- The paper presents the KEEN method that probes hidden representations to estimate entity knowledge without text generation.
- It employs logistic regression on feature vectors from transformer layers to predict QA accuracy and factuality scores.
- KEEN reliably correlates with model hedging behavior and identifies knowledge gaps, offering valuable insights for model augmentation.
Estimating Knowledge in LLMs Without Generating a Single Token
This essay provides a detailed exploration into the techniques developed for estimating entity knowledge within LLMs without the need for text generation. This approach introduces the KEEN (Knowledge Estimation of ENtities) method, which aims to assess a model's knowledge based on its internal computations.
Introduction to KEEN
KEEN proposes a novel way to measure the knowledge LLMs possess about specific entities using probes on hidden model representations rather than relying on generated outputs. The paper introduces two primary tasks in this domain: predicting the entity-specific QA accuracy and the factuality of text generated about the entities. These objectives aim to assess entity knowledge directly from internal model states, bypassing the need for text generation and subsequent evaluation.
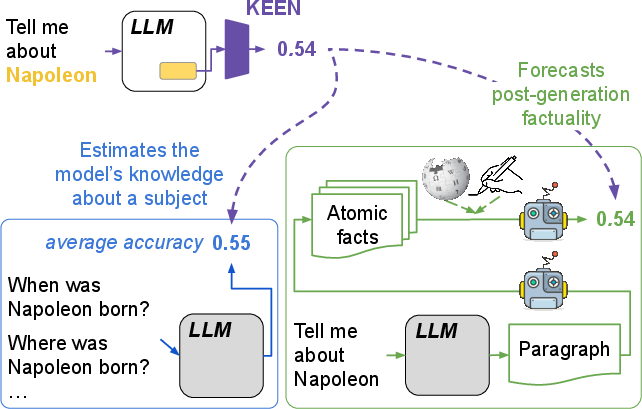
Figure 1: Simple probes (KEEN) quantify model knowledge about a subject entity by estimating question-answering accuracy and factuality of text generation.
Methodology
The KEEN approach leverages the hidden representations within the layers of Transformer-based LLMs. Specifically, it draws from upper-intermediate layers which are known to effectively encapsulate entity attributes into straightforward linear projections. To create the feature vector for a given entity, KEEN employs various feature sets such as hidden states (HS), vocabulary projections (VP), and a more interpretable form called VP-k, which selects the top-k influential tokens to enhance interpretability without sacrificing accuracy.
Probing Mechanism
Probing uses logistic regression to predict either the QA accuracy or factuality score based on extracted feature vectors. A sigmoid function ensures these predictions are bound within [0, 1], allowing models to generalize across diverse entities efficiently.
Experimental Evaluation
Experimental Settings
Two principal evaluation settings are established—Factual QA and Open-Ended Generation (OEG). For the QA-task, entity-specific questions derived from PopQA data are employed, and for OEG, KEEN correlates its outputs with FActScore, an open-ended text evaluation metric that determines the factual correctness of generative outputs.
The experiments cover multiple LLMs including GPT2, Pythia, LLaMA2, and Vicuna, showcasing KEEN's versatility across models of varying architecture and complexity.
Results and Analysis
The KEEN probes demonstrate strong correlations with the model's QA accuracy and the factual scores, outperforming other baselines that utilize either intrinsic features like self-attention outputs or external statistics such as entity popularity. Further, KEEN has been shown to faithfully reflect knowledge changes following fine-tuning, showcasing its potential for guiding model augmentation efforts or identifying knowledge gaps.
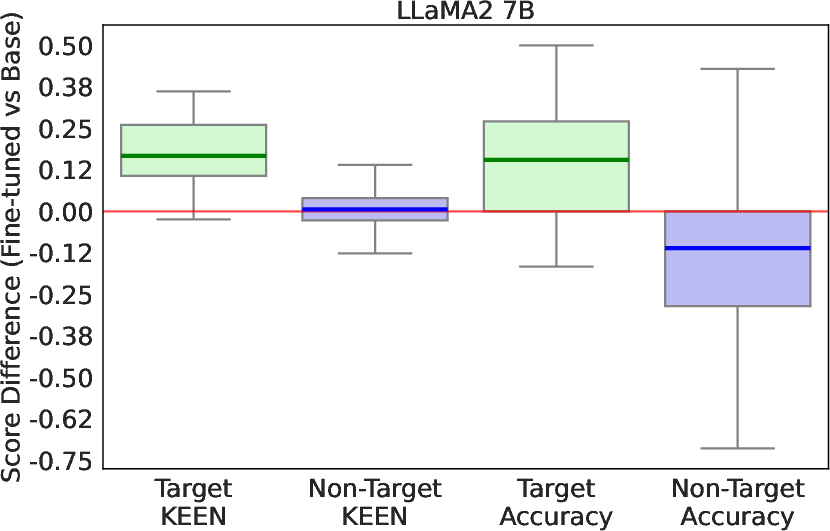
Figure 2: Changes in KEEN QA and average QA accuracy scores post fine-tuning LLaMA2 7B, highlighting KEEN's robust reflection of knowledge adjustments.
Probing Internal Model Behavior
KEEN’s scores also align with model hedging behavior, where predictions correlate inversely with the fraction of queries hedged by the model, emphasizing the reliability of internal representations for forecasting entity knowledge.
Interpretability and Generalization
Through VP-k probes, KEEN introduces interpretability in understanding how entities are embedded and processed within the model. Analysis of the critical token weights drawn from VP-k offers insights into which entity-specific features are most influential, aiding in distinguishing highly knowledgeable representations from less knowledgeable ones.
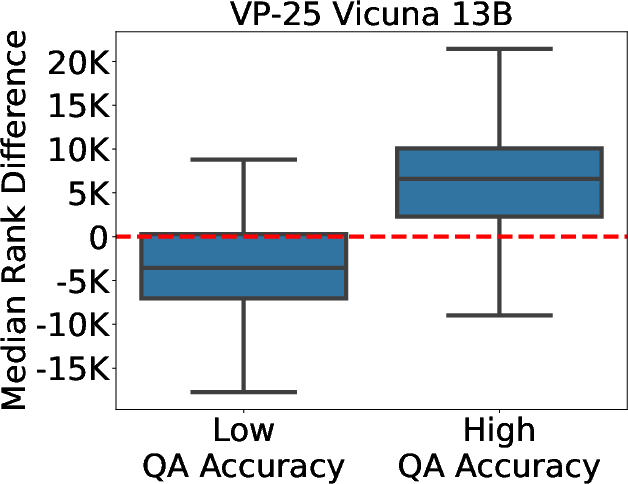
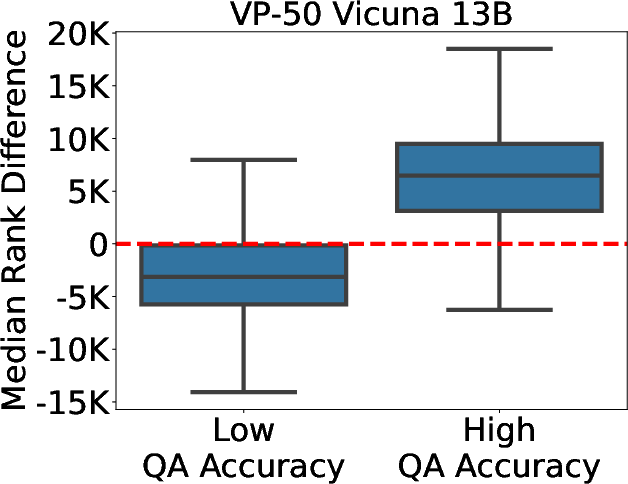
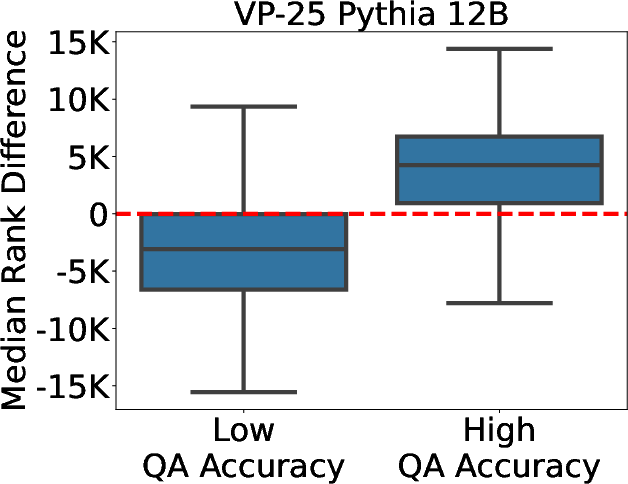
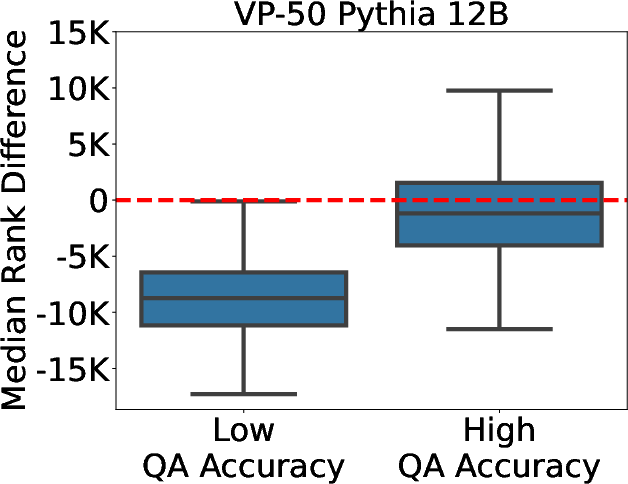
Figure 3: Difference in the median rank of tokens with negative and positive weights for accuracy differentiation.
Conclusion
KEEN introduces a simple yet powerful framework for estimating the knowledge and performance of LLMs on a per-entity basis without output generation. This methodology not only presents a pathway to assess model knowledge but also unlocks potential enhancements in model deployment strategies and educational calibration of LLMs. Future explorations may extend KEEN’s applicability beyond named entities to more abstract subjects, along with integrating KEEN for broader model architectures beyond transformers.
Overall, KEEN improvises the landscape of model interpretability and factual reliability in LLMs, paving the way for more robust applications across varied AI domains.