM judgments with traditional metrics and human oversight.
- Exploring methods to mitigate LLMs' negative bias against human code and improve their robustness to code diversity.
Conclusion
The study provides a comprehensive empirical assessment of LLMs as automated judges for code generation and summarization. While GPT-4-turbo outperforms smaller models, it remains unreliable for code correctness evaluation, but shows promise for code summarization assessment. The findings underscore the need for continued research into LLM-based evaluation, especially for tasks requiring deep code understanding, and suggest that LLMs can complement but not yet replace human judgment in software engineering evaluation pipelines.