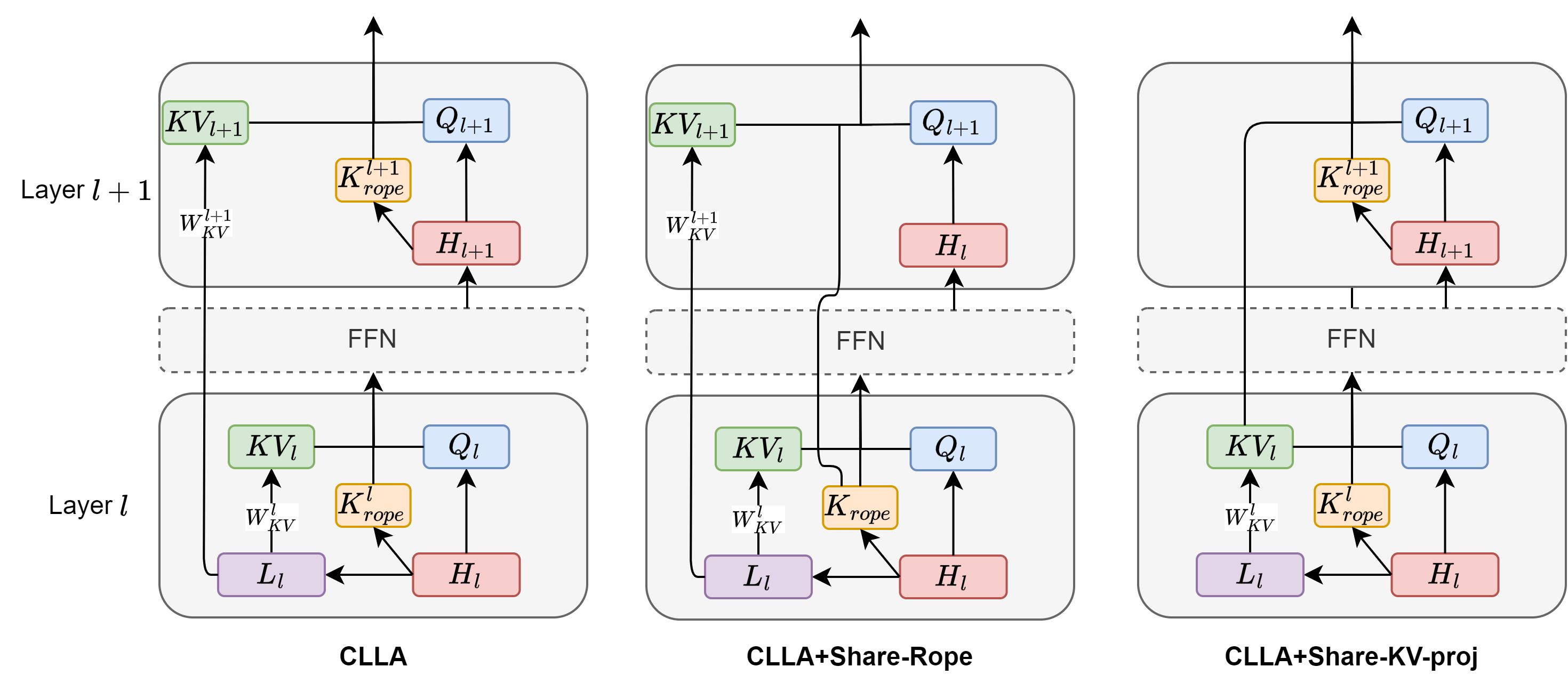
- The paper presents a novel CLLA framework that reduces KV cache memory usage to 2% without losing model performance.
- It employs attention head reduction, layer sharing, and int4 quantization to efficiently compress latent KV pairs.
- Experimental results across English and Chinese benchmarks validate the method’s efficiency for inference in large language models.
Lossless KV Cache Compression to 2%
The paper "Lossless KV Cache Compression to 2%" presents a sophisticated method for compressing key-value (KV) caches within LLMs to a mere 2% of their original size while maintaining comparable performance levels. This is achieved through the introduction of the Cross-Layer Latent Attention (CLLA) architecture. Below, I provide a comprehensive technical overview of the methodology, implications, and possible future directions.
CLLA Architecture Overview
The CLLA architecture integrates multiple KV cache compression techniques into a unified framework, including attention head/dimension reduction, layer sharing, and quantization techniques. The primary feature of this architecture is its ability to maintain performance while significantly reducing memory overhead.
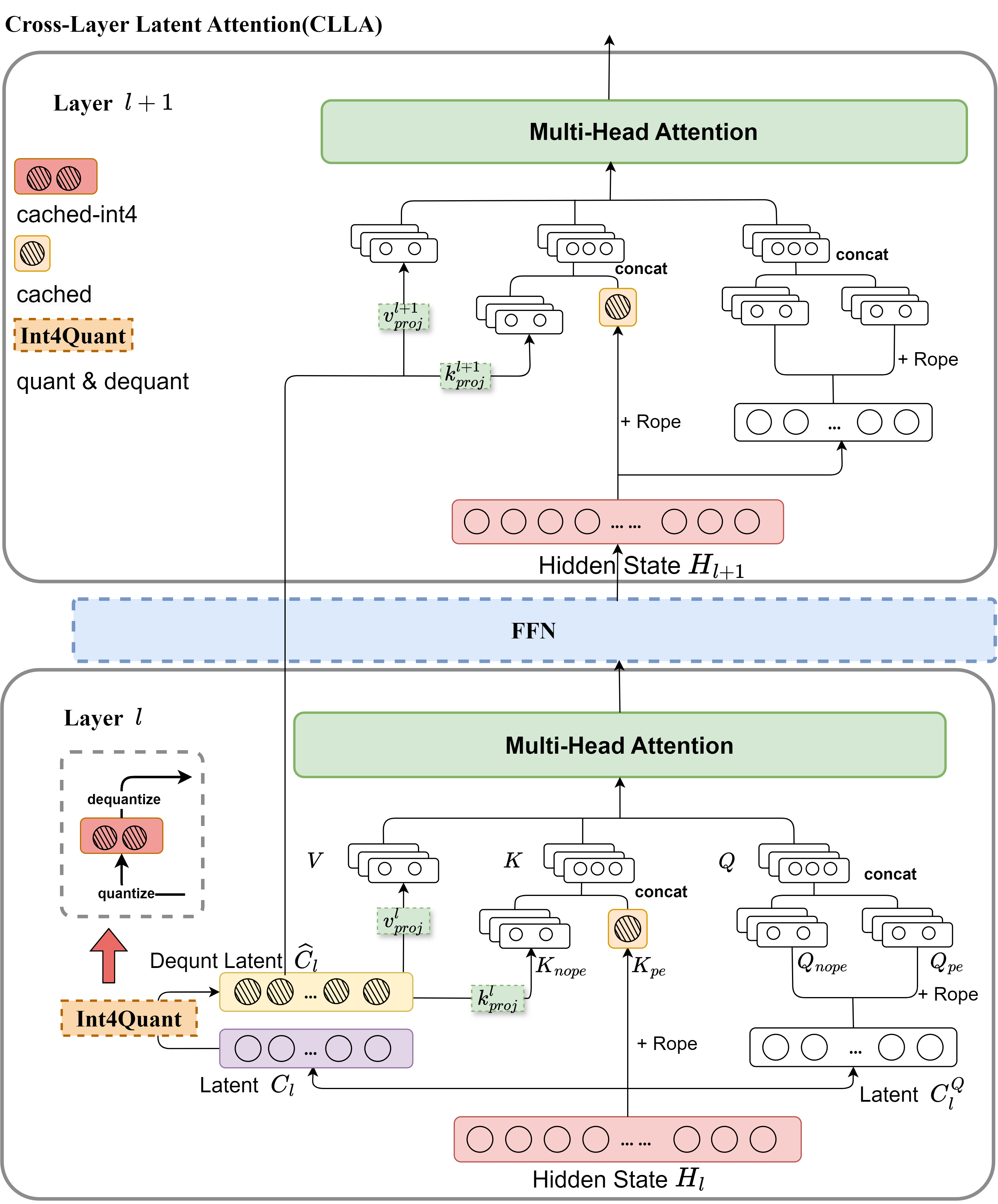
Figure 1: Overview of the Cross-Layer Latent Attention (CLLA) architecture. During training with CLLA, the preceding layer computes the compressed key-value (KV) pairs after quantization and dequantization. The subsequent layer then continues to utilize the compressed KV from the previous layer. During inference, the model stores the compressed KV pairs of the l-th layer with int4 quantization.
Methodology
Preliminary of KV Cache and CLLA Framework
The KV cache in Transformer models—crucial for speeding up autoregressive inference—traditionally requires significant memory. Classical multi-head attention (MHA) models generate KV caches whose memory demand is considerable, which prompted the exploration for compression methods. CLLA offers a structure that compresses these caches through:
Latent Quantization
Quantization further compresses memory use by converting latent states from floating-point representations to low-bit integers without significant performance degradation. The scaling and clipping processes ensure the precision of stored values in limited bit profiles. This aspect of CLLA is pivotal in minimizing resource demands during both training and inference.
Experimental Results
Extensive evaluation across various English and Chinese benchmarks—encompassing datasets like MMLU, ARC-C, and Hellaswag—demonstrates that CLLA achieves lossless performance despite a drastic reduction in KV cache size. The performance metrics for CLLA and CLLA-quant underscore their effectiveness, with CLLA-quant achieving an unprecedented 2% of the original memory footprint in KV caches.
Implications and Future Work
The implications of this research are profound for the deployment of LLMs in resource-constrained environments. By optimizing KV cache storage, models can be run more efficiently on hardware with limited memory, bringing high-capacity AI solutions within reach for a broader range of applications.
Future research could focus on applying CLLA and its quantized variant to even larger LLMs to test scalability. Additionally, further exploration of parameter allocations and adjustments in the attention mechanisms might yield even greater efficiencies or open new avenues for optimization, particularly in multilingual and hypothetically diverse domain applications.
Conclusion
The CLLA framework represents a significant advancement in memory-efficient AI, demonstrating that sophisticated KV cache compression can be achieved without sacrificing model performance. As AI continues to integrate more deeply into real-world applications, techniques like CLLA will be critical in balancing resource constraints with the high expectations for model performance and capacity. By reducing the memory footprint of large models, CLLA facilitates more efficient deployment and democratizes access to cutting-edge AI capabilities.