Entropy-based Exploration Conduction for Multi-step Reasoning
Published 20 Mar 2025 in cs.AI and cs.CL | (2503.15848v2)
Abstract: Multi-step processes via LLMs have proven effective for solving complex reasoning tasks. However, the depth of exploration of the reasoning procedure can significantly affect the task performance. Existing methods to automatically decide the depth often lead to high cost and a lack of flexibility. To address these issues, we propose Entropy-based Exploration Depth Conduction (Entro-duction), a novel method that dynamically adjusts the exploration depth during multi-step reasoning by monitoring LLM's output entropy and variance entropy. We employ these two features to capture the model's uncertainty of the current step and the fluctuation of uncertainty across consecutive reasoning steps. Based on the observed entropy changes, the LLM selects whether to deepen, expand, or stop exploration according to the probability, which facilitates the trade-off between the reasoning accuracy and exploration effectiveness. Experimental results across four benchmark datasets demonstrate the efficacy of Entro-duction.
The paper presents Entro-duction, a method that uses entropy and variance entropy metrics to dynamically adjust LLM exploration depth.
It employs an ε-greedy strategy to determine whether to deepen, expand, or stop the reasoning process based on uncertainty levels.
Experiments on datasets like GSM8K and CommonsenseQA demonstrate improved reasoning accuracy and efficiency compared to baseline methods.
Entropy-based Exploration Conduction for Multi-step Reasoning
Introduction
The paper "Entropy-based Exploration Conduction for Multi-step Reasoning" introduces a method called Entropy-based Exploration Depth Conduction (Entro-duction) aimed at improving the reasoning performance of LLMs. In multi-step reasoning tasks, matching the reasoning depth with the task complexity is crucial for accuracy and efficiency. Entro-duction leverages entropy and variance entropy metrics to dynamically adjust exploration depth based on the LLM's uncertainty and fluctuation in uncertainty during the reasoning process.
Methodology
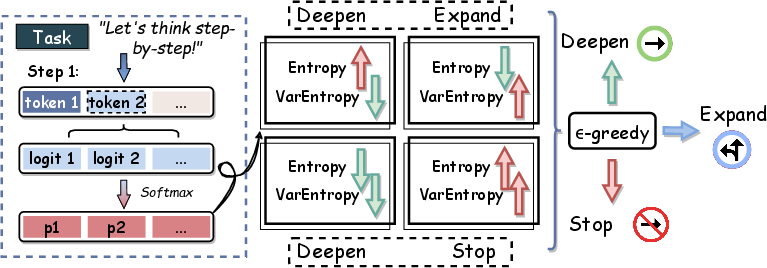
Entro-duction operates by dynamically evaluating the LLM's exploration adequacy through entropy-based metrics. The entropy measures the uncertainty of the reasoning process at each step, reflecting confidence levels and guiding the exploration strategy. Variance entropy tracks fluctuations in uncertainty across reasoning steps, providing insights into consistency or divergence in thought processes.
Reasoning State Evaluation
To evaluate the reasoning state, entropy is calculated for each reasoning step based on the probability distribution of logits. The normalized entropy is used to compare reasoning steps of varying lengths:
These metrics help determine when to deepen, expand, or cease exploration (Figure 1).
Figure 2: Framework of Entro-duction. We obtain two metrics, entropy and variance entropy, by calculating the probabilities of the logits at each reasoning step. Subsequently, we employ the ϵ-greedy method to select the appropriate exploration behavior based on changes in both metrics.
Exploration Behaviors
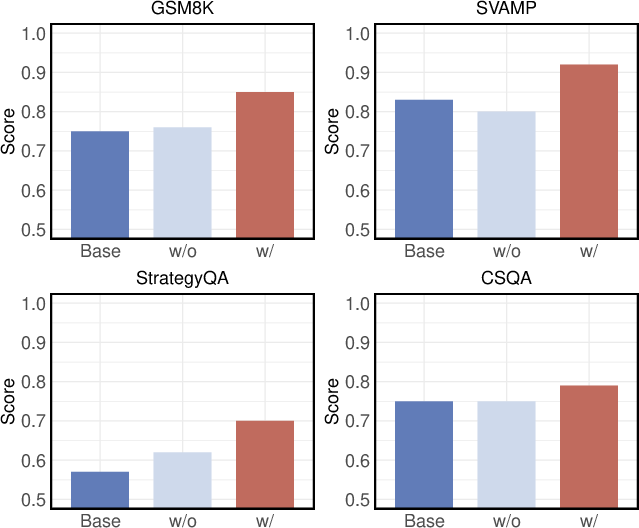
The approach defines three main behaviors: Deepen, Expand, and Stop. 'Deepen' extends the reasoning chain, 'Expand' branches out to explore alternative solutions, and 'Stop' halts further exploration (Figure 3).
Figure 3: Impact of the behavior Expand.
Behavior Selection Mechanism
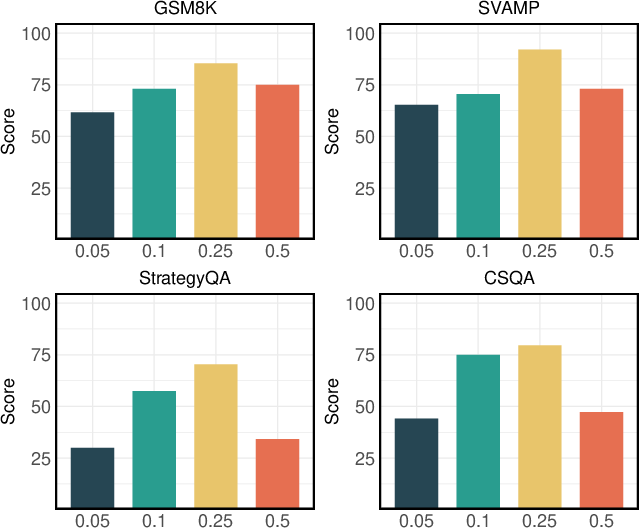
An ϵ-greedy strategy maps changes in entropy and variance entropy to exploration actions. The policy Φ selects actions based on observed changes, allowing for adaptive exploration adjustments (Figure 4).
Figure 4: Comparison of choice of ϵ.
Experimental Evaluation
Experiments across datasets (GSM8K, SVAMP, StrategyQA, CommonsenseQA) demonstrate that Entro-duction achieves superior reasoning accuracy compared to baseline reasoning structures and optimization methods. It balances exploration depth effectively, resulting in fewer steps than methods like CoT-SC and ToT, while outperforming reasoning accuracy metrics.
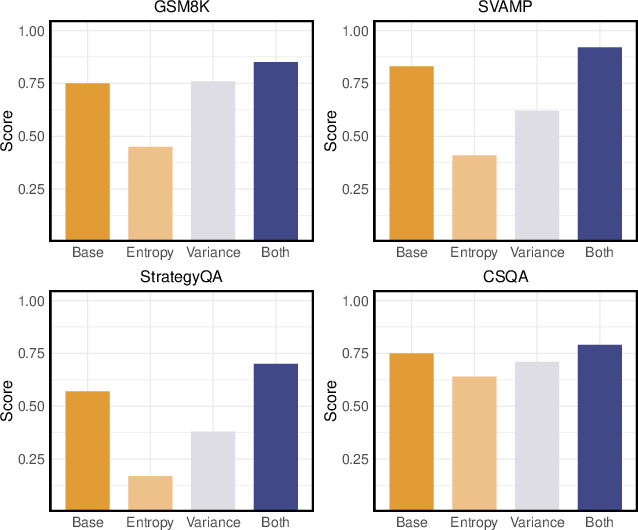
The results highlight the effectiveness of combining entropy metrics to adjust exploration dynamically and improve task-specific reasoning performance. The experiments also include ablation studies, examining the individual contributions of entropy, variance entropy, and the expansion behavior strategy (Figures 3 and 5).
Figure 5: Comparison of adjusting with entropy and/or variance entropy.
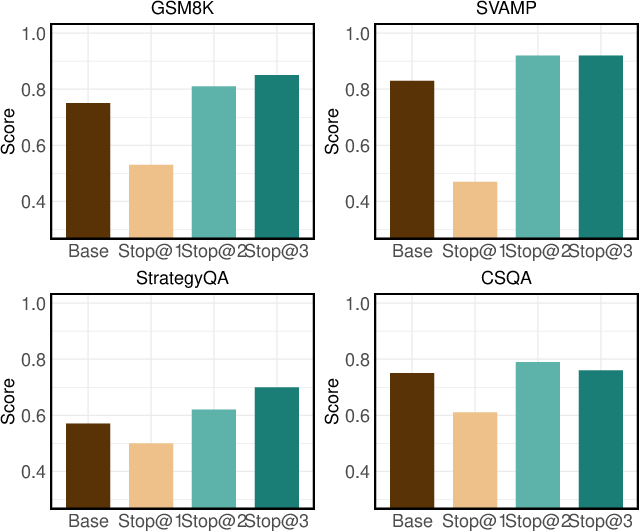
Figure 6: Comparison of stopping strategies.
Conclusion
Entropy-based Exploration Conduction presents a robust framework for optimizing LLM reasoning processes by dynamically adjusting exploration depth. This method not only enhances reasoning accuracy but also reduces unnecessary exploration, adapting to various reasoning tasks with its flexible exploration behavior strategy. The method stands to improve multi-step reasoning tasks across numerous AI applications, setting a foundation for further research into adaptive exploration methodologies in complex reasoning scenarios. Future work could expand on generalization across diverse LLM architectures and exploring real-time applications in dynamic environments.