- The paper demonstrates that diverse multi-agent debates significantly improve LLM reasoning performance, achieving state-of-the-art accuracy.
- It employs iterative debate rounds with varied model architectures, highlighting the methodology's effectiveness across benchmarks.
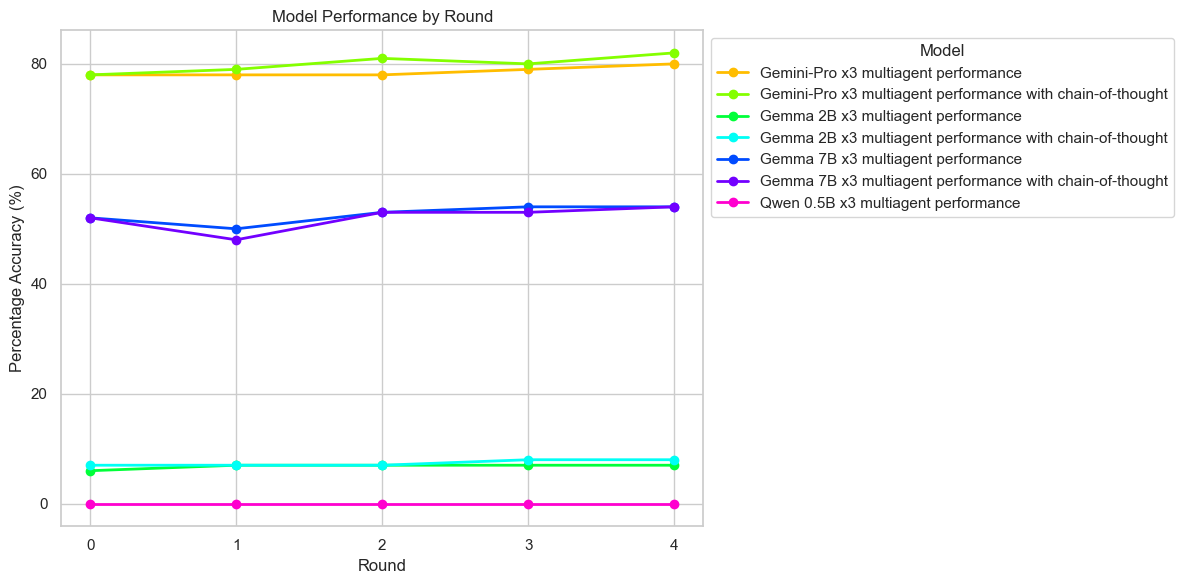
- The study shows that diverse model setups outperform homogeneous ones, with smaller models benefiting from collaborative reasoning.
Diversity of Thought Elicits Stronger Reasoning Capabilities in Multi-Agent Debate Frameworks
Introduction
The paper "Diversity of Thought Elicits Stronger Reasoning Capabilities in Multi-Agent Debate Frameworks" (2410.12853) explores the efficacy of multi-agent debate frameworks in enhancing the reasoning capabilities and factual accuracy of LLMs. In the field of AI, LLMs often exhibit excellent natural language generation abilities but falter when it comes to accurate reasoning tasks, such as mathematical problem solving. Common issues include the generation of plausible but erroneous information, known as hallucinations.
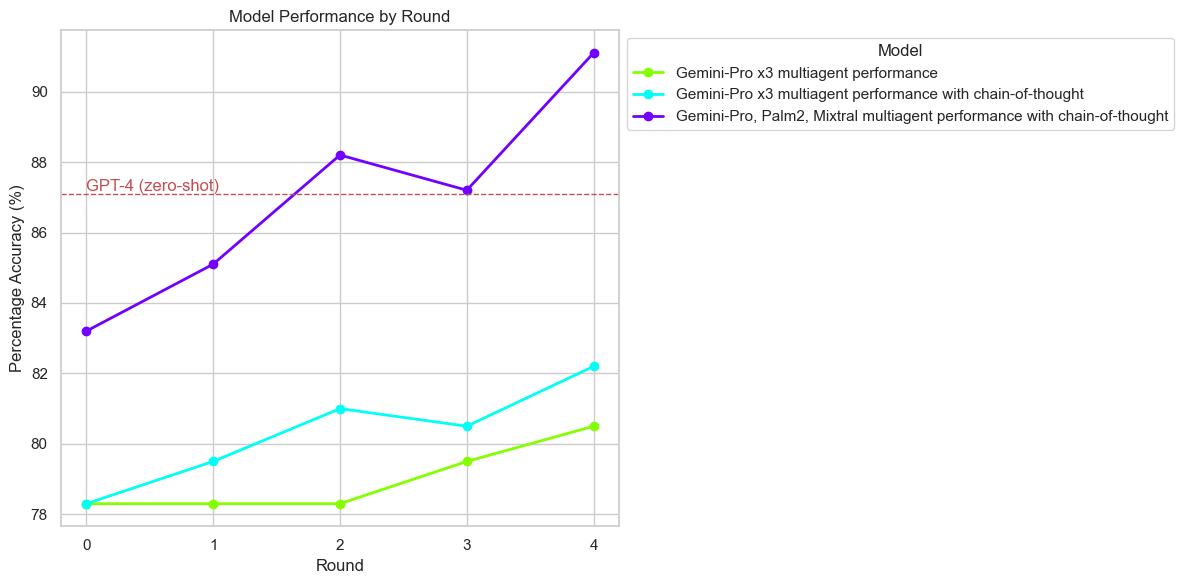
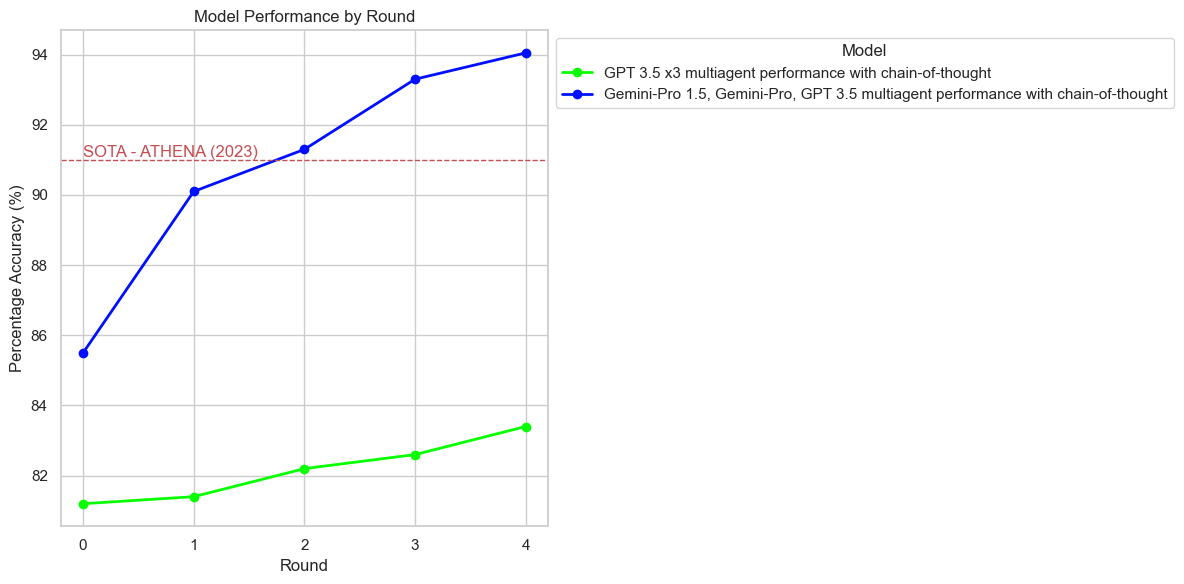
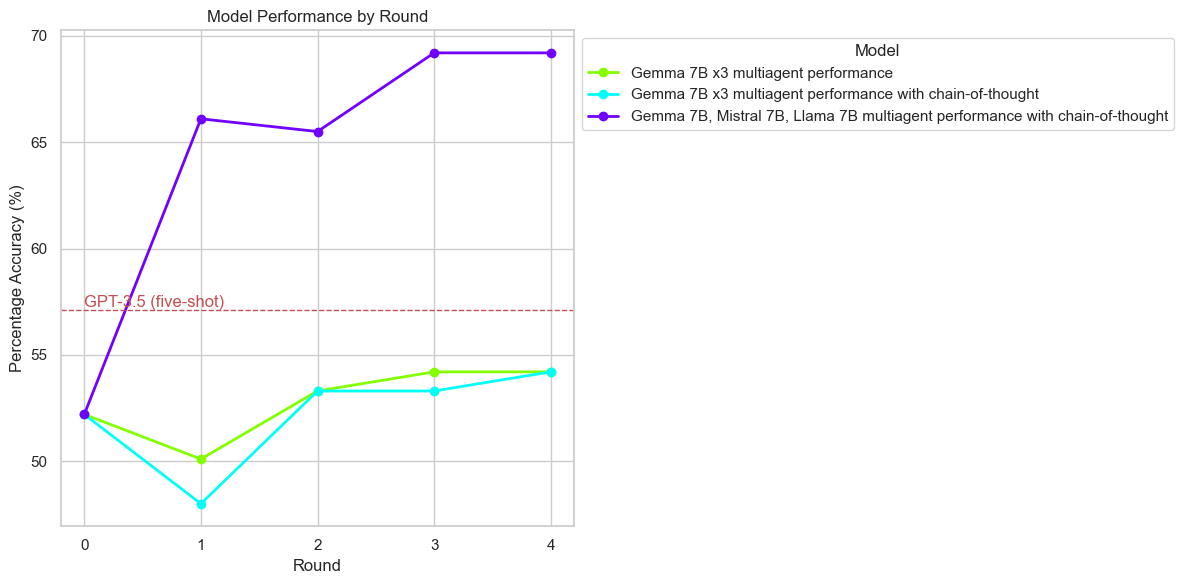
The study builds on existing multi-agent debate frameworks, particularly the one proposed by Du et al., to investigate how diverse model architectures can collaboratively improve the reasoning performance of LLMs across different benchmark datasets. The research findings demonstrate that diverse model sets significantly outperform homogeneous model configurations, even surpassing state-of-the-art models like GPT-4 in certain contexts.
Methodology
The paper details a multi-agent debate framework designed to enhance mathematical reasoning capabilities, which broadly consists of the following components:
- Question Encoding: The problem is encoded as input for the debating models.
- Debating Models: The framework employs three diverse models (Model 1, Model 2, Model 3) with different architectures to promote diverse approaches to reasoning.
- Debate Rounds: Models engage in structured debate rounds, iteratively refining their responses based on insights from previous rounds.
- Response Summarization: A summarization model consolidates the debate outcomes into a coherent summary.
- Iterative Refinement: The summarized response is fed back to the models to further refine their reasoning.
- Final Summary: After several debate rounds, a final summary captures the converged solution, reflecting enhanced reasoning derived from collaborative debate.
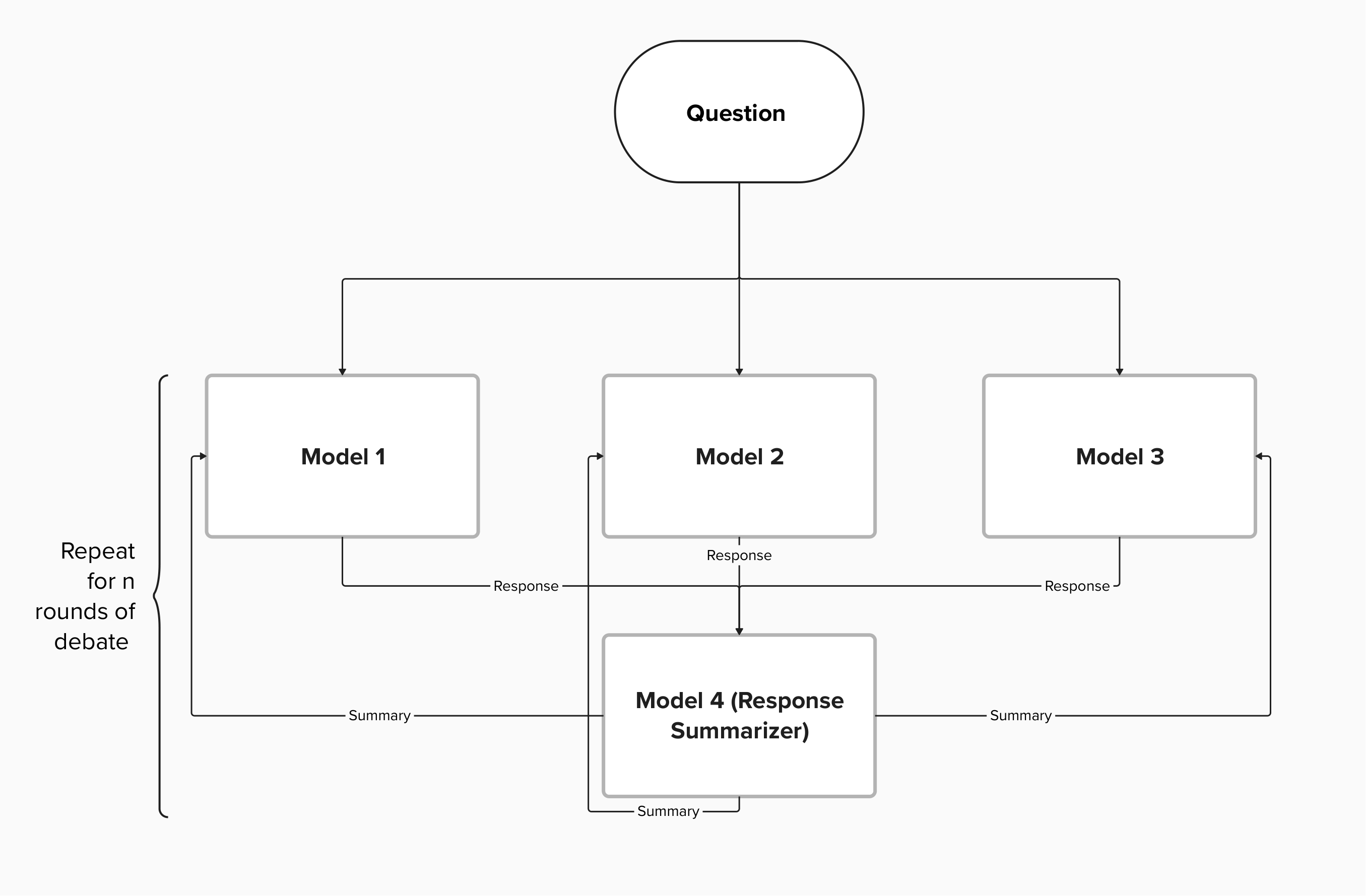
Figure 1: Multi Agent Debate Framework Architecture.
Experimental Results
The experiments were conducted across multiple benchmarks including GSM-8K, ASDiv, and MATH to evaluate the framework's performance. The configurations varied between diverse model setups and homogeneous model setups. Key findings include:
Diversity and Model Scale Effects
The study investigates the impact of model diversity and scale:
Conclusion
This paper underscores the pivotal role of diversity in enhancing the reasoning capabilities of LLMs through a multi-agent debate framework. By employing diverse models in structured debate, it was possible to achieve superior accuracy and robustness in reasoning tasks compared to homogeneous configurations or even highly advanced solitary models. The research indicates that collaborative, agentic AI frameworks can lead to emergent capabilities, underscoring a significant shift towards agentic AI development. As LLMs continue to evolve, fostering diversity could be key to overcoming existing limitations in reasoning accuracy and reliability.