- The paper introduces EMAC+, which integrates LLMs and VLMs using a dynamic feedback loop to refine planning and execution in complex tasks.
- It employs a bidirectional training paradigm and closed-loop planning, markedly improving performance on ALFWorld and RT-1 benchmarks.
- Experimental results and ablation studies demonstrate EMAC+'s robustness, adaptability, and potential applicability in real-world robotic control.
EMAC+: Embodied Multimodal Agent for Collaborative Planning with VLM+LLM
EMAC+ introduces an innovative approach to integrate LLMs with Vision-LLMs (VLMs), proposing a dynamic feedback loop for enhanced planning and execution in complex tasks. This agent overcomes major limitations of previous static multimodal agents by refining high-level textual plans with real-time feedback from VLMs, leveraging visual and semantic data collaboratively. The detailed architecture of EMAC+ (Figure 1) outlines its capacity to utilize both LLM-derived knowledge and environment-specific dynamics for adaptive action planning.
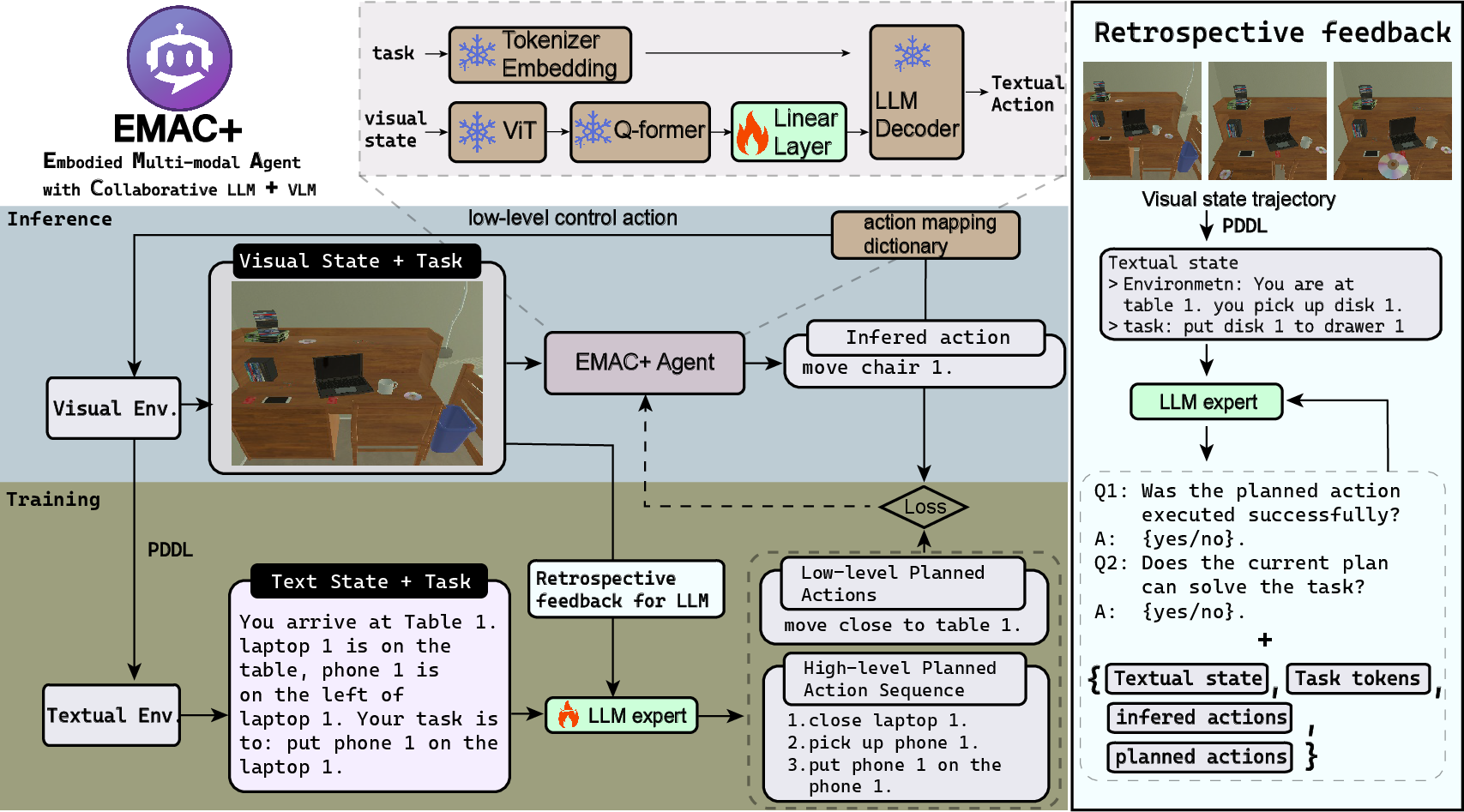
Figure 1: EMAC+: Embodied Multi-modal Agent for Collaborative Planning with LLM + VLM.
Methodological Approach
EMAC+ employs a modular structure combining visual and language processing for robust task execution:
- Visual Encoding with VLM: Utilizes a Vision Transformer (ViT) and Q-Former to encode visual inputs. This is followed by transformer-based alignment of visual features and text embeddings, driving action generation.
- Bidirectional Training Paradigm: LLM dynamically adjusts plans through interactions with VLM, enabling real-time response adaptations based on environment feedback. This synergy accelerates learning and action precision in complex robotic tasks.
- Closed-loop Planning: Integrates continuous feedback from visual executions, allowing LLMs to internalize environment specifics, eschewing reliance on pre-collected static datasets. Algorithm 1 details this interactive, adaptive learning strategy.
- Textual State Translation: Employs PDDL to convert visual observations into structured textual descriptions, facilitating symbolic reasoning while retaining critical action semantics.
Experimental Validation
Extensive evaluations on ALFWorld and RT-1 benchmarks showcase EMAC+'s superior performance in task completion, robustness, and efficiency metrics. Tables detail comparative analyses against state-of-the-art baseline models in both textual and visual environments:
- ALFWorld Performance: EMAC+ consistently outperformed state-of-the-art vision-LLMs due to efficient utilization of environmental dynamics and LLM planning expertise (Table 1).
- RT-1 Task Efficiency: Demonstrated notable success across planning, manipulation, and motion tasks, showcasing enhanced adaptability and generalization to out-of-distribution environments (Tables 2-4).
- Ablation Studies: Various ablation setups illustrate the critical components contributing to EMAC+'s performance, such as re-planning capabilities and loss function effectiveness (Figure 2).
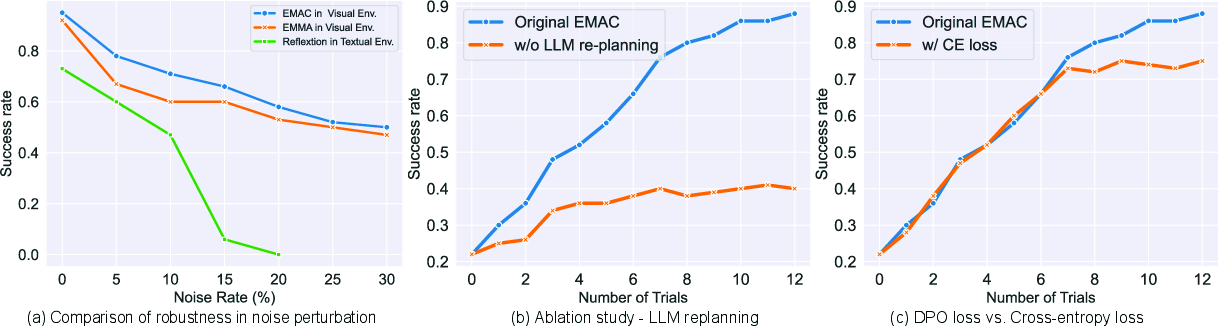
Figure 2: Ablation Studies in ALFWorld comparing robustness and planning efficiency.
Implications and Future Directions
The adaptive capabilities of EMAC+ represent significant strides toward more intelligent embodied agents. By coupling symbolic reasoning with real-time visual data, EMAC+ enhances the precision of robotic control tasks. Future explorations could focus on integrating real-world robotic applications to expand the agent's practical utility, further bridging semantic and embodiment gaps within AI systems.
Conclusion
EMAC+ redefines multi-modal agent design by embracing a collaborative and adaptive planning framework, employing advanced LLM and VLM integrations to enhance task execution robustness and efficiency. Though challenges remain in highly dynamic environments, EMAC+ sets a foundational approach for developing resilient, generalizable agents capable of learning and adapting through interactive experiences.

