- The paper introduces LeMAJ, a framework that segments LLM outputs into Legal Data Points (LDPs) for granular, reference-free legal evaluation.
- The methodology leverages automated segmentation and classification to assess correctness, relevance, and omissions, closely mimicking human legal analysis.
- Experimental results show LeMAJ's superior performance in reducing subjectivity and improving efficiency in legal reviews compared to traditional metrics.
LeMAJ (Legal LLM-as-a-Judge): Bridging Legal Reasoning and LLM Evaluation
Introduction
The paper "LeMAJ (Legal LLM-as-a-Judge): Bridging Legal Reasoning and LLM Evaluation" addresses the challenges of evaluating LLM outputs within the legal domain, focusing on the intricate nature of legal analysis. The authors propose a novel framework, LeMAJ, that eschews the need for expensive and high-quality reference datasets by breaking responses into "Legal Data Points" (LDPs). This approach mimics the detailed, point-wise evaluation process employed by legal practitioners.
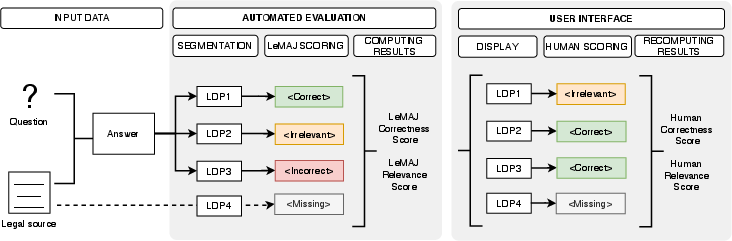
Figure 1: Based on a legal document, a question and an answer, our LeMAJ framework performs an automated evaluation by segmenting the answer into Legal Data Points (LDPs) and evaluating each one.
Methodology
LeMAJ introduces an innovative process to automatically segment LLM-generated answers into LDPs. These self-contained units of information undergo individual correctness and relevance assessments. This granular evaluation methodology aligns closely with the analytical processes of human legal experts, enhancing correlation with human evaluation.
To implement this system, the authors utilize a classification system to tag each LDP. The criteria for this tagging include:
- Correctness: LDPs containing factual inaccuracies or hallucinations are marked as incorrect.
- Relevance: Factually correct LDPs are assessed based on their relevance to the posed question.
- Correct and Relevant: LDPs that meet both criteria are tagged accordingly.
- Critical Omissions: Missing yet relevant information is identified and tagged as omissions.
The research demonstrates LeMAJ's superiority over traditional methods such as BLEU and ROUGE, and even more advanced techniques like DeepEval, without requiring reference data. This is achieved by ensuring the evaluation closely reflects human judgment through a meticulous breakdown and analysis of legal answers.

Figure 2: An example of LDPs with both the LLM evaluation performed by LeMAJ and the human evaluation by a human legal expert, resulting in the LeMAJ Alignment score.
Experiments and Results
The authors conducted experiments on a proprietary dataset and the open-source LegalBench dataset to validate LeMAJ's effectiveness. Results indicate a significant improvement in alignment between LLM evaluations and human judgments. LeMAJ displayed superior performance metrics, especially in contexts that lacked comprehensive reference data, marking its potential as a scalable evaluation method.
Additionally, the improved inter-annotator agreement when using LeMAJ suggests that the framework can reduce the subjectivity often associated with human evaluations. This is further corroborated by experiments showing how human evaluators benefit from the LDP segmentation, leading to more consistent and auditable evaluations.
Scaling and Commercial Application
To address the high computational costs associated with large model evaluations, the paper also explores potential scaling solutions through fine-tuning techniques and LLM Jury frameworks. These strategies ensure the model's efficiency without compromising accuracy.
A key operational benefit of LeMAJ, as demonstrated in the study, is the potential for significant time savings in commercial legal reviews. By triaging answers based on confidence scores derived from LeMAJ evaluations, legal experts can concentrate on contentious cases, enhancing workflow efficiency.
Conclusion
LeMAJ emerges as a promising tool for evaluating legal LLM outputs with its detailed, reference-free methodology closely aligned with legal professionals' evaluation processes. The research not only illustrates its effectiveness over baseline methods but also highlights future work potential in enhancing accuracy and task adaptability. This opens a path for improving LLM-as-a-Judge frameworks with context-specific flexibility and scalability.

