SD-LoRA: Scalable Decoupled Low-Rank Adaptation for Class Incremental Learning
Abstract: Continual Learning (CL) with foundation models has recently emerged as a promising paradigm to exploit abundant knowledge acquired during pre-training for tackling sequential tasks. However, existing prompt-based and Low-Rank Adaptation-based (LoRA-based) methods often require expanding a prompt/LoRA pool or retaining samples of previous tasks, which poses significant scalability challenges as the number of tasks grows. To address these limitations, we propose Scalable Decoupled LoRA (SD-LoRA) for class incremental learning, which continually separates the learning of the magnitude and direction of LoRA components without rehearsal. Our empirical and theoretical analysis reveals that SD-LoRA tends to follow a low-loss trajectory and converges to an overlapping low-loss region for all learned tasks, resulting in an excellent stability-plasticity trade-off. Building upon these insights, we introduce two variants of SD-LoRA with further improved parameter efficiency. All parameters of SD-LoRAs can be end-to-end optimized for CL objectives. Meanwhile, they support efficient inference by allowing direct evaluation with the finally trained model, obviating the need for component selection. Extensive experiments across multiple CL benchmarks and foundation models consistently validate the effectiveness of SD-LoRA. The code is available at https://github.com/WuYichen-97/SD-Lora-CL.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching an AI to keep learning new things over time without forgetting what it already knows. The authors introduce a new way, called S-LoRA, to help big pre-trained models (often called “foundation models”) learn new classes step by step while remembering old ones, and to do this efficiently.
What questions are the researchers asking?
They focus on a few simple questions:
- How can an AI learn new classes (like new animal types) one after another without forgetting earlier ones?
- Can we avoid storing old training examples (which takes space and can be impractical)?
- Can we avoid a slow and complicated “prompt selection” step during testing and still get great results?
- Is there a simple, scalable way to adapt big models that works well across many tasks and datasets?
How did they approach the problem?
Think of the model as a traveler trying to find a good spot on a landscape where “low places” mean low error (good performance). Every time it learns a new task, it moves a bit in that landscape.
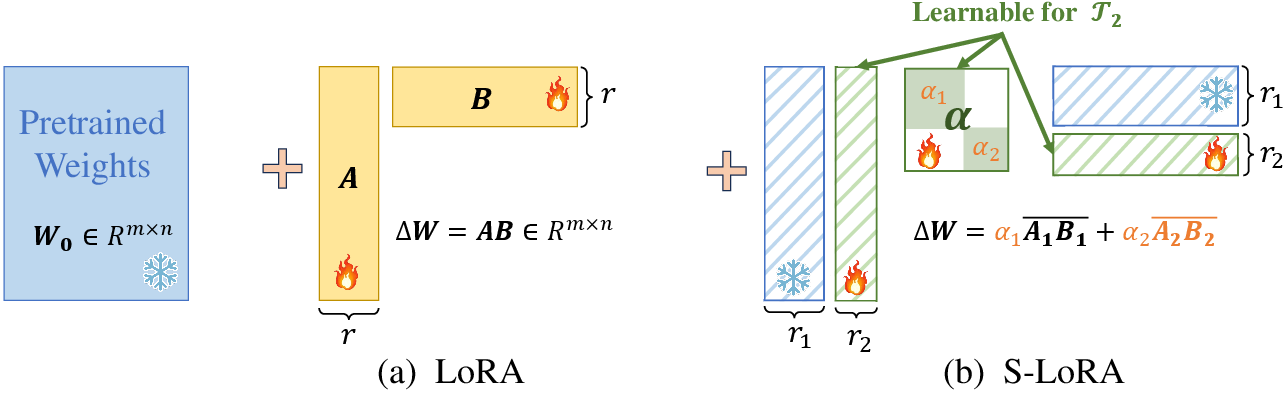
- What is LoRA? Low-Rank Adaptation (LoRA) is like attaching small “adapter pieces” to a big model so you adjust only a few parts instead of changing everything. That makes learning faster and safer.
- Direction vs. magnitude (an everyday analogy):
- Direction = where to go (the arrow’s direction).
- Magnitude = how far to move (how long the arrow is).
- What is S-LoRA? The authors split (decouple) these two ideas. As the model learns new tasks:
- It keeps the “directions” it learned before (the important arrows it discovered earlier).
- It mainly adjusts how much to use each direction (the magnitudes), instead of constantly inventing brand-new directions.
- It adds a new direction only when needed for a brand-new task.
- Why this helps: Reusing good directions helps the model follow a “low-loss path” through the landscape that works for many tasks at once, instead of zig-zagging and forgetting old tasks.
They also propose two more efficient versions:
- ES-LoRA1 (Dynamic Rank): Use big adapters early on and smaller ones later, because early directions matter more; later ones are tiny tweaks.
- ES-LoRA2 (Knowledge Distillation): If a new direction is very similar to a mix of old ones, just reuse and re-weight the old ones instead of adding a new piece.
Importantly, S-LoRA does not need to store old examples (rehearsal-free), and it does not need a slow prompt-choosing step at test time. You can directly use the final model for testing.
What did they find, and why does it matter?
Here are the main findings in simple terms:
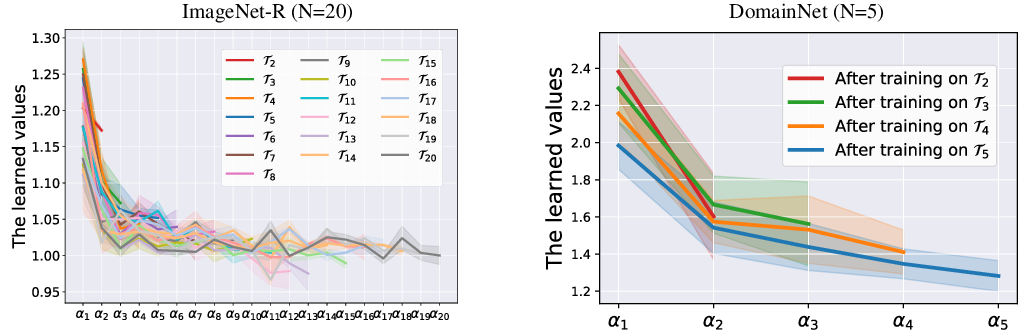
- Many tasks share common “good directions”: The best settings for different tasks are closer to each other than to the original base model. That means earlier learned directions are widely useful.
- Early directions are the most important: As the model learns more tasks, it reuses the first few directions a lot. Later directions help, but usually as small adjustments.
- A shared sweet spot: By mainly adjusting how much to use each direction (magnitude) instead of constantly changing direction, the model travels a smooth path to a shared “low-error region” that works for many tasks. This gives a good balance between remembering old things (stability) and learning new things (plasticity).
- Strong results across benchmarks: On several datasets (like ImageNet-R, ImageNet-A, and DomainNet), S-LoRA consistently beats previous methods (like L2P, DualPrompt, Coda-Prompt, HidePrompt, and InfLoRA). It works well even with different backbone models, including self-supervised ones.
- Faster and more scalable: Because S-LoRA skips the prompt-selection step at test time and doesn’t store old examples, it’s simpler and more efficient to use in the long run.
Why is this important?
- Practical continual learning: S-LoRA shows how to keep improving AI models over time without needing to keep piles of old data and without complicated testing steps.
- Better memory and learning balance: It handles the classic problem of “learn new stuff but don’t forget the old” by following a steady, shared path that works for multiple tasks.
- More sustainable AI: Using small adapter updates and reusing earlier directions makes training and deployment lighter, faster, and easier to scale to many tasks.
In short
S-LoRA is like teaching an AI to reuse the best “moves” it learned early on and only adjust how strongly to use them for each new topic. That simple idea helps it learn new classes well, remember old ones, run faster during testing, and avoid saving old data—making it a strong, practical approach for continual learning.
Collections
Sign up for free to add this paper to one or more collections.

