- The paper introduces a method that uses pre-trained VLMs like CLIP as zero-shot reward models to train RL agents with natural language task descriptions.
- The paper employs a goal-baseline regularization technique to enhance reward specificity and improve policy learning across both classic control and complex humanoid tasks.
- The paper shows that scaling up CLIP models significantly improves reward precision and overall RL performance, indicating robust applicability in diverse environments.
Overview of "Vision-LLMs are Zero-Shot Reward Models for Reinforcement Learning" (2310.12921)
This paper proposes a method for utilizing Vision-LLMs (VLMs) such as CLIP as zero-shot reward models for Reinforcement Learning (RL). The authors introduce the VLM-RM technique to facilitate RL in vision-based domains using natural language descriptions as task specifications without the need for manual reward function engineering or extensive human feedback. The paper also explores scaling effects by analyzing the performance of various sized CLIP models, demonstrating significant improvements with larger models. Experiments conducted show the method's applicability in classic control benchmarks and more complex humanoid tasks.
Reinforcement Learning with Zero-Shot VLM Reward Models
Method Explanation
The core approach involves using pre-trained VLMs to provide reward signals based on natural language descriptions. The paper describes how to use VLMs, particularly CLIP, to derive rewards by computing cosine similarity between the language prompt and state image embedding. This method obviates the need for additional training or fine-tuning, leveraging the zero-shot capabilities inherent in VLMs.
CLIP as a Reward Model
By employing the CLIP model, rewards are determined through cosine similarity measures between task descriptions and environment states. This approach presents a straightforward mechanism to train RL policies in vision-based tasks without manually constructed reward functions, contributing greatly to automation in RL setups.
Goal-Baseline Regularization
To enhance the robustness of the reward model, the authors introduce a regularization technique that incorporates a baseline description. This projection-based method effectively suppresses irrelevant components within the state representations, improving task specificity in rewards and thereby refining policy learning.

Figure 1: We use CLIP as a reward model to train a MuJoCo humanoid robot to (1) stand with raised arms, (2) sit in a lotus position, (3) do the splits, and (4) kneel on the ground (from left to right).
Implementation and Experimentation
Classic Control Benchmarks
The application of VLM-RMs begins with standard RL environments like CartPole and MountainCar. The authors show that textured environments yield more meaningful CLIP-derived reward landscapes due to their closer proximity to the model's training distribution. These experiments validate the feasibility and effectiveness of employing CLIP-based zero-shot rewards in simple RL domains.
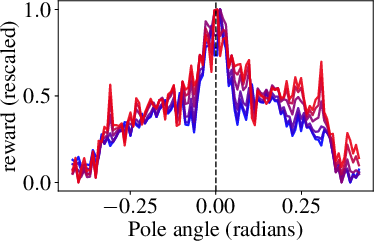

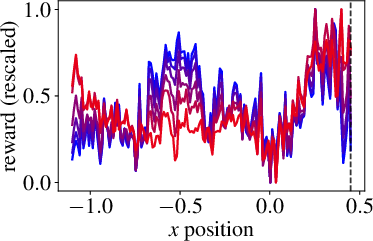

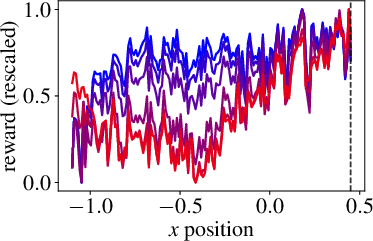
Figure 2: CartPole and MountainCar environments tested with VLM-RMs show the reward landscape as a function of key state parameters, indicating successful learning behavior.
Complex Humanoid Tasks
For more challenging tasks, such as various movement positions of a humanoid robot in MuJoCo, the zero-shot CLIP reward models successfully enable the RL agent to perform complex maneuvers with minimal prompt engineering. Tasks like kneeling and doing the splits exhibit high success rates, demonstrating VLM-RM efficacy, although not all tasks succeeded, indicating areas for further model enhancement.
Scaling Effects and Model Size Implication
The paper rigorously explores the impact of model size on the reward model quality and RL performance. Larger CLIP models correlate strongly with improved reward model precision and increased success rates in more demanding tasks. Notably, a transition occurs where only the largest model reviewed achieves successful task completion.

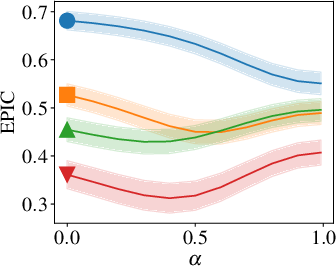
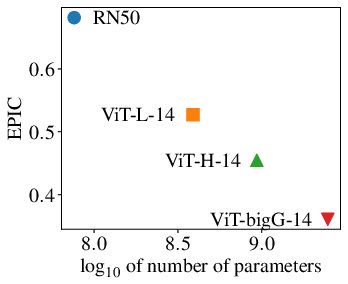
Figure 3: Goal-baseline regularization for different model sizes shows how VLM-RMs become better with increased VLM scale.
Implications and Future Directions
VLM-RMs represent a significant leap toward automating reward specification in RL, reducing reliance on extensive human feedback and manual reward engineering. Future advancements will likely be driven by improved VLMs capable of handling more nuanced and complex tasks. Fine-tuning these models and exploring dialogue-based reward specifications stand as promising areas of exploration. The robustness against optimization pressure also poses an inquiry for ongoing research to ensure safety and reliability in practical applications.
Conclusion
The research presented lays a foundation for integrating cutting-edge VLMs within RL frameworks, simplifying task specification with natural language. This approach harnesses the scalability of VLMs to extend the reach of reward models, promising seamless adaptation to increasingly sophisticated tasks and environments.