TabEBM: A Tabular Data Augmentation Method with Distinct Class-Specific Energy-Based Models
Abstract: Data collection is often difficult in critical fields such as medicine, physics, and chemistry. As a result, classification methods usually perform poorly with these small datasets, leading to weak predictive performance. Increasing the training set with additional synthetic data, similar to data augmentation in images, is commonly believed to improve downstream classification performance. However, current tabular generative methods that learn either the joint distribution $ p(\mathbf{x}, y) $ or the class-conditional distribution $ p(\mathbf{x} \mid y) $ often overfit on small datasets, resulting in poor-quality synthetic data, usually worsening classification performance compared to using real data alone. To solve these challenges, we introduce TabEBM, a novel class-conditional generative method using Energy-Based Models (EBMs). Unlike existing methods that use a shared model to approximate all class-conditional densities, our key innovation is to create distinct EBM generative models for each class, each modelling its class-specific data distribution individually. This approach creates robust energy landscapes, even in ambiguous class distributions. Our experiments show that TabEBM generates synthetic data with higher quality and better statistical fidelity than existing methods. When used for data augmentation, our synthetic data consistently improves the classification performance across diverse datasets of various sizes, especially small ones. Code is available at https://github.com/andreimargeloiu/TabEBM.

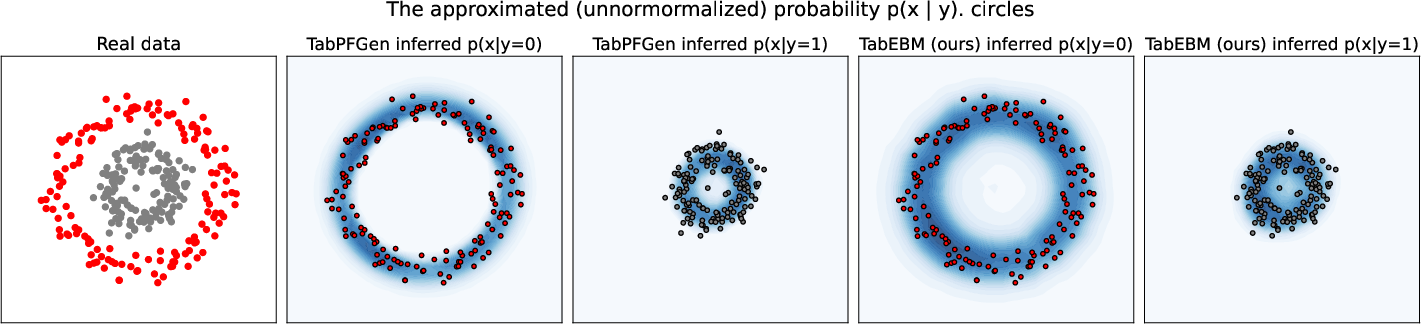
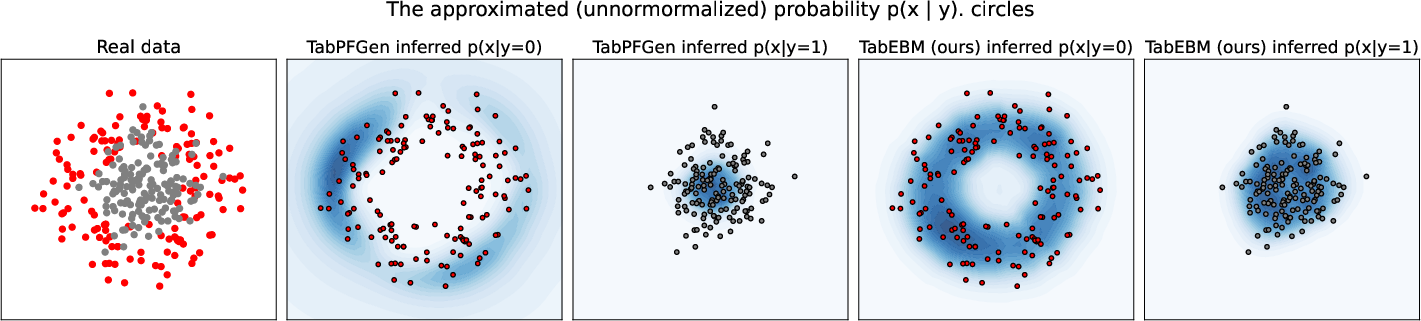
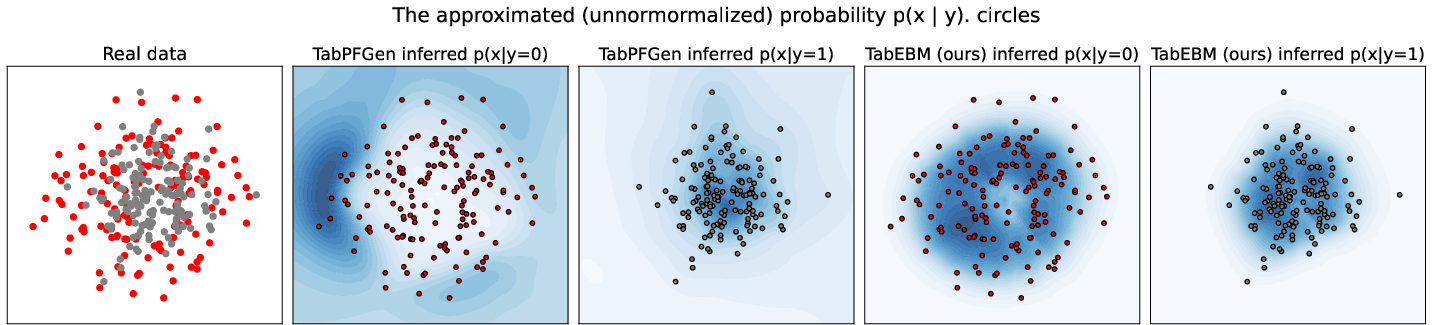
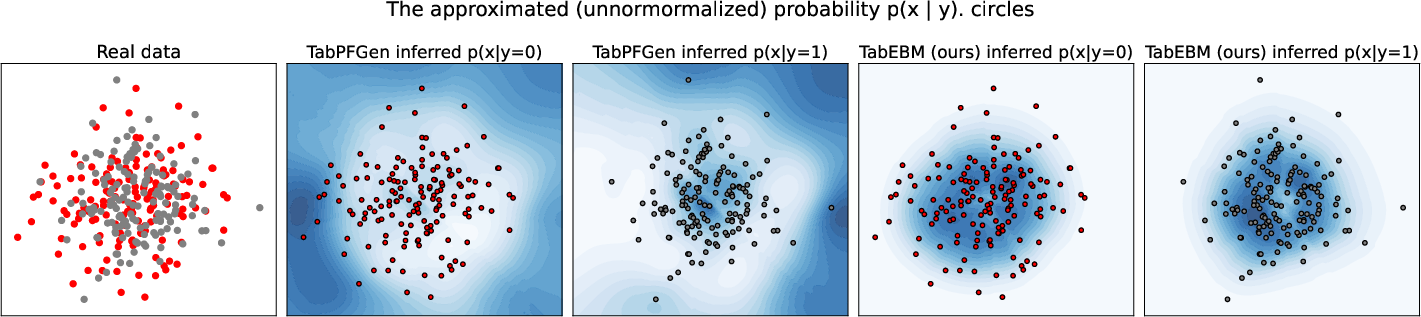
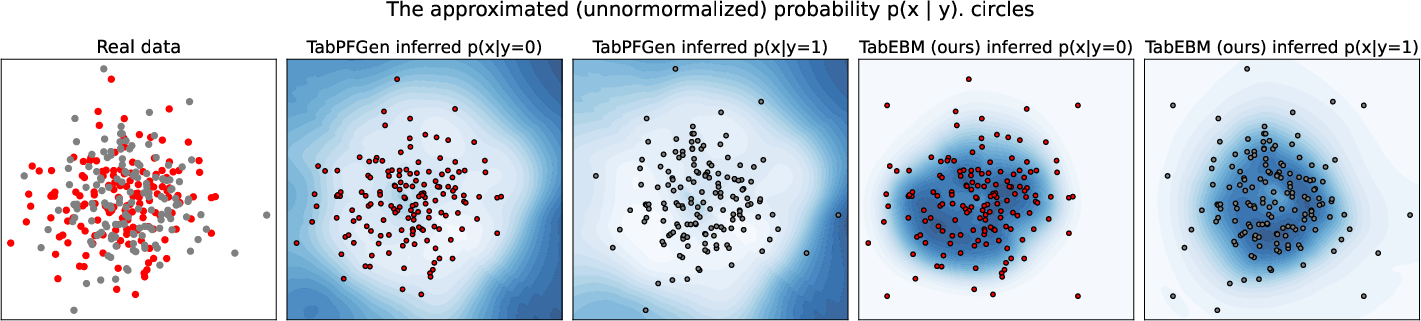

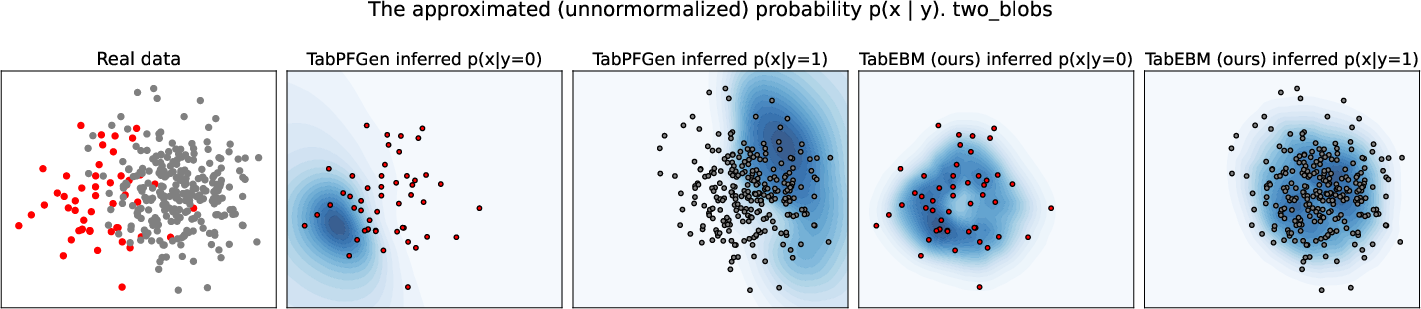
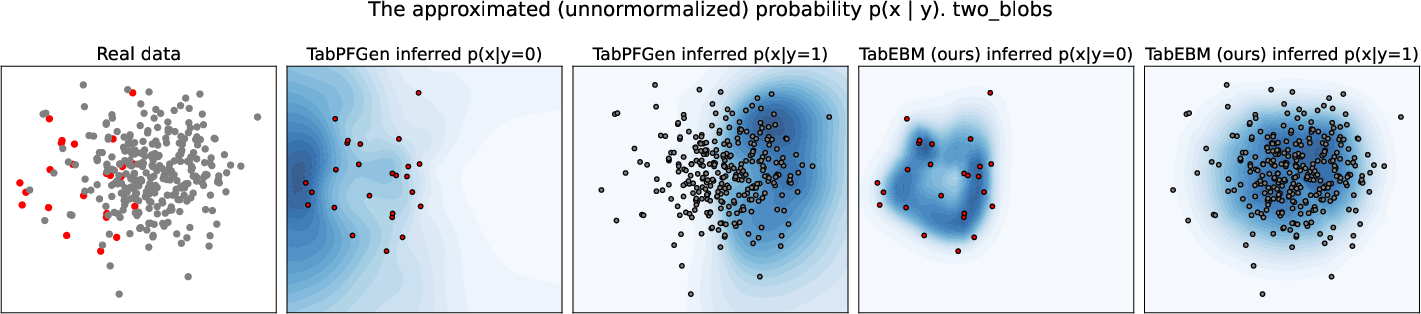
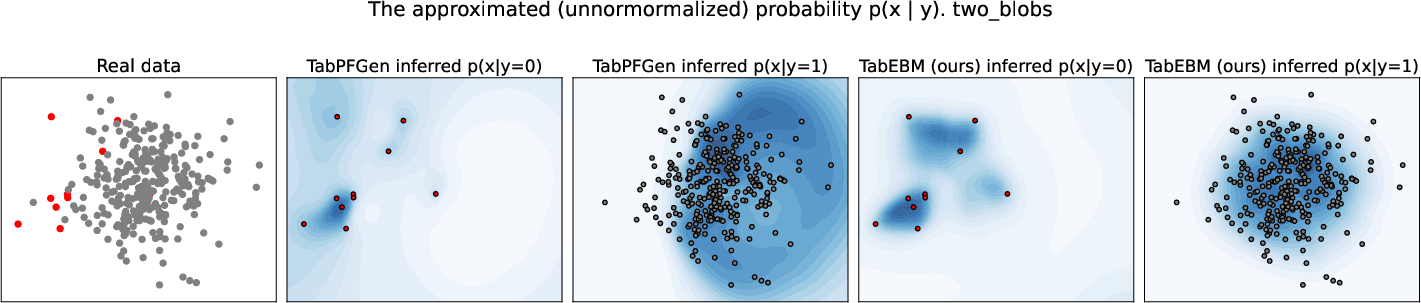

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “TabEBM: A Tabular Data Augmentation Method with Distinct Class-Specific Energy-Based Models”
1. Big idea in a sentence (overview)
This paper shows a new way to make extra, fake-but-realistic rows of data for spreadsheets (called “tabular data”) so that machine learning models can learn better, especially when we don’t have much real data.
2. What problem are they trying to solve?
- In areas like medicine or chemistry, collecting data is hard, so datasets are small.
- Machine learning models usually need lots of examples to do well.
- A common fix is “data augmentation”: creating extra synthetic (fake) data that looks like the real thing.
- But many existing tabular data generators either:
- Overfit (they memorize the tiny dataset and don’t generalize), or
- Mess up the balance of class labels (they make too many of one label and too few of another), or
- Fail to capture the unique patterns of each class when there are multiple classes.
The question: Can we generate higher-quality synthetic tabular data that:
- Matches each class’s unique patterns,
- Keeps the original label balance,
- And improves accuracy on real tasks?
3. How did they do it? (methods in plain language)
Think of a spreadsheet where each row is a data point and the last column is the label (the class). The authors build a separate generator for each class, instead of one big model for all classes. They use a tool called an Energy-Based Model (EBM).
- Energy-Based Model (EBM) explained:
- Imagine a landscape of hills and valleys. A data point sits somewhere on this landscape.
- Low energy = valleys = “more likely” data. High energy = hills = “unlikely.”
- If we can learn this landscape for a class, we can “roll” points toward the valleys to create new, realistic samples for that class.
- Key idea: One EBM per class
- Instead of one model trying to understand every class at once, they build one model per class. That helps each model focus on what makes its class unique.
- How they train each class’s EBM without extra heavy training: 1) Create a simple yes/no task for each class: “Is this row from class C or not?” 2) For the “not” examples, they don’t use real data from other classes. Instead, they invent obviously fake “negative” examples placed far away from the real data (imagine fake points sitting at the distant corners of the space). This makes the task easier and avoids confusion. 3) They feed this small task into a pre-trained classifier called TabPFN (a model that can make predictions without being retrained). From its raw outputs (called logits), they compute an “energy” function for the class. 4) To generate new data, they start with points near real examples and use a sampling method called SGLD (Stochastic Gradient Langevin Dynamics). Think of SGLD as nudging points downhill toward valleys (more likely regions) while adding a small random shake so they don’t get stuck.
Because they pick the class first (using the original class distribution) and then sample within that class’s EBM, they exactly keep the original balance of labels.
4. What did they find, and why does it matter?
Here are the main results the authors report across many real datasets and settings:
- Better accuracy with small datasets:
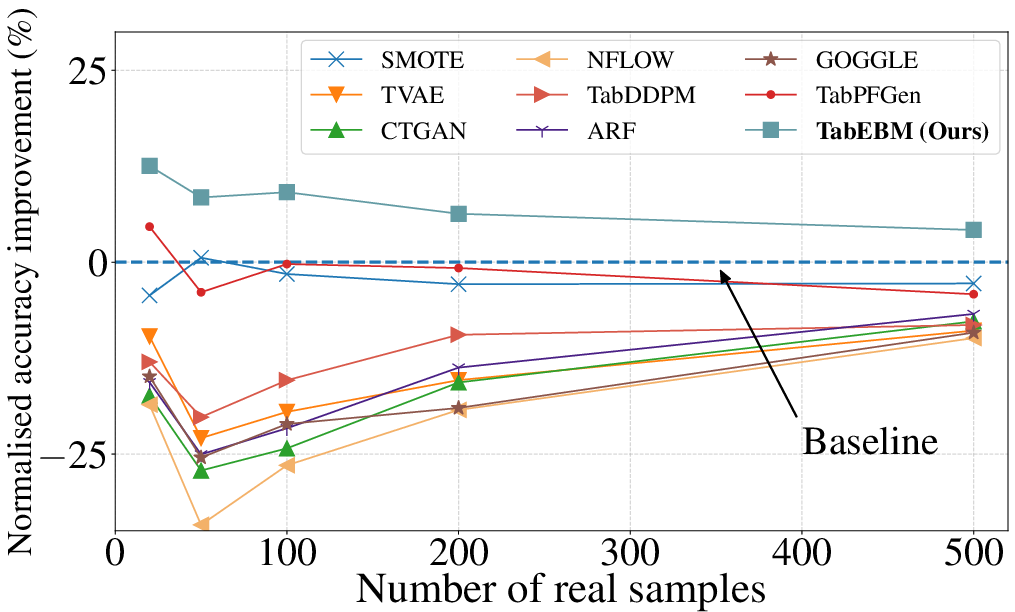
- When they added their synthetic data to the real training data, classifiers usually became more accurate—especially when the real dataset was tiny. Many other generators actually made performance worse in these cases.
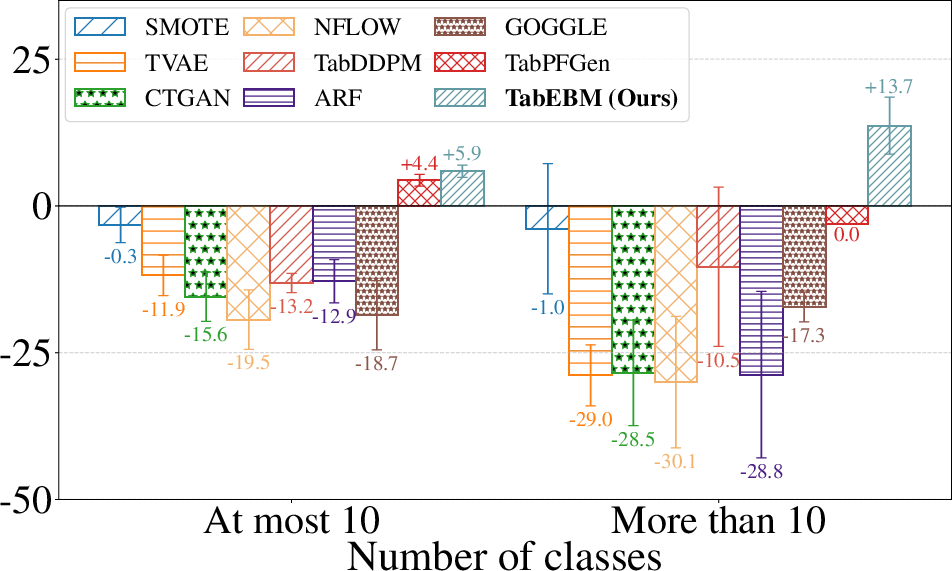
- Keeps label balance and handles many classes:
- Because they generate data separately per class, they preserve the original class distribution and work well even when there are more than 10 classes (where some methods struggle).
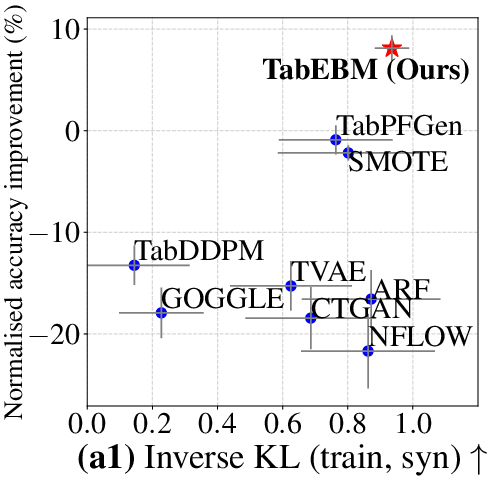
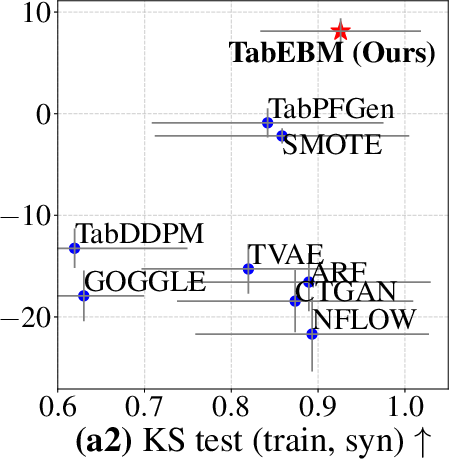
- Higher “fidelity” (data looks statistically like the real thing):
- Their synthetic data matches the real data’s patterns more closely across several statistical tests.
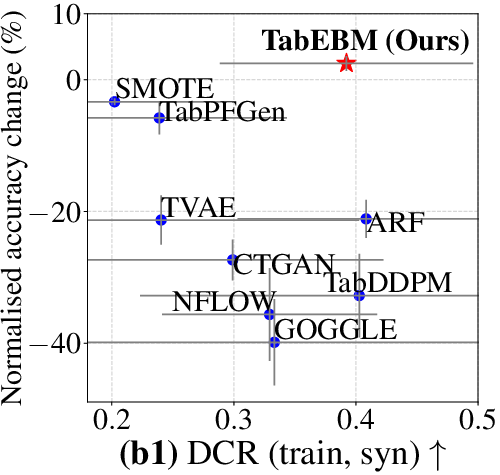
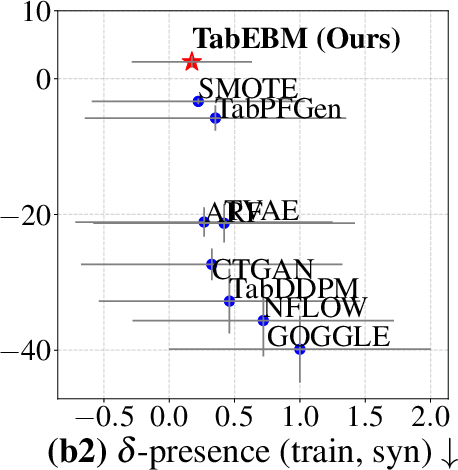
- Useful for privacy:
- In “train only on synthetic data, test on real data” experiments, their method did better than others and even beat training only on the small real data. This suggests you could share synthetic data to protect privacy while keeping good performance.
- Their synthetic data is also less likely to be direct copies of real records (a privacy win).
- Robust and efficient:
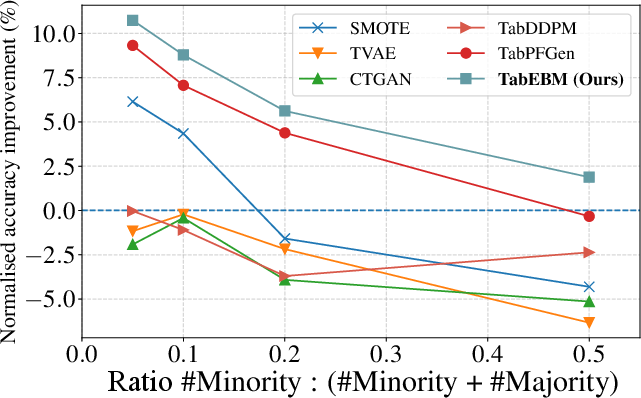
- Works better under class imbalance (when some classes are rare).
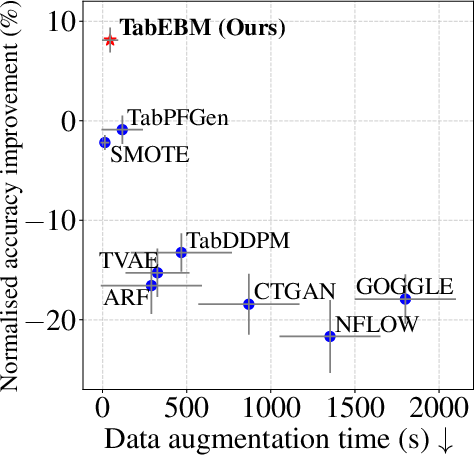
- Faster than many competing methods and less sensitive to tricky settings.
Why this matters: In real life, especially in medicine or chemistry, we often have limited, sensitive data. A generator that boosts accuracy, respects label balance, protects privacy, and runs efficiently is very practical.
5. What’s the potential impact?
- Better tools for small-data fields: Hospitals, labs, and companies could train more accurate models even with scarce data.
- Safer data sharing: Organizations might share high-quality synthetic datasets that protect patient or customer privacy.
- Easy to use: The authors provide an open-source library, so teams can try this technique without heavy training or complex tuning.
- Future directions: Although they used TabPFN to build their energy functions, the idea can work with other classifiers that output logits—opening the door to broader applications and improvements.
In short, TabEBM is a smart, class-by-class way to make realistic synthetic table rows. It helps models learn better from small datasets, keeps label balance, and supports privacy—all with solid speed and reliability.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored, phrased to guide actionable follow-up research.
- Lack of theoretical justification for the energy formulation: There is no formal proof that the class-specific energy defined as negative log-sum-exp of logits from the surrogate binary classifier approximates a valid class-conditional density p(x|y=c), nor conditions under which it is consistent or calibrated.
- Unclear convergence and mixing of SGLD sampling: The paper does not provide diagnostics or guarantees on SGLD mixing, effective sample size, independence across samples, or robustness to initialization; a principled schedule for step size/noise and stopping criteria remains open.
- Sensitivity to SGLD hyperparameters per class: While stability is claimed, there is no systematic, per-class sensitivity analysis or automatic tuning strategy for step size, noise, number of steps, burn-in, thinning, and initialization radius, especially in high-D or highly imbalanced regimes.
- Starting near real data may bias toward memorization: Initializing SGLD close to real points could limit diversity and increase privacy risk; the impact of alternative initializations (e.g., pure noise, annealed schemes) on diversity/coverage and privacy is not explored.
- Handling discrete/categorical features during gradient-based sampling is under-specified: The paper does not detail how SGLD respects one-hot constraints, integer/binary domains, ordinal structure, or mixed-type variables; projection/rounding schemes and their effect on distributional fidelity and gradients are not evaluated.
- Constraint validity is not guaranteed: There is no mechanism to enforce domain constraints (e.g., bounds, logical rules, sum-to-one, monotonicity, business rules) or multi-feature validity; assessing and enforcing constraint satisfaction is an open problem.
- Treatment of missing values is not described: It is unclear how missingness patterns (MCAR/MAR/MNAR) are handled during training and sampling, and how imputation or explicit modeling affects the learned energies and generated data.
- Hypercube negative-sample design lacks principled guidance: The number, placement, scaling (αnegdist·σd), and geometry of negatives are heuristic; there is no analysis for high dimensions, correlated features (Mahalanobis vs Euclidean), or adaptive/learned negative sampling strategies.
- Scalability to high dimensionality and many classes is untested: Experiments cap at ~77 features and ≤26 classes; it is unknown how performance, runtime, and memory scale to hundreds/thousands of features or 100+ classes, where per-class EBMs and per-class SGLD may become prohibitive.
- Dependence on TabPFN is not fully disentangled: Claims of generality (“any gradient-based classifier”) are not validated; there are no ablations replacing TabPFN with alternative backbones (e.g., FT-Transformer, MLP, TabTransformer), nor discussion on what happens with non-differentiable models (e.g., tree ensembles).
- Potential data leakage from TabPFN’s meta-training remains a concern: Although some leakage-free UCI datasets are included, a formal leakage audit across all OpenML tasks is missing; the true independence of evaluation from TabPFN’s meta-training distribution is uncertain.
- Logit calibration and temperature effects are not studied: The energy scale derives from raw logits; how logit calibration/temperature scaling affects the energy landscape, gradients, sampling stability, and fidelity is unknown.
- Diversity and joint-distribution fidelity are under-measured: The evaluation emphasizes per-feature tests (KS, χ2) and inverse KL; joint and high-order dependencies (e.g., pairwise MI, PRD/FD metrics for tabular, classifier two-sample tests) and mode coverage vs precision trade-offs are not reported.
- Optimal synthetic-to-real ratio (Nsyn) is acknowledged as open but not addressed: A fixed Nsyn=500 is used; there is no method to adapt Nsyn per dataset/class/predictor, nor analysis of diminishing returns or over-sampling risks.
- Robustness to extreme class imbalance and few-shot classes is limited: While some imbalance experiments are included, scenarios with 1–2 examples per class (or zero-shot extrapolation) are not analyzed; the minimum number of positives needed per class for stable energies is unknown.
- Behavior under label noise is unexplored: The effect of mislabeled training points on the surrogate binary classifier, energy landscape, sampling, and downstream performance has not been assessed.
- No formal privacy guarantees: Privacy is evaluated with DCR and δ-presence, but there are no differential privacy guarantees, membership/attribute inference audits, or formal privacy-utility trade-off analyses; DP-SGLD or other DP mechanisms are not explored.
- Rebalancing via synthetic label sampling is not evaluated: Although the method can sample any class distribution, experiments do not test targeted rebalancing for minority classes or its effect on fairness and performance.
- Generalization under distribution shift is unknown: All evaluations use i.i.d. splits; robustness to covariate/label shift, temporal drift, and domain adaptation settings is not studied.
- Applicability beyond multiclass classification is untested: Extensions to multilabel, ordinal classification, regression, survival analysis, and time-to-event tabular tasks are open questions.
- Multi-table/relational data are not addressed: The method is limited to single-table settings; generating consistent relational data (foreign-key constraints, cross-table dependencies) remains open.
- Comparison to class-wise classical density estimators is missing: Baselines such as class-specific KDE/GMM/NADE, or a single EBM with class-specific heads, are not included; this leaves a gap in understanding where TabEBM’s gains come from.
- Outlier influence and robust scaling are not analyzed: Using σd to scale negative samples may be sensitive to outliers/heavy tails; the effect of robust scales (MAD, quantile ranges) and outlier handling on energy quality is unknown.
- Sampling efficiency and reuse are not optimized: There is no exploration of parallel or amortized samplers, persistent chains, or learned samplers to reduce per-class sampling costs.
- Interpretability of class-specific energies is not developed: Tools to visualize, validate, and debug energy landscapes (e.g., feature attributions on energy, counterfactual traversals) are absent, limiting practical adoption in high-stakes domains.
- Fairness impacts are not measured: The effect of augmentation on subgroup performance, disparity amplification, and fairness metrics is not reported, especially when rebalancing or class-specific sampling is used.
- Mechanistic understanding of TabPFN’s “distance-based uncertainty” is preliminary: The empirical observation that logits decay with distance lacks a formal characterization (e.g., Lipschitzness, uncertainty calibration), and it is unknown whether this holds for other backbones or data types.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that leverage TabEBM’s class-specific, training-free tabular augmentation and its open-source library.
- Healthcare/Clinical AI — Improve small-sample classifiers (diagnosis, triage, risk prediction)
- What to do: Use TabEBM to augment scarce EHR/lab/omics tabular datasets per class, preserving label distribution and boosting model accuracy in low-data settings (e.g., rare disease classification).
- Tools/workflow: Add TabEBM as a data-prep step in pipelines for XGBoost/RF/LogReg; generate class-stratified synthetic samples (e.g., N_syn ≈ 500) before training; evaluate via validation set.
- Assumptions/dependencies: Requires class labels and basic preprocessing (scaling/encoding); not a formal privacy mechanism—use for augmentation internally, not as a DP guarantee.
- Chemistry/Pharma/Materials — QSAR/toxicity/property prediction with small tabular datasets
- What to do: Augment per-class molecular descriptors or material features to stabilize training and reduce overfitting in low-N regimes.
- Tools/workflow: Integrate TabEBM into cheminformatics/R&D pipelines (e.g., scikit-learn + RDKit descriptors + TabEBM augmentation).
- Assumptions/dependencies: Encoding of categorical features must align with TabEBM’s preprocessing; distributions must be stationary enough that class-conditional modeling is meaningful.
- Manufacturing/Quality Control — Imbalanced defect detection
- What to do: Use class-specific EBMs to oversample minority defect classes without collapsing modes; maintain true defect/non-defect proportions in generated data.
- Tools/workflow: Insert TabEBM into MLOps line for QC classifiers; schedule generation per new production batch to re-balance training data.
- Assumptions/dependencies: Assumes access to at least a few minority samples per class; negative-sample hypercube distance set sufficiently far from real data as per library defaults.
- Finance — Rare-event modeling (fraud, default), tabular risk analytics
- What to do: Augment minority classes (e.g., fraud) to improve recall without distorting class priors; enable privacy-friendly internal analytics by training on synthetic augmentation.
- Tools/workflow: Use TabEBM as a pre-training augmentation tool for supervised models; maintain class proportions via per-class sampling.
- Assumptions/dependencies: Regulatory use requires additional privacy safeguards; TabEBM improves utility/privately shares trends but is not a formal DP mechanism.
- Energy/Utilities — Multi-class event/fault classification with small logged datasets
- What to do: Augment per event class to handle >10 classes, where other generators fail or degrade; preserve stratification to avoid label drift.
- Tools/workflow: Embed TabEBM in event-classification pipelines; retrain periodically with augmented data from scarce failure events.
- Assumptions/dependencies: Label quality is critical; distributions may drift—retrain and regenerate as systems change.
- Software/Data Science Tooling — AutoML/ML pipelines for tabular tasks
- What to do: Provide “class-aware augmentation” step out of the box in AutoML; fall back to TabEBM when data <500 samples or classes are imbalanced.
- Tools/workflow: Package TabEBM as a scikit-learn/MLFlow transformer; expose simple API (fit_transform) or microservice for synthetic sampling per class.
- Assumptions/dependencies: Requires models that can consume continuous and encoded categorical features; aligns well with LR/RF/XGBoost/MLP/TabPFN.
- Academia/Research — Benchmarking, method validation, and teaching in low-data regimes
- What to do: Use TabEBM to create robust augmentation baselines in papers and courses; analyze augmentation effects vs. dataset size/class count.
- Tools/workflow: Include TabEBM in experimental stacks to standardize augmentation and stratification; combine with ADTM metrics for reporting.
- Assumptions/dependencies: Must avoid leakage if pre-trained PFN-like classifiers overlap with evaluation sets; select leakage-free datasets for fair comparisons.
- Privacy-Conscious Data Sharing (internal/external) — Synthetic-only training with utility
- What to do: Share TabEBM-generated datasets to external collaborators/vendors to prototype models while retaining strong utility-privacy trade-offs (high DCR, lower δ-presence).
- Tools/workflow: Provide a “synthetic sandbox” with TabEBM-generated data; downstream users train on synthetic-only, evaluate on internal real test sets.
- Assumptions/dependencies: Not a formal DP solution; add DP/contractual safeguards for regulated data; curate fields to avoid direct identifiers.
- Small Businesses/Nonprofits/Education — Practical modeling with tiny datasets
- What to do: Augment small CRM, sales, or survey datasets per class to improve basic classifiers for churn, lead scoring, or program targeting.
- Tools/workflow: Use TabEBM library with simple settings; retrain frequently as new real data arrives.
- Assumptions/dependencies: Requires minimal labeled data per class; basic ML literacy to monitor overfitting and performance shifts.
Long-Term Applications
These applications require further research, scaling, or integration with additional technologies.
- Healthcare & Public Health — Regulatory-grade synthetic data sharing and clinical validation
- What to build: Combine TabEBM with formal privacy (e.g., DP, k-anonymity wrappers) and auditing for compliant data sharing; validate clinically on EHR/omics cohorts.
- Potential products: “Clinical Synthetic Data Exchange” platforms enabling multi-hospital collaboration, sandbox trials, and external audits.
- Assumptions/dependencies: Formal privacy guarantees, IRB/ethics approvals, rigorous external validation and monitoring for distribution shifts.
- Cross-Institution Collaboration — Federated/synthetic hybrids for multi-site learning
- What to build: Use per-class TabEBM locally at each site to generate shareable synthetic surrogates that preserve label stratification for cross-site model pretraining.
- Potential products: Federated pipelines with synthetic “hints” to accelerate convergence; privacy-aware model hubs.
- Assumptions/dependencies: Harmonized schemas, feature encodings, and quality assurance across sites; governance for privacy and bias.
- Active Learning & Targeted Data Acquisition — EBM-guided sampling
- What to build: Use energy landscapes per class to identify low-density/high-uncertainty regions for human labeling, focusing scarce labeling budget efficiently.
- Potential products: “Acquisition-as-a-service” tools that suggest new samples per class to reduce generalization error.
- Assumptions/dependencies: Reliable calibration of energy to uncertainty across domains; labeling workflows with domain experts.
- Safety-Critical Simulation & Stress Testing — Rare-event synthesis
- What to build: Generate edge-case tabular scenarios (e.g., extreme lab values, unusual sensor combinations) per class for stress-testing ML systems in healthcare, energy, and manufacturing.
- Potential products: Scenario libraries and red-teaming suites for tabular models.
- Assumptions/dependencies: Requires domain constraints to avoid implausible combinations; may need rule-based filters or causal constraints.
- Fairness-Aware Augmentation — Bias mitigation using class- and subgroup-specific EBMs
- What to build: Extend TabEBM to condition on protected attributes (or proxies) and reweigh/augment to equalize error rates across subgroups.
- Potential products: Fairness modules that synthesize subgroup-balanced training sets with audit trails.
- Assumptions/dependencies: Ethical and legal handling of sensitive attributes; fairness objectives defined with stakeholders.
- Time-Series & Multi-Modal Extensions — Beyond static tabular data
- What to build: Extend class-specific EBMs to sequential/tabular+text or tabular+imaging inputs (e.g., patient trajectory data, device logs).
- Potential products: Synthetic event-sequence generators for operations/logistics, patient care pathways, or IoT maintenance.
- Assumptions/dependencies: Suitable differentiable encoders for discrete/temporal features; stable SGLD or alternative samplers for sequences.
- Enterprise MLOps & AutoML — Adaptive, cost-aware augmentation
- What to build: AutoML components that trigger TabEBM-based augmentation only when expected utility > threshold (e.g., low data, high imbalance), with monitoring of drift and privacy metrics.
- Potential products: “Smart Augmentation” services in cloud ML stacks (e.g., vertex-type platforms) with governance dashboards.
- Assumptions/dependencies: Policy engines for when to augment; integration with lineage/monitoring and rollback if performance degrades.
- Synthetic Data Marketplaces — Class-stratified, high-fidelity tabular products
- What to build: Curated synthetic datasets per vertical (health, finance, energy) with documented fidelity and privacy trade-offs; pay-per-use APIs.
- Potential products: Marketplaces providing labeled, class-balanced, small-data surrogates for prototyping and benchmarking.
- Assumptions/dependencies: Clear provenance, bias disclosures, and licensing; standardized metadata and validation reports.
- Cybersecurity — Tabular threat modeling and red-teaming
- What to build: Generate class-conditional synthetic intrusion/fraud signatures to harden detectors; explore low-density corners as candidate attack surfaces.
- Potential products: Synthetic attack libraries for training and evaluating detectors across organizations.
- Assumptions/dependencies: Up-to-date threat taxonomies; mechanisms to avoid overfitting to synthetic artifacts.
- Integration with Formal Privacy/Compliance — DP-TabEBM variants
- What to build: Incorporate differential privacy into the EBM training/sampling pipeline (e.g., DP-SGLD, DP calibration of logits), plus auditing and risk bounds.
- Potential products: Compliance-ready synthetic data generators for regulated sectors.
- Assumptions/dependencies: Accuracy-privacy trade-offs; parameter tuning to maintain downstream utility.
Notes on general dependencies and assumptions
- Requires labeled data and encodings that support gradient-based sampling (numerical scaling and differentiable encodings for categorical features).
- TabEBM’s reported gains are strongest in low- to medium-sample regimes and with class imbalance; performance should be re-validated on very large datasets.
- Privacy metrics reported (DCR, δ-presence) indicate favorable trade-offs but do not constitute formal guarantees; add DP or policy controls for regulated sharing.
- Hyperparameters for SGLD and negative-sample distance are impactful but the paper reports stability across a range; use library defaults, then tune with validation.
- Distribution shifts and domain constraints must be considered to avoid implausible synthetic records; apply domain rules or post-processing as needed.
Glossary
- Adversarial Random Forests (ARF): A generative approach that uses ensembles of decision trees trained in an adversarial setup to model complex tabular distributions. "Adversarial Random Forests (ARF)"
- Affine renormalisation: A linear rescaling technique used to put different performance scores on a common scale for comparison. "via affine renormalisation"
- Average distance to the minimum (ADTM): A benchmark statistic measuring how far a model’s performance is from the best-performing model after normalisation. "average distance to the minimum (ADTM) metric"
- Bayesian inference: A statistical framework that updates beliefs (probability distributions) about parameters given data; here, approximated by a meta-trained model. "approximate Bayesian inference"
- Chi-squared test (χ2 test): A statistical test assessing whether observed frequencies differ from expected ones (goodness-of-fit/independence). "Chi-squared test ( test)"
- Class-conditional distribution: The probability distribution of inputs conditioned on a class label, p(x|y). "class-conditional distribution "
- Data leakage: Unintended sharing of information between training and evaluation that inflates performance estimates. "data leakage"
- Delta-presense (δ-presense): A privacy metric quantifying the maximum probability that a real individual is present in the dataset given access to synthetic data. "-presense"
- Diffusion model: A generative model that learns to reverse a gradual noising process to sample from complex distributions. "a diffusion model TabDDPM"
- Empirical distribution: The observed label or feature distribution estimated directly from the data. "from the empirical distribution"
- Energy landscape: The shape of the energy function over input space that determines where high- and low-probability regions lie. "the energy landscape"
- Energy-Based Model (EBM): A generative framework defining density via an energy function, p(x) ∝ exp(−E(x)). "An Energy-Based Model (EBM)"
- Euclidean distance: The standard L2 distance used to measure how far points are in feature space. "the Euclidean distance"
- Generative Adversarial Network (GAN): A framework with a generator and discriminator trained adversarially to synthesize realistic samples. "Generative Adversarial Networks (GAN)"
- Graph Neural Network (GNN): Neural architectures that process graph-structured data by aggregating neighborhood information. "Graph Neural Network (GNN)"
- Hypercube: A D-dimensional generalization of a cube used here to place negative samples far from real data. "corners of a hypercube in~"
- Imbalanced dataset: A dataset where some classes have substantially more samples than others, often causing biased learning. "imbalanced datasets"
- In-context model: A model that performs task-specific inference conditioned on a provided training set without parameter updates. "tabular in-context model"
- Joint distribution: The combined distribution over inputs and labels, p(x, y). "joint distribution "
- Kolmogorov–Smirnov test (KS test): A nonparametric test comparing two distributions based on the maximum difference between their CDFs. "KolmogorovâSmirnov test (KS test)"
- Kullback–Leibler divergence (KL divergence): An information-theoretic measure of how one probability distribution differs from another. "KullbackâLeibler Divergence (inverse KL)"
- Logit: The unnormalised pre-softmax score output by a classifier for a given class. "the (unnormalised) logit"
- LogSumExp: A numerically stable operation computing log(∑ exp(.)) used to aggregate logits into energies or probabilities. "LogSumExp"
- Marginal distribution: The distribution over a subset of variables obtained by summing/integrating out others. "marginal distribution "
- Marginalisation: The operation of summing/integrating out variables to obtain a marginal distribution. "by marginalisation:"
- Mode collapse: A failure mode of generators that produce limited diversity by mapping many inputs to a few outputs. "mode collapse"
- Neural spline flow (Normalising flow): An invertible transformation model that maps a simple base distribution into a complex target distribution. "a normalising flow model Neural Spine Flows (NFLOW)"
- Normalisation constant (Z): The partition function ensuring that probabilities sum/integrate to one. "( is the normalisation constant)"
- Prior-Data Fitted Networks (PFN): Meta-trained models that perform fast, approximate Bayesian-like inference conditioned on a given dataset. "Prior-Data Fitted Networks (PFN)"
- Statistical fidelity: The degree to which synthetic data matches the statistical properties of real data. "statistical fidelity"
- Stochastic Gradient Langevin Dynamics (SGLD): A sampling method combining gradient ascent on log-density with injected Gaussian noise. "Stochastic Gradient Langevin Dynamics (SGLD)"
- Stratification: Preserving class proportions across splits or generated samples to maintain label distribution. "stratification of the original data"
- Stratified generation: Class-aware generation that matches desired class proportions in synthetic data. "support stratified generation"
- Surrogate binary classification task: An auxiliary two-class setup (real-vs-negative) used to derive a class-specific energy function. "surrogate binary classification task"
- Train-on-synthetic, test-on-real: An evaluation setup where models are trained only on synthetic data and evaluated on real data. "train-on-synthetic, test-on-real"
- Unnormalised negative log-density: The energy function E(x), proportional to the negative log probability without the normalisation constant. "unnormalised negative log-density"
- Variational Autoencoder (VAE): A latent-variable generative model trained to maximise a variational lower bound on the data likelihood. "Variational Autoencoders (VAE)"
Collections
Sign up for free to add this paper to one or more collections.