MorphBPE: A Morpho-Aware Tokenizer Bridging Linguistic Complexity for Efficient LLM Training Across Morphologies
Abstract: Tokenization is fundamental to NLP, directly impacting model efficiency and linguistic fidelity. While Byte Pair Encoding (BPE) is widely used in LLMs, it often disregards morpheme boundaries, leading to suboptimal segmentation, particularly in morphologically rich languages. We introduce MorphBPE, a morphology-aware extension of BPE that integrates linguistic structure into subword tokenization while preserving statistical efficiency. Additionally, we propose two morphology-based evaluation metrics: (i) Morphological Consistency F1-Score, which quantifies the consistency between morpheme sharing and token sharing, contributing to LLM training convergence, and (ii) Morphological Edit Distance, which measures alignment between morphemes and tokens concerning interpretability. Experiments on English, Russian, Hungarian, and Arabic across 300M and 1B parameter LLMs demonstrate that MorphBPE consistently reduces cross-entropy loss, accelerates convergence, and improves morphological alignment scores. Fully compatible with existing LLM pipelines, MorphBPE requires minimal modifications for integration. The MorphBPE codebase and tokenizer playground will be available at: https://github.com/LLM-lab-org/MorphBPE and https://tokenizer.LLM-lab.org

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MorphBPE: A simple explanation
What is this paper about?
This paper is about a better way to break text into pieces so that LLMs can learn from it more efficiently. That step is called “tokenization.” The authors propose a new tokenizer called MorphBPE that pays attention to how words are built from meaningful parts (called morphemes) like “un-,” “happy,” and “-ness” in “unhappiness.” This matters a lot for languages where words are formed in complex ways, such as Arabic and Hungarian.
What questions did the researchers ask?
In simple terms, they asked:
- Can we design a tokenizer that respects the meaningful parts of words (morphemes) without slowing down training?
- Will this help LLMs learn faster and make fewer mistakes during training?
- How can we measure whether a tokenizer keeps word pieces meaningful and consistent?
How did they do it?
Think of tokenization like breaking words into LEGO pieces. Standard methods often split words into pieces based on what shows up most often across a huge dataset, which is fast but sometimes chops words in confusing places. For example, in Arabic some words are built by weaving a root (like R-H-M, related to mercy) into a pattern; a “greedy” splitter might slice across that root and pattern, losing the meaningful structure.
- What is BPE?
- Byte Pair Encoding (BPE) merges frequent letter or subword pairs to make common pieces. It’s popular because it keeps vocabulary size manageable and works well in many cases.
- Problem: BPE doesn’t know where morphemes begin or end, so it can create pieces that don’t match the true building blocks of words—especially in complex languages.
- What is MorphBPE?
- MorphBPE is almost the same as BPE, but with one important rule: when it merges pieces, it’s not allowed to merge across morpheme boundaries. In other words, it keeps the LEGO blocks that carry meaning intact.
- Because it keeps everything else the same, it fits easily into existing LLM training pipelines.
- How did they test it?
- Languages: English (simpler word-building), Russian (moderate), Hungarian (very complex, many endings stuck onto roots), and Arabic (root-and-pattern system).
- Data: They used carefully prepared datasets that show where morphemes are in each word.
- Models: They trained two sizes of LLMs (about 300 million and 1 billion parameters) using the same text with either standard BPE or MorphBPE.
- New measurements they introduced:
- Morphological Edit Distance: How many “fixes” are needed to line up the tokenizer’s pieces with the true morphemes? Fewer fixes = better alignment.
- Morphological Consistency F1-Score: Do words that share the same morpheme also share the same token piece, and vice versa? Higher scores = more consistent, which helps the model learn patterns.
- They also watched training cross-entropy loss, which you can think of as “how surprised the model is when guessing the next word.” Lower loss means better learning.
What did they find, and why is it important?
- Better alignment with real word parts:
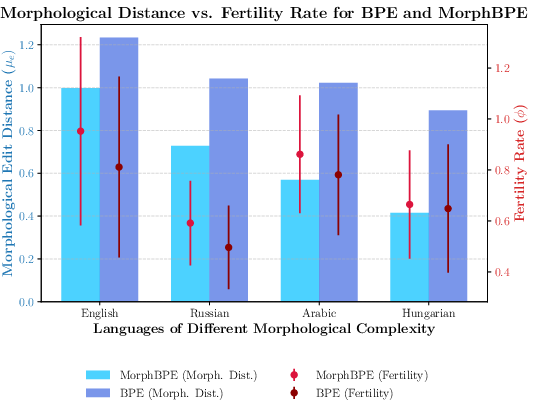
- MorphBPE split words in ways that matched morphemes more closely than standard BPE across all four languages.
- This was especially true in complex languages like Hungarian and Arabic, where word structure matters a lot.
- More consistent pieces:
- MorphBPE scored much higher on the Morphological Consistency F1-Score. In simple terms, it reused the same token piece for the same morpheme across different words more reliably. That reduces confusion for the model.
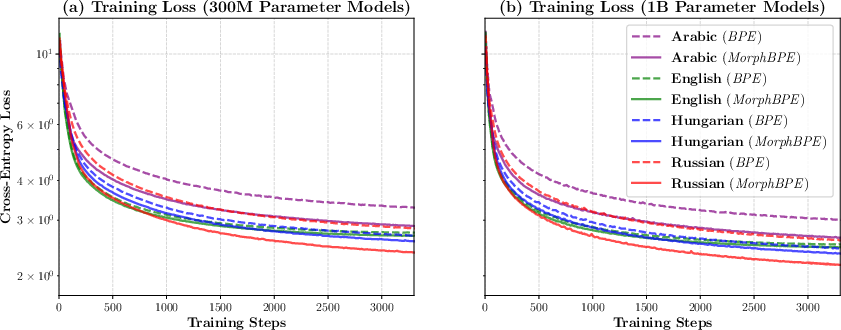
- Faster and better learning:
- In both the smaller (300M) and larger (1B) models, MorphBPE led to lower training loss (the model was less “surprised”), and it converged faster. That means the model learned patterns more efficiently.
- This improvement showed up even in English, but it was largest in morphologically rich languages like Hungarian and Arabic.
- A small trade-off:
- Sometimes MorphBPE used slightly more tokens per word (called “fertility”), because it keeps morphemes intact instead of merging across them. Despite that, overall training still improved—showing that “fewer tokens” isn’t always the best goal if those tokens don’t respect word meaning.
Why does this matter?
- Fairer, smarter training across languages:
- Many tokenizers are tuned to languages like English. MorphBPE helps LLMs learn languages with complex word-building systems more fairly and effectively.
- More interpretable:
- Because tokens line up with real word parts, it’s easier to understand what the model is learning.
- Easy to adopt:
- MorphBPE works like BPE with a small extra rule, so it can be added to existing training setups with minimal changes.
- Real-world use:
- The team reports using MorphBPE in Fanar, an Arabic-focused model, and saw gains in performance.
Limitations and what’s next
- MorphBPE needs data that marks morpheme boundaries to train the tokenizer well, and not every language has that data available yet.
- This study focused on “intrinsic” measures (how the tokenizer itself behaves and how training loss changes). A next step is more “extrinsic” testing—checking how much MorphBPE improves real tasks like translation, question answering, or summarization.
- Expanding to more languages will help confirm how broadly the benefits apply.
Bottom line
MorphBPE is a small change with a big impact: it keeps the meaningful building blocks of words intact while training LLMs. That leads to clearer, more consistent tokens, faster learning, and better performance—especially for languages where word structure carries a lot of meaning.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The paper establishes MorphBPE’s promise but leaves several concrete questions and limitations for future work to address:
- External evaluation gap: No extrinsic, task-level assessments (e.g., MT, QA, summarization, reasoning, morphology-sensitive tasks) to verify that intrinsic gains and lower training loss translate into consistent downstream performance improvements.
- Baseline coverage: Missing comparisons against strong alternative tokenizers beyond vanilla BPE (e.g., unigram/WordPiece, SentencePiece byte-level, Morfessor-based or morphology-aware pre-tokenization, BPE-dropout, sampling-based BPE); unclear whether MorphBPE outperforms these on the same setups.
- Scalability to larger LLMs: Only 300M and 1B models are tested; unknown whether benefits persist, diminish, or grow at 7B–70B+ scales and at larger pretraining budgets.
- Multilingual joint vocabulary: All experiments appear monolingual; open whether MorphBPE helps or hurts cross-lingual token sharing, alignment, and performance when building a single multilingual vocabulary.
- Compute/throughput trade-offs: Higher fertility is reported but there is no measurement of training/inference throughput, wall-clock convergence time, memory footprint, embedding size overhead, or compute-per-character/byte—leaving net efficiency gains ambiguous.
- Context-length implications: More tokens per sequence may reduce effective context (for fixed maximum tokens); the impact on long-context tasks and memory/compute costs is unquantified.
- Robustness to segmentation noise: The method relies on morphological segmentation during tokenizer training (including 1M automatically segmented Arabic forms); there is no analysis of how segmentation errors or inconsistencies affect learned merges and downstream performance.
- Resource dependence: Many languages lack high-quality morphological segmenters; there is no strategy for low-/zero-resource settings (e.g., weak supervision, self-supervised/unsupervised segmentation, transfer from related languages).
- Non-concatenative morphology handling: The approach prohibits merges across linear morpheme boundaries, but templatic/root-and-pattern morphology is inherently non-linear; it remains unclear how well linear boundary constraints capture interdigitated morphemes or whether specialized representations are needed.
- Domain and register transfer: Vocabulary and merges are learned on specific corpora; generalization to new domains/genres (e.g., social media, technical text) with different morphological distributions is untested.
- Fairness and dialectal variation: No analysis of how MorphBPE handles dialects, code-switching, or minority morphological variants; risk of entrenching biases from segmentation resources is unassessed.
- Vocabulary-size selection in practice: Optimal sizes are chosen via morphology-distance on dev sets with gold segmentations; it is unclear how to choose vocabulary size when segmentation is unavailable or noisy.
- Metric formalization and sensitivity: The Morphological Edit Distance and Consistency F1 are not fully formalized (e.g., exact alignment/scoring, normalization), and their sensitivity to hyperparameters (k-means settings, pair-sampling strategy) is not evaluated.
- Correlation with downstream outcomes: The extent to which the new morphological metrics predict downstream task quality or user-facing performance is unknown.
- Statistical rigor of training results: Reported training-loss improvements lack variance across multiple seeds/runs and statistical significance tests; robustness to optimization hyperparameters is not shown.
- Tokenizer behavior on non-morphological content: Treatment of numbers, punctuation, code, URLs, emojis, and mixed-script text under MorphBPE is not analyzed.
- Languages beyond the sample: Evaluation omits typologies such as compounding-dominant (e.g., German), clitic-rich Romance languages, isolating/Sinitic languages (Chinese, Vietnamese), and morphologically extreme cases (e.g., Inuktitut); potential negative or neutral effects remain unknown.
- Sequence-length vs. loss trade-off: While cross-entropy decreases, more tokens may increase total compute per character/byte; a controlled comparison on equal character/byte budgets is missing.
- Ablation studies: No ablations on (i) segmentation quality/coverage, (ii) partially relaxed boundary constraints (soft penalties vs. hard prohibition), (iii) effects of different normalization/cleaning pipelines (e.g., Arabic diacritics), or (iv) removing clustering in metric computation.
- Interaction with byte-level/character models: It remains unexplored whether MorphBPE still helps when models operate at or near the byte/character level, or how to integrate morphological constraints with byte-level tokenization.
- Rare/novel morphology: No breakdown of performance on rare affixes, long derivations, or unseen morphological combinations—key for generalization in agglutinative/templatic languages.
- Cross-lingual transfer of morphological knowledge: Whether morphological constraints learned in one language benefit related languages (e.g., cross-Slavic, cross-Semitic) in multilingual or transfer-learning settings is untested.
- Practical deployment costs: The overhead and engineering complexity of training MorphBPE (e.g., morphological preprocessing, merge computation) versus standard BPE is not quantified; reproducibility awaits public code and complete metric definitions.
- Tokenizer-induced biases in evaluation: Fertility is compared to BLOOMZ for context, but intrinsic metrics are not computed for large-vocab baselines; fairness of comparisons across differing vocabularies and training corpora is unclear.
- Impact on generation behavior: Potential changes in morphological fidelity, error patterns (e.g., hallucinated inflections), and interpretability during generation are not analyzed.
Practical Applications
Immediate Applications
Below are concrete ways the paper’s findings and methods can be used now, with links to sectors, suggested tools/products/workflows, and feasibility notes.
- MorphBPE integration for LLM pretraining and finetuning in morphologically rich languages — sectors: software/AI, multilingual products
- What: Replace vanilla BPE with MorphBPE in training pipelines for Arabic, Hungarian, Russian, etc., to reduce cross-entropy and accelerate convergence.
- Tools/workflows: Integrate MorphBPE into tokenization stage (e.g., Hugging Face Tokenizers/Tokenizers-fast plugin), select vocabulary size via the paper’s morphology-distance heuristic, and re-train/finetune models.
- Assumptions/dependencies: Availability of morphological segmentation for target language; code release/license terms (provisional patent noted); compute budget for re-tokenization and training.
- Lower training cost and carbon footprint via faster convergence — sectors: cloud/AI infrastructure, energy
- What: Use MorphBPE to reach target loss with fewer tokens/steps for morphologically complex languages, reducing training time and energy.
- Tools/workflows: Track training curves; stop earlier at equivalent loss; integrate into MLOps cost dashboards.
- Assumptions/dependencies: Gains may vary by domain and model size; energy savings require real-world measurement; vocab sizes must be tuned.
- Quality gains in Arabic-centric and other high-morphology products — sectors: search, chatbots, assistants, ASR/NLU, translation
- What: Improve tokenization for Arabic/Hungarian/Russian models powering chatbots, semantic search, ASR LLMs, and NMT.
- Tools/workflows: Swap tokenizers and re-index (IR), retrain LLMs for ASR rescoring, retrain/finetune NMT; evaluate with in-house metrics plus proposed morphology metrics.
- Assumptions/dependencies: Requires re-training or at least re-embedding; downstream task gains, while likely, are to be validated extrinsically.
- Tokenizer evaluation dashboards using morphology-aware metrics — sectors: academia, industry R&D, responsible AI
- What: Add Morphological Consistency F1 and Morphological Edit Distance to tokenizer selection/evaluation, alongside fertility and throughput.
- Tools/workflows: Build CI dashboards that compute pc and pe on held-out segmented datasets; A/B compare tokenizers before large-scale training.
- Assumptions/dependencies: Segmentation data for evaluation must exist for target languages; standardization of implementations desirable.
- Vocabulary size selection guided by morphology distance — sectors: LLM research/engineering
- What: Use the paper’s morphology-distance-driven method to pick smaller vocab sizes beyond which returns diminish, rather than relying on heuristics.
- Tools/workflows: Grid over vocab sizes; compute development-set morphology distance; select minimal size with no significant improvement beyond it.
- Assumptions/dependencies: Statistical testing requires adequate dev data; generalizes best to languages with reliable segmentations.
- Data curation pipelines for morphological segmentation — sectors: data engineering, multilingual AI
- What: Build/augment segmented corpora by combining task-specific datasets (e.g., SIGMORPHON) and analyzers (Farasa, Morfessor) for training/evaluation.
- Tools/workflows: Automatic segmentation with confidence thresholds; consistent cleaning/normalization; training/dev/test splits as in paper.
- Assumptions/dependencies: Segmenter availability and accuracy; licensing of datasets and tools.
- Model interpretability and training stability monitoring — sectors: responsible AI, safety/compliance
- What: Use morphological consistency to detect tokenization drift or instability during incremental vocabulary updates or domain adaptation.
- Tools/workflows: Log pc and pe alongside loss; set alerts for sharp drops; tie to rollback/retune processes.
- Assumptions/dependencies: Correlation to downstream harms not yet fully established; thresholds require empirical calibration.
- Procurement and QA benchmarking for public-sector/NGO multilingual tools — sectors: policy, govtech
- What: Include morphology-aware metrics in acceptance criteria for AI systems serving Arabic, Russian, etc., to ensure equitable performance.
- Tools/workflows: Vendor test suites with pc/pe score thresholds per language; publish evaluation reports.
- Assumptions/dependencies: Acceptance of metrics by stakeholders; availability of evaluation datasets for relevant dialects/languages.
- Domain finetuning for legal/medical in Russian/Arabic — sectors: healthcare, finance/legal tech
- What: Retokenize domain corpora with MorphBPE before finetuning to better handle inflectional variants and derivational families.
- Tools/workflows: Rebuild tokenizers with domain text and morphology data; evaluate perplexity and task metrics (e.g., NER, QA).
- Assumptions/dependencies: Domain morphology coverage; privacy/compliance for sensitive data; need for extrinsic validation.
- Information retrieval and indexing improvements — sectors: enterprise search, e-discovery
- What: Use MorphBPE to create more semantically consistent tokens for indexing morphologically rich languages, improving recall/precision.
- Tools/workflows: Re-index with MorphBPE-based terms; adjust analyzers in Elasticsearch/Solr; test BM25 and neural retrievers.
- Assumptions/dependencies: Migration requires re-indexing and possible analyzer changes; gains need task-level A/B testing.
Long-Term Applications
These opportunities require additional research, scaling, or ecosystem development before broad deployment.
- Broad language coverage via (weakly-)supervised or unsupervised morphology — sectors: NLP research, global products
- What: Extend MorphBPE to dozens/hundreds of languages by learning segmentations from limited supervision or unsupervised methods.
- Tools/workflows: Train morphology induction models; semi-automatic validation pipelines; community curation.
- Assumptions/dependencies: Quality of induced segmentations; resources for annotation; variability across language families.
- Dynamic/adaptive morphology-aware tokenizers — sectors: software/AI, robotics
- What: Tokenizers that adapt morpheme boundaries online for new domains/dialects without retraining from scratch.
- Tools/workflows: Streaming segmentation; constrained merge rules; continual learning for tokenizers.
- Assumptions/dependencies: Stability vs. adaptability trade-offs; integration with cached embeddings and deployed models.
- Hybrid tokenization with byte/char/tokenization-free models — sectors: foundational model R&D
- What: Combine MorphBPE with byte-level or tokenization-free architectures to get robustness across scripts and morphology.
- Tools/workflows: Mixture-of-tokenizers; routing by language/domain; joint training objectives.
- Assumptions/dependencies: Complexity of training; unclear best practices for fusion; hardware/memory constraints.
- Standard-setting for multilingual fairness and accessibility — sectors: policy, standards bodies
- What: Adopt morphology-aware tokenizer metrics in public procurement and standards (e.g., for education/health services in complex languages).
- Tools/workflows: Publish benchmarks and minimum thresholds; certification programs for language coverage.
- Assumptions/dependencies: Consensus on metric thresholds; alignment with broader AI audit frameworks.
- Consumer text input and assistive technologies — sectors: mobile/OS, accessibility
- What: Morphology-aware predictive keyboards, autocorrect, and smart compose for Arabic, Turkish, Hungarian, etc.
- Tools/workflows: On-device MorphBPE tokenization; compression/distillation for edge hardware; personalization layers.
- Assumptions/dependencies: Efficient on-device implementations; privacy constraints; UX validation.
- Clinical and biomedical NLP in morphologically rich languages — sectors: healthcare
- What: More accurate extraction, summarization, and coding from EHRs and clinical notes in Arabic/Russian.
- Tools/workflows: Retokenize and finetune clinical LMs; validate on de-identified datasets; integrate with hospital IT.
- Assumptions/dependencies: Data access and de-identification; regulatory approvals; stringent extrinsic evaluation.
- Financial/legal document analysis — sectors: finance, legal tech
- What: Better handling of inflected/derived terms in contracts, regulations, and disclosures for non-English languages.
- Tools/workflows: MorphBPE-based pretraining/finetuning; compliance QA pipelines; document retrieval improvements.
- Assumptions/dependencies: Domain corpora with segmentation; explainability requirements for audits.
- At-scale energy and cost reductions for multilingual foundation models — sectors: cloud/AI infrastructure, sustainability
- What: Material reductions in training energy by using MorphBPE across all high-morphology languages in massive corpora.
- Tools/workflows: Large-scale A/B training; standardized energy metering; green AI reporting.
- Assumptions/dependencies: Consistency of convergence gains across larger scales; coordination across teams and languages.
- Cross-lingual transfer and low-resource uplift — sectors: academia, global AI
- What: Use improved morpheme-token consistency to enhance transfer between related languages and bolster low-resource performance.
- Tools/workflows: Multi-task and multilingual training with shared MorphBPE; evaluate zero-/few-shot gains.
- Assumptions/dependencies: Choice of language clusters; robustness of shared subword representations.
- SaaS/tokenizer platform and ecosystem integrations — sectors: developer tools, MLOps
- What: Commercial/open-source services providing MorphBPE training, metrics computation, and deployment integrations (e.g., Hugging Face, OpenXLA).
- Tools/workflows: APIs/SDKs, training UIs, evaluation dashboards, CI plugins.
- Assumptions/dependencies: Licensing/patent landscape; community adoption; long-term maintenance.
- Multimodal and speech systems — sectors: ASR, OCR, multimodal AI
- What: Integrate morphology-aware tokenization into text components of ASR/OCR pipelines and multimodal LMs to reduce OOV and improve alignment.
- Tools/workflows: Joint training (acoustic-to-text with MorphBPE text LM); OCR post-processing with morphology constraints.
- Assumptions/dependencies: Coordination across modalities; retraining costs; mixed-script challenges.
- Educational technology and curricula — sectors: education, edtech policy
- What: Leverage morpheme-aligned tokenization to build tutoring systems that teach morphology and vocabulary families more effectively.
- Tools/workflows: Morph-aware content generation; student modeling by morpheme mastery.
- Assumptions/dependencies: Pedagogical validation; localization for curricula; accessibility requirements.
Notes on feasibility across applications:
- Dependency on segmentation resources: MorphBPE’s benefits hinge on access to accurate morphological segmentation (or reliable induction methods). Coverage varies by language.
- Fertility vs. efficiency: MorphBPE may increase token count (fertility) but still improve training efficiency; downstream latency/throughput trade-offs need measurement per application.
- Extrinsic validation: While training loss improvements are robust, task-level gains should be validated for each use case.
- Licensing and IP: A provisional patent is noted; commercial adopters should confirm licensing terms.
- Pipeline compatibility: The method is designed to be drop-in compatible with existing BPE-based LLM pipelines, reducing integration risk.
Glossary
- Affixation: The process of adding prefixes, suffixes, infixes, or other morphemes to a root to express grammatical or semantic changes. "as their highly productive affixation processes complicate adherence to morpheme boundaries"
- Agglutinative (language type): A morphological type where words are formed by stringing together many morphemes, each typically expressing a single grammatical meaning. "Similar challenges arise in agglutinative and polysynthetic languages, where BPE's greedy merging strategy often fails to align with true morpheme boundaries."
- Bootstrapping procedure: A resampling method used to estimate statistics (e.g., precision/recall) by repeatedly sampling from data with replacement. "Precision and recall are estimated through a bootstrapping procedure, drawing N = 10 resamples from clusters."
- Branching factor: In language modeling, the effective number of choices (next-token options), influenced by vocabulary size. "vocabulary variations directly affect the model's branching factor."
- Byte Pair Encoding (BPE): A subword tokenization algorithm that iteratively merges the most frequent adjacent symbol pairs to build a vocabulary. "still rely on Byte Pair Encoding (BPE)-based tokenization for most languages,"
- Byte-level tokenization: Tokenization methods that operate directly on bytes instead of characters or words to improve robustness across scripts. "Standard BPE and byte-level tokeniza- tion methods often struggle to represent these com- plex morphological patterns effectively,"
- BPE dropout: A stochastic variant of BPE that randomly drops merge rules during training to improve generalization. "including BPE dropout (Provilkov et al., 2020), which introduces stochasticity to im- prove generalization,"
- Chinchilla scaling law: A guideline for compute-optimal training that balances model size and number of training tokens for best performance given fixed compute. "following the Chinchilla scaling law (Hoffmann et al., 2022)."
- Concatenative morphology: A morphological system where morphemes are linearly concatenated to form words. "The additive nature of Byte Pair Encoding (BPE) makes it well-suited for concatenative morphol- ogy, as seen in English,"
- Cross-entropy loss: A training objective measuring the divergence between predicted and true distributions; lower values indicate better next-token prediction. "Cross-entropy loss in language modeling mea- sures the divergence between predicted and ground truth outputs."
- Decoder architectures: Neural network architectures (e.g., transformer decoders) that generate outputs autoregressively from learned representations. "To assess the scalability of our approach, we trained two model sizes—300M (small) and 1B (large)—using decoder architectures within the LLaMA-Factory framework"
- Dynamic programming: An algorithmic technique that solves problems by breaking them into overlapping subproblems and storing intermediate results. "This metric is computed using a pairwise alignment score based on dynamic programming,"
- Extrinsic evaluation: Assessment of a component (e.g., tokenization) based on its impact on downstream tasks or overall model performance. "Extrinsic evaluation assesses tokenizers in the broader context of LLM performance across diverse capabilities,"
- Fertility (tokenization): The number of tokens produced by a tokenizer relative to a baseline; lower fertility often implies more compact representations. "Fertility quantifies the number of tokens generated by a tokenizer relative to a base- line,"
- Fusional (morphology type): A type of morphology where a single morpheme can express multiple grammatical meanings at once. "Russian: Fusional, moderate complexity"
- Greedy merging strategy: The BPE approach of always merging the currently most frequent pair without considering broader linguistic structure. "vanilla BPE has several notable limitations: its greedy merg- ing strategy,"
- Infixation: A morphological process inserting an affix within a root or stem rather than at the beginning or end. "where meaning is encoded through non-linear in- fixation (Khaliq and Carroll, 2013)."
- Intrinsic evaluation: Assessment using task-independent metrics that measure core properties (e.g., alignment with morphology) of a component in isolation. "Therefore, we focus on intrinsic evaluation metrics that provide insights into the core characteristics of tokenization"
- K-means clustering: An unsupervised learning method that partitions data into k clusters by minimizing within-cluster variance. "we employ k-means clustering (k = 100) to group words with similar morphemes"
- MorphBPE: A morphology-aware extension of BPE that prevents merges across morpheme boundaries while preserving BPE’s statistical efficiency. "MorphBPE is a simple yet effective extension of BPE that prevents frequent symbol pair merges from crossing morpheme boundaries"
- Morpheme: The smallest meaningful unit in a language’s morphology, such as roots and affixes. "its segmentation often disregards meaningful morpheme boundaries"
- Morphological Consistency F1-Score: A metric measuring whether words sharing morphemes share tokens (recall) and whether shared tokens imply shared morphemes (precision). "Morpho- logical Consistency F1-Score, which quanti- fies the consistency between morpheme shar- ing and token sharing,"
- Morphological edit distance: An alignment-based metric that quantifies how closely tokenization boundaries align with gold morpheme boundaries. "we intro- duce a new intrinsic evaluation metric, the morpho- logical edit distance, which assesses how well tok- enization aligns with the underlying morphological segmentation of words."
- Morphological segmentation: The process of splitting words into constituent morphemes according to linguistic analysis. "Segment the training corpus using morphological segmen- tation"
- Pairwise alignment: A method of aligning two sequences (e.g., tokens and morphemes) to evaluate correspondence. "This metric is computed using a pairwise alignment score based on dynamic programming,"
- Perplexity: A measure of how well a probability model predicts a sample; lower perplexity indicates better language modeling. "This metric is closely related to model perplexity,"
- Polysynthetic (language type): Languages characterized by very complex word forms that encode extensive grammatical information within single words. "Similar challenges arise in agglutinative and polysynthetic languages, where BPE's greedy merging strategy often fails"
- Root-and-pattern morphology: A non-concatenative system (common in Semitic languages) forming words by interleaving roots with vocalic/templatic patterns. "non- concatenative morphological systems, such as root- and-pattern morphology in Arabic and Hebrew,"
- Subword tokenization: Breaking words into smaller units (subwords) to handle rare words and capture frequent patterns in NLP models. "integrates linguistic structure into subword tokenization while preserving statistical effi- ciency."
- Surface form: The actual word form as it appears in text, as opposed to its underlying morphological or lexical representation. "to provide adequate context for each surface form."
- Templatic morphology: A morphological system where words are formed by applying vocalic templates to consonantal roots. "Arabic: Templatic, high complexity"
- Tokenization-free architectures: Models that avoid explicit tokenization by operating directly on raw byte/character streams or learned representations. "tokenization- free architectures have been investigated as poten- tial alternatives"
- Whitespace-based tokenizer: A baseline tokenizer that segments text at spaces, treating each whitespace-delimited chunk as a token. "relative to a base- line, typically a whitespace-based tokenizer (Rust et al., 2021)."
Collections
Sign up for free to add this paper to one or more collections.