ProAct: Agentic Lookahead in Interactive Environments
Abstract: Existing LLM agents struggle in interactive environments requiring long-horizon planning, primarily due to compounding errors when simulating future states. To address this, we propose ProAct, a framework that enables agents to internalize accurate lookahead reasoning through a two-stage training paradigm. First, we introduce Grounded LookAhead Distillation (GLAD), where the agent undergoes supervised fine-tuning on trajectories derived from environment-based search. By compressing complex search trees into concise, causal reasoning chains, the agent learns the logic of foresight without the computational overhead of inference-time search. Second, to further refine decision accuracy, we propose the Monte-Carlo Critic (MC-Critic), a plug-and-play auxiliary value estimator designed to enhance policy-gradient algorithms like PPO and GRPO. By leveraging lightweight environment rollouts to calibrate value estimates, MC-Critic provides a low-variance signal that facilitates stable policy optimization without relying on expensive model-based value approximation. Experiments on both stochastic (e.g., 2048) and deterministic (e.g., Sokoban) environments demonstrate that ProAct significantly improves planning accuracy. Notably, a 4B parameter model trained with ProAct outperforms all open-source baselines and rivals state-of-the-art closed-source models, while demonstrating robust generalization to unseen environments. The codes and models are available at https://github.com/GreatX3/ProAct

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “ProAct: Agentic Lookahead in Interactive Environments”
Overview
This paper is about teaching AI systems (specifically, LLMs, or LLMs) to plan ahead better when they have to make a series of choices, like in a puzzle game. The authors introduce a two-part method called ProAct that helps the AI “think a few steps into the future” in a way that’s both accurate and efficient, without getting confused by made-up guesses about what might happen.
What questions does the paper try to answer?
- How can we help AI avoid “hallucinating” wrong futures when it plans multiple steps ahead?
- Can we make an AI learn the skill of looking ahead without running a slow, expensive search every time it acts?
- How can we make the AI’s training more stable and reliable when rewards come much later than actions (like finishing a level after many moves)?
How did they do it?
The authors built ProAct with two stages. You can think of them like “learning from a coach” and then “practicing with a fitness tracker.”
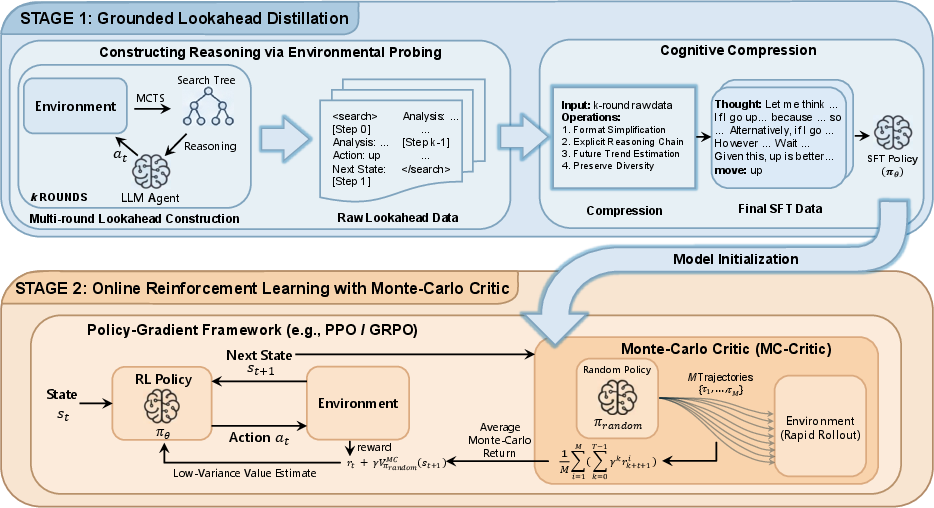
Stage 1: GLAD (Grounded LookAhead Distillation)
Analogy: Imagine you’re learning chess. Instead of guessing what might happen after a move, your coach sets up the board, tries out different future moves for real, and shows you which paths win or lose. Then the coach helps you write a short, clear note about why one move is best.
What happens here:
- The AI explores the game’s future using a search method (like a tree of “what if” paths), called MCTS (Monte Carlo Tree Search). Think of MCTS as trying many possible futures from the current position to see what actually happens.
- It keeps both good paths and bad/dead-end paths, so it learns what to avoid.
- Those long, messy search trees are then “compressed” into short, human-like reasoning notes that explain:
- What the AI sees now,
- What would likely happen after different actions,
- Why the chosen action is best (and why others are risky).
- The AI is trained (with supervised fine-tuning) on these clean notes and actions, so it learns the “feel” of accurate lookahead without needing to search during real play.
Why this helps: Instead of guessing the future and drifting into mistakes, the AI learns from real outcomes and builds an internal sense of how the world actually reacts.
Stage 2: MC-Critic (Monte Carlo Critic) for Reinforcement Learning
Analogy: Now the AI practices on its own, but with a “fitness tracker” that estimates how good its current situation is. Instead of asking a slow, complex model to judge that, it quickly plays out many mini future games at random from the current position to get an average score. This average acts like a steady, low-noise estimate of “how promising things look right now.”
What happens here:
- In reinforcement learning, the AI needs to know how good a state is to improve. That’s called a “value estimate.”
- Training a separate value model for an LLM is slow and noisy. So MC-Critic skips training that extra model and:
- Runs many fast, cheap random simulations into the future from the current state,
- Averages their results to estimate how good the current state is.
- This estimate is plugged into standard training methods (like PPO and GRPO—think of them as rules that nudge the AI to pick better actions more often).
- The result: updates are more stable and focus on long-term success, not just the next move.
Why this helps: It makes the AI’s learning steadier and less “jittery,” even in long tasks where rewards come much later.
What did they find, and why does it matter?
Here’s what the authors tested and discovered, using two games as benchmarks:
- 2048 (stochastic): After each move, a random new tile appears. Good for testing planning under uncertainty.
- Sokoban (deterministic): A puzzle where you push boxes onto targets. Good for testing careful planning with fewer moves and sparse rewards.
Key results:
- A relatively small 4-billion-parameter model trained with ProAct beat all open-source baselines and was competitive with top closed-source systems.
- It worked well across different versions of the games (like changing the 2048 board size, the starting tile values, or the Sokoban action rules and symbols), showing strong generalization.
- GLAD alone made the AI’s reasoning more accurate and concise, avoiding “delusional” plans.
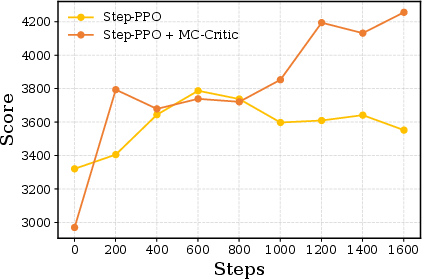
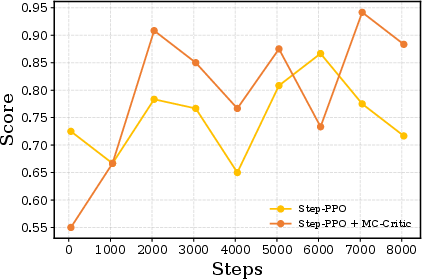
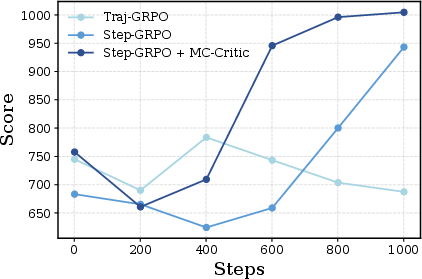
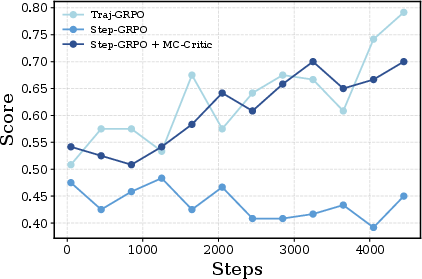
- Adding MC-Critic on top of GLAD improved scores further and made training more stable for long tasks.
Why it matters:
- The AI learns to think ahead like a careful planner but can act quickly, because it doesn’t need to run a heavy search at decision time.
- The AI’s “thought process” is more grounded in reality, reducing errors caused by guessing how the world works.
- Training is more reliable and less likely to collapse because the value estimates are steady and affordable.
What’s the bigger impact?
ProAct shows a practical recipe for building AI agents that:
- Plan multiple steps into the future without getting lost,
- Learn from real outcomes rather than imagination alone,
- Train efficiently and robustly in interactive worlds.
This has potential beyond games—think smarter digital assistants that plan tasks, robots that perform multi-step actions safely, or tutoring systems that scaffold long problem-solving. The general idea—distill accurate lookahead from real environment feedback, then refine with stable learning—can be adapted to many interactive settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research:
- Scope limitation: Results are reported only on 2048 and Sokoban. It is unclear how ProAct performs in partially observable environments, continuous action spaces, multi-agent settings, or real-world tasks (e.g., web navigation, robotics, tool use).
- MCTS specification and sensitivity: The paper does not detail MCTS parameters (rollout depth, branching policy, selection/exploration constants, terminal criteria). No sensitivity analysis shows how GLAD performance depends on these choices, especially in stochastic environments like 2048.
- Handling stochasticity in GLAD: For 2048, it is unclear how randomness (tile spawn distribution) is modeled in search and subsequently reflected in compressed reasoning. Open question: how to distill lookahead that explicitly accounts for uncertainty (e.g., expected-value vs risk-aware plans).
- Compression pipeline opacity: The “Compress” step (teacher model, prompts, filtering) is insufficiently specified. There are no ablations comparing raw search traces vs compressed chains or quantifying how compression length, style, and structure affect downstream performance.
- Exposure bias and distribution shift: GLAD trains on contexts augmented with environment-probed trajectories that are absent at inference. Open question: does this induce reliance on “oracle-like” information, and how robust is the distilled reasoning when such detailed future evidence is unavailable?
- Special token usage (<BACKTRACK>): The role, frequency, and effectiveness of <BACKTRACK> are not quantified, nor is its use at inference time clarified. Ablations on its contribution to performance and error recovery are missing.
- Data scale and scaling laws: GLAD uses relatively small datasets (25K for 2048, 8K for Sokoban). There is no study of scaling laws (dataset size vs performance), diminishing returns, or data efficiency relative to search compute.
- Compute and cost reporting: The paper does not provide detailed compute budgets (GPU-hours, tokens generated, environment-steps) for GLAD and RL phases, nor a comparison of cost vs gains against inference-time search methods (e.g., ToT/RAP).
- Random-policy MC-Critic bias: MC-Critic estimates values under a random policy, not the current policy. Theoretical justification for using off-policy, suboptimal value baselines in advantage computation is lacking; bias and failure modes when the random rollout distribution diverges from the learned policy are unquantified.
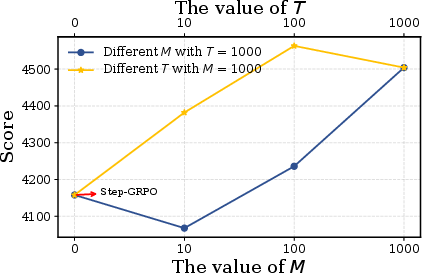
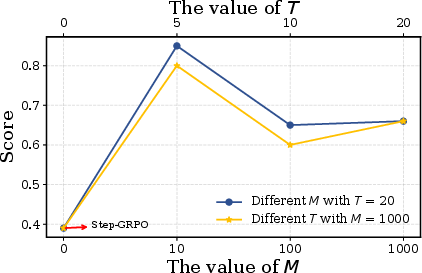
- Variance reduction claims: MC-Critic’s “low-variance” claim is not supported by formal variance bounds or empirical measurements (e.g., variance of returns, gradient variance). Open question: how do M, T, and environment properties affect variance and stability.
- Hyperparameter sensitivity: The method provides limited analysis on the choice of M (number of rollouts), T (horizon), γ (discount), and their trade-offs (bias/variance, runtime, sample efficiency). A systematic sensitivity study is missing.
- ω weighting in MC-PPO: The choice and scheduling of ω (mixing MC-Critic with parametric critic) are not justified or analyzed. Open question: how to adapt ω across training phases and environments to optimize stability and performance.
- Turn-level vs token-level credit assignment: Both Step-PPO and GRPO variants assign a shared advantage across tokens within a turn. It remains unknown whether more granular token-level critics or structure-aware credit assignment could improve learning signals.
- History-free decision simplification: Step-PPO discards interaction history, relying only on current state. This may harm tasks requiring memory or temporal coherence. Open question: how to incorporate compact summaries or selective memory without exceeding token limits.
- Reward shaping and objective alignment: 2048 uses merge-value rewards, and Sokoban uses box placement counts. There’s no analysis of how these shaping choices align with long-horizon success (e.g., 2048 highest tile, Sokoban level completion) or whether they incentivize myopic strategies.
- Generalization after RL: RL on Sokoban was conducted on the same level set used for evaluation (Base), with limited reporting on transfer to unseen levels (Extra) after RL. It remains unclear whether RL fine-tuning reduces or improves out-of-distribution generalization relative to GLAD-only.
- Benchmarking against inference-time planners: The paper does not include a direct cost-performance comparison to inference-time search (e.g., ToT/MCTS at inference) under equal compute budgets, leaving open whether ProAct’s distilled lookahead matches or surpasses explicit planning in various regimes.
- Teacher model dependence: If a stronger teacher is used in compression, its specification (architecture, size, settings) and impact on outcomes are unclear. Open question: how does teacher quality affect the fidelity and utility of compressed chains, and can self-compression match teacher-guided compression?
- Environment serialization and prompt sensitivity: Although symbol variants are tested, broader analyses of prompt format robustness, serialization changes, and temperature settings are missing. Open question: how brittle is performance to prompt/template variations and model sampling parameters.
- Action space scaling: Experiments focus on small discrete action spaces. It remains unknown how MC-Critic and GLAD scale to large discrete or continuous actions, or whether heuristic rollouts outperform random rollouts for value estimation in complex action spaces.
- Alternative rollout policies: The use of a random policy for MC-Critic may be insufficient in complex environments. Open question: can lightweight heuristic or learned rollout policies offer better bias-variance trade-offs without incurring heavy compute costs?
- Theoretical guarantees: There is no theoretical analysis relating the off-policy MC-Critic to policy-gradient convergence, bias in advantage estimation, or bounds on performance degradation/improvement.
- Failure modes and safety: The paper does not characterize scenarios where MC-Critic misguides learning (e.g., deceptive states, sparse terminal rewards), nor does it assess whether GLAD reduces hallucinations quantitatively (simulation accuracy metrics).
- Model size effects: Results are centered on a 4B model. Open question: how do benefits scale with model size (smaller and larger LLMs), and is ProAct’s advantage consistent across parameter regimes?
- Beyond games: The framework’s applicability to non-game, real-world interactive tasks (tools, APIs, embodied control) is untested, raising questions about adaptation requirements (state representation, reward design, safety constraints).
Glossary
- action-value function (Q-function): Expected cumulative return from taking an action in a state and following a policy thereafter; used to evaluate actions. "the action-value function denotes the expected cumulative reward"
- advantage: A baseline-adjusted measure of how much better an action (or turn) performed than expected, used to reduce variance in policy gradients. "compute the advantages for the single-step samples"
- Agentic RL: Reinforcement learning for multi-turn, interactive LLM agents that optimizes entire trajectories rather than single turns. "Multi-Turn Agentic RL"
- AReaL framework: A training/evaluation framework used to implement the paper’s SFT and RL experiments for LLM agents. "All SFT and RL experiments are implemented within the AReaL framework"
- asymmetric critic: A critic that has access to privileged information at training time to provide stronger feedback signals. "SWEET-RL ~\citep{sweet} introduces an asymmetric critic"
- Chain-of-Thought (CoT): A prompting/decoding strategy that elicits step-by-step reasoning before final answers or actions. "Chain-of-Thought ~\citep{cot,tot}"
- credit assignment: The challenge of attributing sparse, delayed rewards to specific reasoning steps or actions across long horizons. "improve credit assignment over long horizons"
- curriculum strategy: A staged training schedule that gradually increases task difficulty or horizon to stabilize learning. "a curriculum strategy that progressively expands interaction horizons"
- dynamic sampling: A procedure that selectively discards or resamples degenerate groups (e.g., identical actions) during training. "dynamic sampling ~\citep{dapo}"
- Echo Trap: A failure mode where agents overfit to shallow reasoning patterns, harming multi-turn performance. "the ``Echo Trap" phenomenon"
- Generalized Advantage Estimation (GAE): A variance-reduction technique that computes smoothed advantages using temporal-difference residuals. "We then calculate the advantage for each turn using GAE:"
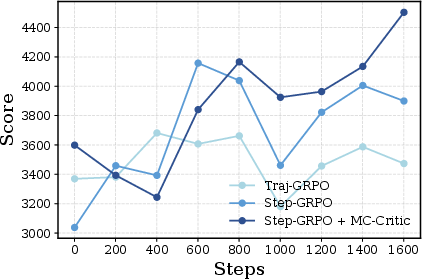
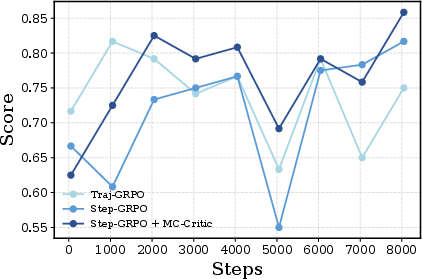
- GRPO: A policy-gradient algorithm that normalizes rewards within groups to compute relative advantages. "policy-gradient algorithms like PPO and GRPO"
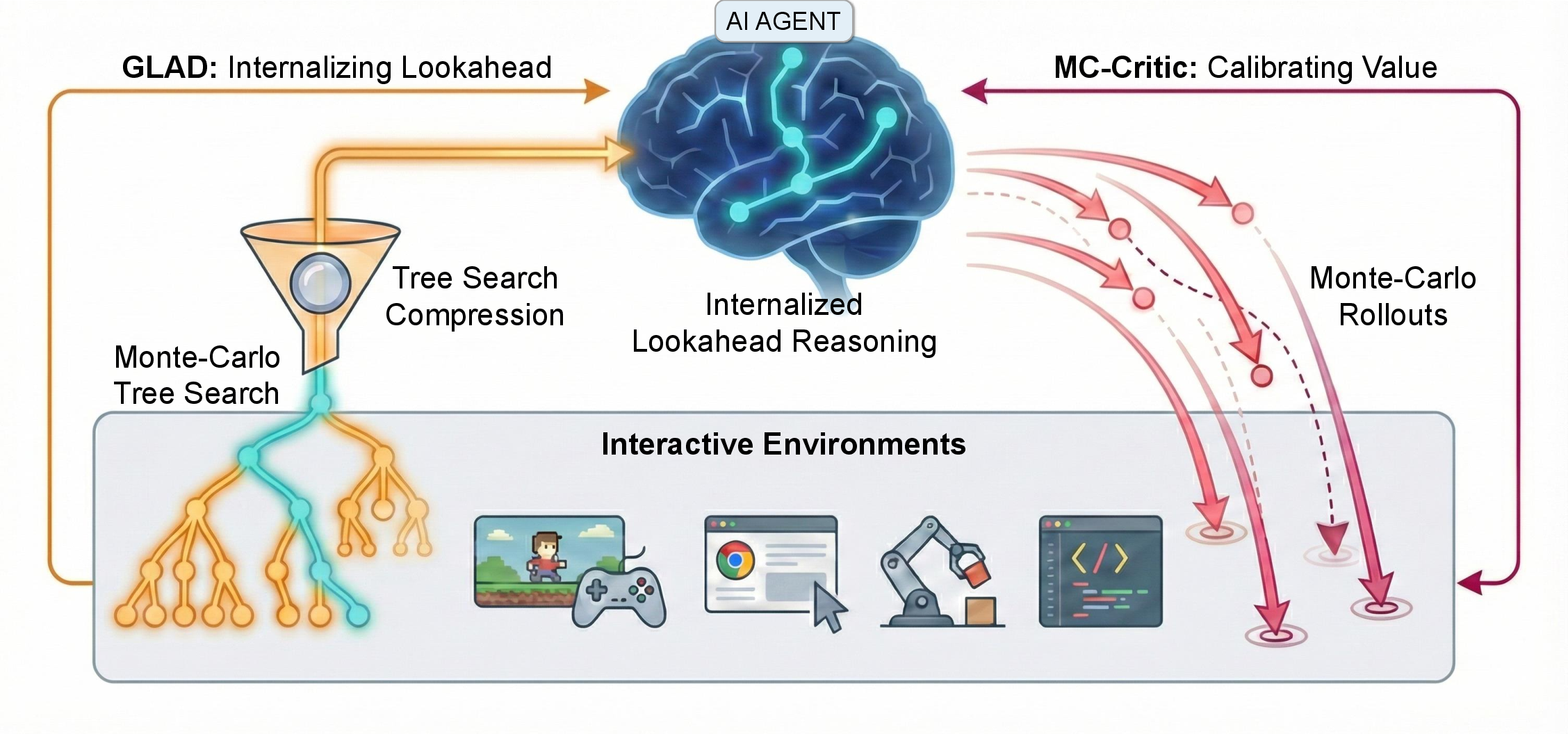
- Grounded LookAhead Distillation (GLAD): A supervised distillation method that compresses environment-grounded search into concise reasoning chains. "Grounded LookAhead Distillation (GLAD)"
- group normalization: Normalizing statistics across a group of samples (e.g., trajectories) to compute relative, comparable advantages. "group normalization is applied to these trajectory-level rewards"
- Markov Decision Process (MDP): A formal model of sequential decision making defined by state, action, transition, reward, and discount. "formalized as a Markov Decision Process (MDP) tuple"
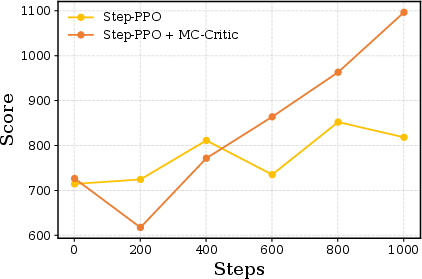
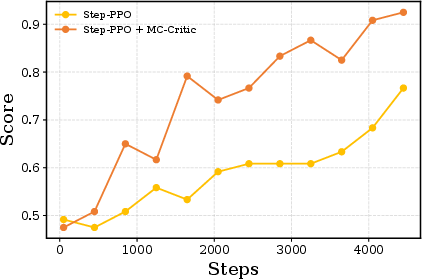
- MC-Critic (Monte-Carlo Critic): A parameter-free critic that estimates values by averaging discounted returns from Monte Carlo rollouts. "Monte-Carlo Critic (MC-Critic)"
- MC-GRPO: A GRPO variant that replaces immediate rewards with MC-Critic–estimated action values to compute advantages. "we introduce MC-GRPO"
- MC-PPO: A PPO variant that blends the learned critic’s value with MC-Critic’s estimate to reduce variance. "we propose MC-PPO"
- MCTS (Monte-Carlo Tree Search): A lookahead search algorithm that uses sampled rollouts to guide exploration of a decision tree. "Monte-Carlo Tree Search (MCTS)"
- Monte Carlo rollouts: Sampling trajectories from a policy or random policy to estimate returns or values empirically. "via Monte Carlo rollouts."
- out-of-distribution (OOD): Evaluation or inputs that differ from the training distribution, testing generalization. "out-of-distribution scenarios"
- policy-gradient: A family of algorithms that directly optimize a parameterized policy by ascending estimated return gradients. "policy-gradient algorithms like PPO and GRPO"
- PPO (Proximal Policy Optimization): A widely used clipped policy-gradient method that stabilizes updates via ratio clipping. "PPO"
- Reasoning Compression: Converting verbose search traces and world-modeling into concise, causal reasoning chains. "introducing Reasoning Compression."
- ReAct: An approach that interleaves reasoning and acting steps to structure multi-turn decision making. "ReAct ~\citep{react}"
- simulation drift: The compounding divergence between an agent’s internally simulated futures and the environment’s true dynamics. "a phenomenon we term simulation drift"
- state-value function (V-function): Expected cumulative return from a state when following a policy. "the state-value function represents the expected cumulative reward"
- Step-GRPO: A step-level extension of GRPO for multi-turn settings that forms groups at the single-step level. "termed Step-GRPO."
- Step-PPO: A PPO variant for multi-turn interactions that computes turn-level advantages and updates by step. "we propose Step-PPO"
- System 1: Fast, intuitive, low-cost reasoning or policy intuition distilled from explicit planning. "System 1"
- System 2: Slow, deliberative reasoning processes that involve explicit planning or search. "System 2 processing"
- Trajectory-Level GRPO (Traj-GRPO): A GRPO variant that normalizes rewards across whole trajectories rather than steps. "Trajectory-Level GRPO ~\citep{ragen} (hereinafter referred to as Traj-GRPO)."
- Turn-PPO: A multi-turn adaptation of PPO that computes advantages at the turn level. "Turn-PPO ~\citep{turn-ppo}"
- Tree of Thoughts (ToT): A method that integrates explicit tree search over reasoning paths during inference. "Tree of Thoughts ~\citep{tot}"
- VAGEN: A method that enforces generation of internal world models to ground agent reasoning. "VAGEN ~\citep{vagen}"
- world models: Internal representations of environment state and dynamics used for prediction and planning. "internal ``world models" (e.g., state estimation and dynamics simulation)"
Practical Applications
Below is an overview of practical applications enabled by the paper’s core contributions—GLAD (Grounded LookAhead Distillation) and MC-Critic (Monte Carlo Critic)—organized by deployment horizon. Each item highlights sectors, specific use cases, potential tools/products/workflows, and key dependencies/assumptions that affect feasibility.
Immediate Applications
The following can be piloted today with existing simulators, enterprise testbeds, or constrained domains where state transitions can be executed or simulated cheaply.
- Cost-efficient replacement for search-at-inference agents
- Sectors: software/AI infrastructure, gaming, education
- What: Distill heavy inference-time search (e.g., Tree-of-Thoughts, MCTS) into compact policies that retain lookahead via GLAD, cutting serving costs and latency.
- Tools/Products/Workflows: “Lookahead-distilled” model variants; training pipelines that run MCTS once offline, compress search traces to concise causal rationales, and deploy a 4B-class model.
- Assumptions/Dependencies: Access to an executable/simulatable environment; ability to generate search trees offline; stable reward signals for SFT/RL alignment.
- Reliable and auditable web RPA agents (form filling, workflow navigation)
- Sectors: software, enterprise automation (RPA), customer ops
- What: Use headless browsers to probe future UI states (DOM-level MCTS or scripted rollouts) and GLAD to learn compact, correct action rationales; augment RL fine-tuning with MC-Critic using fast random UI rollouts for value estimates.
- Tools/Products/Workflows: ProAct-Web library; DOM state serializer; action schema; “<BACKTRACK>” control to safely revert; CI-like sandboxes.
- Assumptions/Dependencies: Reasonably deterministic UI under test; programmatic stepping; reward design for partial progress (reachability, form validity).
- Deeper UI test generation and app exploration
- Sectors: software QA, mobile and web testing
- What: Train agents to reach deep app states reliably by grounding lookahead in real UI transitions; MC-Critic uses cheap random UI rollouts for low-variance value estimates to stabilize RL.
- Tools/Products/Workflows: Device farms/emulators; test oracles; coverage-driven reward shaping; compressed reasoning chains for explainable test steps.
- Assumptions/Dependencies: State serialization and replay; inexpensive rollouts; availability of partial progress rewards.
- Game AI “coach mode” with explainable foresight
- Sectors: gaming, e-sports coaching, education
- What: Distill MCTS foresight into human-readable, concise rationales that explain both chosen actions and rejected alternatives; ship as coaching overlays or tutorial modes.
- Tools/Products/Workflows: GLAD-trained commentators; post-hoc rationale generation aligned to in-game state.
- Assumptions/Dependencies: Fully known game dynamics; ability to probe trajectories offline; clear success metrics.
- Spreadsheet/database editing assistants with safe planning
- Sectors: office productivity, data ops, BI
- What: Learn lookahead to avoid destructive edit sequences and plan multi-step transformations; use GLAD on a sandboxed workbook/database and MC-Critic to evaluate downstream effects via quick rollouts.
- Tools/Products/Workflows: Excel/Sheets/SQL sandbox; transactional rollbacks; “diff” rewards; compressed rationales logged for audit.
- Assumptions/Dependencies: Sandbox to step and revert; action schema; partial credit (e.g., data validation checks).
- Agentic IDE assistants for small-to-medium codebases
- Sectors: software engineering
- What: Plan multi-edit refactors or bug fixes by simulating compile/test outcomes; GLAD distills search or proof-like traces (property checks, tests) into actionable rationales; MC-Critic uses fast test-suite rollouts as value estimates.
- Tools/Products/Workflows: Repo sandbox; unit tests as rewards; state pooling per file/module; “<BACKTRACK>” for revertible edits.
- Assumptions/Dependencies: Fast, reliable tests; structured action space (patches, refactors); observability of pass/fail signals.
- Robotics-in-simulation distillation for simple tasks
- Sectors: robotics, warehousing, edtech robotics
- What: Train in simulation (grid navigation, pushing akin to Sokoban) with GLAD + RL and deploy the compact policy on-device; get explainable stepwise rationales for audit and debugging.
- Tools/Products/Workflows: Sim (e.g., Isaac Gym, Webots); domain randomization; value estimates from MC-Critic via cheap surrogate rollouts in sim.
- Assumptions/Dependencies: High-fidelity sim-to-real mapping for specific tasks; bounded action/state spaces; safety constraints.
- Academic baselines and dataset creation for interactive reasoning
- Sectors: academia, open-source community
- What: Standardize grounded reasoning datasets for long-horizon tasks; evaluate MC-GRPO/MC-PPO as drop-in variants for stability and credit assignment.
- Tools/Products/Workflows: Public GLAD corpora from diverse MDPs; training recipes; ablation tooling.
- Assumptions/Dependencies: Environment wrappers; licensing for datasets; reproducible rollout settings.
- Training cost control for agentic RL
- Sectors: AI infra, MLOps
- What: Replace or augment expensive parametric critics with MC-Critic to reduce variance and speed convergence in long-horizon RL; useful where critic instability causes collapse.
- Tools/Products/Workflows: Plug-in MC-Critic for PPO/GRPO (MC-PPO, MC-GRPO); trajectory/state pool management; lightweight rollout backends.
- Assumptions/Dependencies: Ability to generate many cheap surrogate rollouts (random or heuristic policies) that correlate with future returns.
Long-Term Applications
These require higher-fidelity simulators, stronger safety/regulatory guarantees, scaling to partial observability and large action spaces, or more robust credit assignment in complex, non-stationary domains.
- Clinical decision support with counterfactual treatment planning
- Sectors: healthcare
- What: Use GLAD to distill lookahead over validated clinical simulators or causal models; MC-Critic to stabilize RL training from scarce, noisy outcomes.
- Tools/Products/Workflows: EHR-driven simulators; causal validation; human-in-the-loop oversight; safety guardrails and uncertainty estimates.
- Assumptions/Dependencies: High-fidelity simulators; stringent validation and auditability; bias and safety controls; regulatory approval.
- Portfolio and strategy optimization in non-stationary markets
- Sectors: finance
- What: Long-horizon rebalancing/hedging plans with grounded foresight (e.g., simulator/backtests); cautious use of MC-Critic with non-random baselines (random rollouts are often uninformative).
- Tools/Products/Workflows: Market simulators and backtest harnesses; risk-aware reward shaping; regime-shift detection.
- Assumptions/Dependencies: Partial observability, non-stationarity; robust evaluation; compliance; risk limits.
- Urban mobility, logistics, and supply-chain planning
- Sectors: logistics, transportation, retail
- What: Multi-step route, allocation, and inventory decisions over traffic/demand simulators; GLAD compresses search trees into deployable policies and rationales for planners.
- Tools/Products/Workflows: City-scale simulators; rolling-horizon optimization; planner-in-the-loop UI with rationale display.
- Assumptions/Dependencies: Large state/action spaces; stochastic dynamics; compute for large-scale probing; data availability.
- Energy systems control (grid, HVAC, microgrids)
- Sectors: energy, buildings
- What: Lookahead control policies trained in digital twins (e.g., EnergyPlus); deploy compact controllers that respect safety and comfort constraints with explainable rationales.
- Tools/Products/Workflows: Digital twins; constraint-aware reward design; MC-Critic with surrogate policies to speed training.
- Assumptions/Dependencies: Accurate simulators; strict safety constraints; robust OOD generalization.
- Autonomous driving and advanced driver assistance
- Sectors: automotive, robotics
- What: Internalize search-based planning (e.g., MCTS over trajectories) into compact policies that can explain choices and backtrack; limit to structured subproblems initially (parking, low-speed navigation).
- Tools/Products/Workflows: High-fidelity driving sims; scenario libraries; safety envelopes; formal verification overlays.
- Assumptions/Dependencies: Real-time constraints; multi-agent interactions; liability and certification.
- Multi-agent enterprise workflow orchestration
- Sectors: enterprise software, IT ops
- What: Agents coordinate API calls, approvals, and rollbacks with grounded lookahead, minimizing dead-ends and rework; MC-Critic uses cheap policy surrogates for value baselines in sandboxed org environments.
- Tools/Products/Workflows: Org-level sandboxes; transactional semantics; audit trails with compressed rationales.
- Assumptions/Dependencies: Partial observability of legacy systems; security policies; well-defined reward/SLAs.
- Scientific discovery and automated theorem proving at scale
- Sectors: research, education
- What: Distill search/proof trees from solvers (e.g., Lean/Coq, CAS) into concise rationales that generalize across problems; MC-Critic aids long proof chains’ credit assignment.
- Tools/Products/Workflows: Formal systems integration; counterexample-guided rollouts; curriculum that mixes proofs and partial progress rewards.
- Assumptions/Dependencies: High-quality oracles; stable interfaces to provers/simulators; scaling to very long horizons.
- Personalized education planners and tutors
- Sectors: education
- What: Plan multi-step learning paths with grounded lookahead using simulators of knowledge states or validated mastery models; explain why a path was chosen vs. alternatives.
- Tools/Products/Workflows: Mastery-based simulators; skill graphs; compressed rationales for student-facing explanations.
- Assumptions/Dependencies: Reliable student models; privacy; fair and bias-aware reward designs.
- Safety and compliance copilots with actionable lookahead
- Sectors: legal/compliance, policy
- What: Agents that simulate downstream effects of decisions (e.g., policy changes, process tweaks) within regulatory sandboxes; generate concise causal rationales for audits.
- Tools/Products/Workflows: Policy simulators; evidence tracking; human review gates.
- Assumptions/Dependencies: Availability and fidelity of regulatory sandboxes; explainability requirements; governance processes.
Notes on cross-cutting feasibility
- GLAD depends on access to a faithful, step-executable environment, the ability to sample/search trajectories (often via MCTS), and a compression pipeline that preserves causal logic and counterfactuals while reducing verbosity.
- MC-Critic assumes inexpensive rollouts (often via random or heuristic policies) that correlate with downstream returns; where random rollouts are uninformative (large/continuous action spaces, heavy partial observability, strong non-stationarity), a better surrogate than “random” may be needed.
- Reward design and credit assignment are pivotal; partial-progress rewards (like Sokoban’s box-on-target) improved learning stability and transfer in the paper and are often necessary in real deployments.
- Context limits and history handling: the paper’s Step-* methods rely on current state only; tasks that require long histories may need explicit state summarization or external memory.
- Safety, auditability, and governance are strengthened by GLAD’s concise causal chains and the explicit “backtrack” mechanism, but high-stakes domains still require human oversight, uncertainty estimation, and domain verification.
Collections
Sign up for free to add this paper to one or more collections.

