- The paper formalizes visual RL challenges and categorizes over 200 studies into four thematic pillars based on architectures and reward paradigms.
- It details three alignment paradigms—RLHF, DPO, and RLVR—highlighting their computational trade-offs and implications for training stability.
- The survey outlines future challenges including sample efficiency, safe deployment, and refined reward model design to advance visual decision-making.
Reinforcement Learning in Vision: A Survey
Introduction and Scope
This survey provides a comprehensive synthesis of the intersection between reinforcement learning (RL) and visual intelligence, focusing on the rapid evolution of RL methodologies for multimodal large models, including vision-LLMs (VLMs), vision-language-action (VLA) agents, diffusion-based visual generation, and unified multimodal frameworks. The work formalizes visual RL problems, traces the development of policy optimization strategies, and organizes over 200 representative studies into four thematic pillars: multimodal LLMs, visual generation, unified models, and VLA agents. The survey critically examines algorithmic design, reward engineering, benchmark progress, and evaluation protocols, while identifying open challenges such as sample efficiency, generalization, and safe deployment.
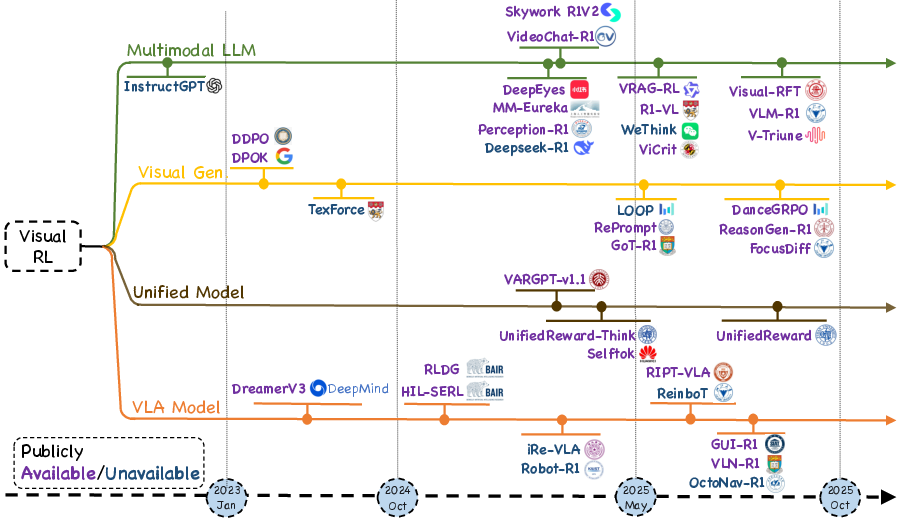
Figure 1: Timeline of Representative Visual Reinforcement Learning Models, organized into Multimodal LLM, Visual Generation, Unified Models, and VLA Models from 2023 to 2025.
The survey casts text and image generation as episodic Markov Decision Processes (MDPs), where the user prompt serves as the initial state and each generated token or pixel patch is an action sampled autoregressively from the policy. Three major alignment paradigms are delineated:
- RL from Human Feedback (RLHF): Utilizes pairwise human preference data to train a scalar reward model, which is then used to fine-tune the policy via KL-regularized PPO. RLHF pipelines typically follow a three-stage recipe: supervised policy pre-training, reward model training, and RL fine-tuning.
- Direct Preference Optimization (DPO): Removes the intermediate reward model and RL loop, directly optimizing a contrastive objective against a frozen reference policy. DPO is computationally efficient and avoids the need for value networks or importance sampling.
- Reinforcement Learning with Verifiable Rewards (RLVR): Replaces subjective human preferences with deterministic, programmatically checkable reward signals (e.g., unit tests, IoU thresholds), enabling stable and scalable RL fine-tuning.
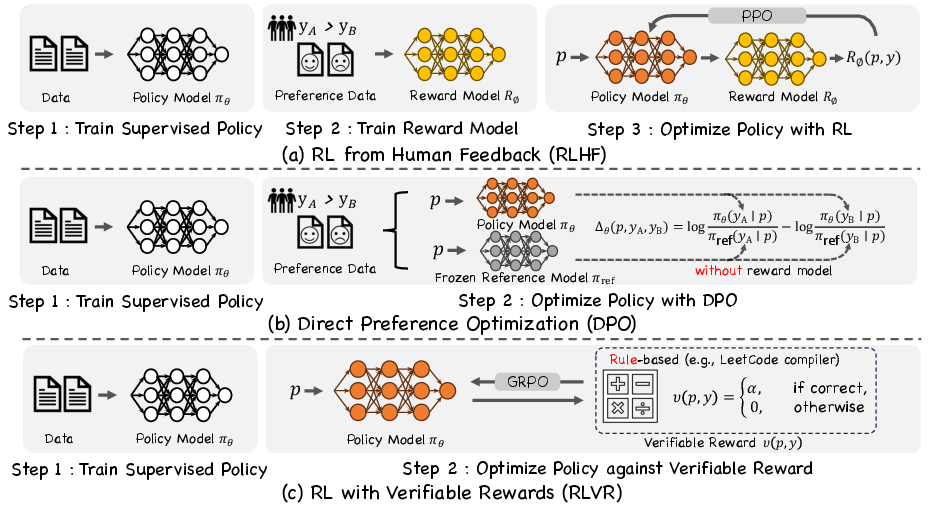
Figure 2: Three Alignment Paradigms for Reinforcement Learning: RLHF, DPO, and RLVR, each with distinct reward sources and optimization strategies.
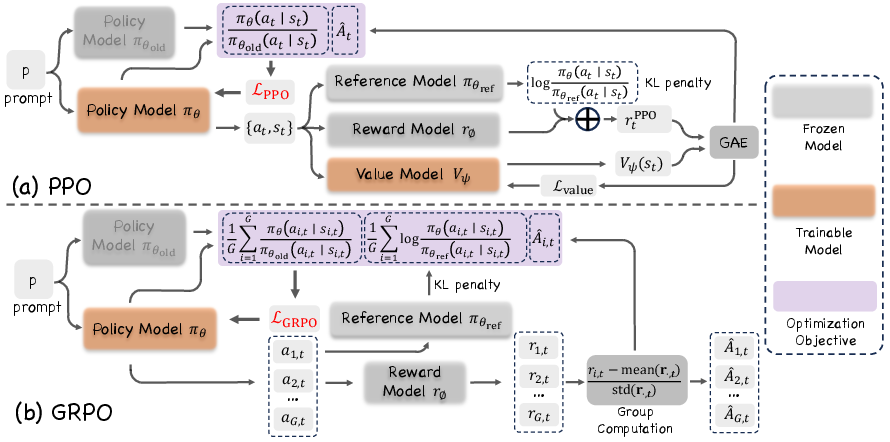
Policy Optimization Algorithms
Two representative policy optimization algorithms are discussed:
Taxonomy of Visual RL Research
The survey organizes visual RL research into four high-level domains:
- Multimodal LLMs (MLLMs): RL is applied to align vision-language backbones with verifiable or preference-based rewards, improving robustness and reducing annotation costs. Extensions include curriculum-driven training and consistency-aware normalization.
- Visual Generation: RL fine-tunes diffusion and autoregressive models for image, video, and 3D generation. Reward paradigms include human-centric preference optimization, multimodal reasoning-based evaluation, and metric-driven objective optimization.
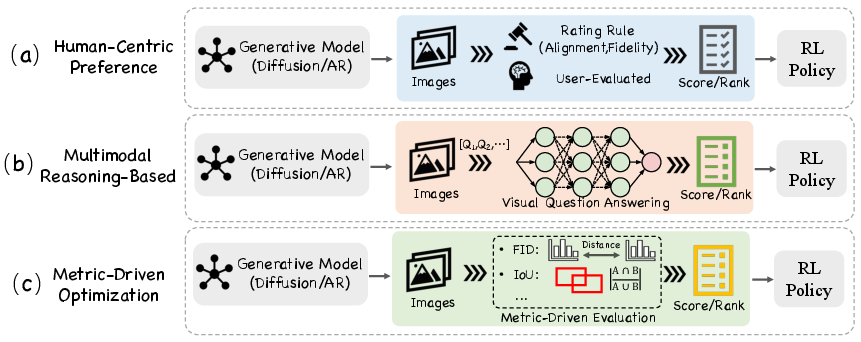
Figure 4: Three reward paradigms for RL-based image generation: human-centric preference, multimodal reasoning, and metric-driven objective optimization.
- Unified Models: Unified RL methods optimize a shared policy across heterogeneous multimodal tasks under a single reinforcement signal, promoting cross-modal generalization and reducing training cost.
- Vision-Language-Action Agents: RL is used for GUI automation, visual navigation, and manipulation, leveraging rule-based or preference rewards for robust, long-horizon decision-making.
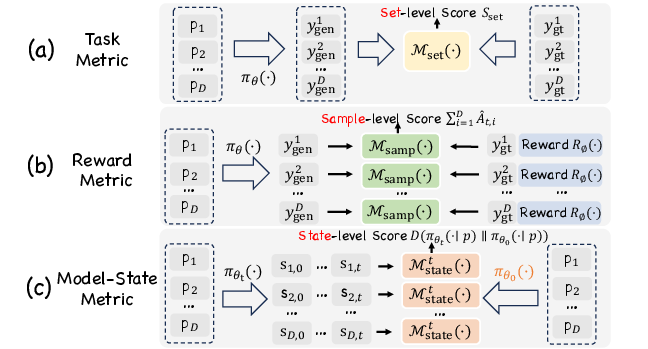
Evaluation Protocols and Metric Granularity
The survey formalizes evaluation metrics at three granularities:
Benchmarks are discussed for each domain, with RL-focused datasets providing human preference data, verifiable success criteria, and step-wise reasoning annotations. The survey highlights the need for evaluation standards that capture real-world utility, ethical alignment, and energy footprint.
Challenges and Future Directions
Key challenges identified include:
- Reasoning Calibration: Balancing depth and efficiency in visual reasoning, with adaptive horizon policies and meta-reasoning evaluators.
- Long-Horizon RL in VLA: Addressing sparse rewards and credit assignment through intrinsic sub-goal discovery, affordance critics, and hierarchical RL.
- RL for Visual Planning: Designing action spaces and credit assignment for "thinking with images," with structured visual skills and cross-modal reward shaping.
- Reward Model Design for Visual Generation: Integrating low-level signals with high-level human preferences, generalizing across modalities, and mitigating reward hacking.
Conclusion
Visual reinforcement learning has evolved into a robust research area bridging vision, language, and action. The survey demonstrates that progress is driven by scalable reward supervision, unified architectures, and rich benchmarks. Persistent challenges include data and compute efficiency, robust generalization, principled reward design, and comprehensive evaluation. Future developments will likely involve model-based planning, self-supervised pre-training, adaptive curricula, and safety-aware optimization. The survey provides a structured reference for advancing sample-efficient, reliable, and socially aligned visual decision-making agents.