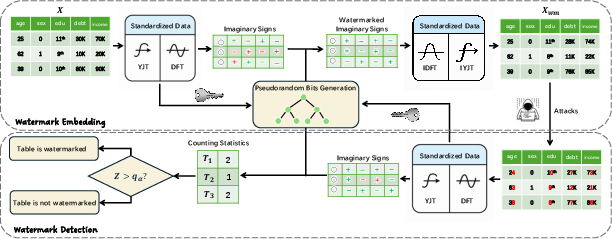
- The paper introduces Tab-Drw, a post-editing watermarking scheme using DFT to embed robust watermarks in generative tabular data while preserving fidelity.
- It employs a rank-based pseudorandom bit generation mechanism that ensures stable watermark detection even after adversarial modifications like deletions and noise.
- Empirical evaluations on multiple datasets reveal minimal performance degradation (<1%) and superior detectability under diverse post-processing attacks.
TAB-DRW: A DFT-based Robust Watermark for Generative Tabular Data
Motivation and Challenges in Tabular Watermarking
The rapid proliferation of high-fidelity generative tabular data in regulated sectors (e.g., healthcare, finance, social policy) has elevated issues of data provenance, copyright, and post-hoc misuse. Robust watermarking is a practical solution for ownership assertion and traceability, but existing tabular watermarking approaches suffer key limitations, such as high computational costs stemming from reliance on generative diffusion models, inapplicability to mixed-type (discrete-continuous) data, and lack of robustness against adversarial post-processing (row/column deletions, noise injection, discretization).
TAB-DRW: Frequency-Domain Post-Editing Watermarking
This work introduces Tab-Drw, a post-editing watermarking scheme exploiting the frequency domain structure via Discrete Fourier Transform (DFT) to attain robust, high-fidelity watermarks for generative tabular data. The core procedure is as follows:
This approach is model-agnostic, computationally efficient (no generative model reevaluation required), and compatible with mixed discrete/continuous tabular data via post-hoc quantization and value clamping.
Pseudorandom Bit Generation: Rank-Based Scheme
Watermarking robustness is directly tied to the stability of bit generation under post-processing. To this end, the authors propose a rank-based retrieval mechanism: For each row, a secret-key-determined subset of columns is summed to produce a statistic whose row-wise rank is then mapped (via a tree structure reminiscent of a 2-Gray code encoder) to a leaf that defines the deterministically generated bit sequence. Since small perturbations rarely change the rank order over N rows, the bits are highly robust to moderate attacks.
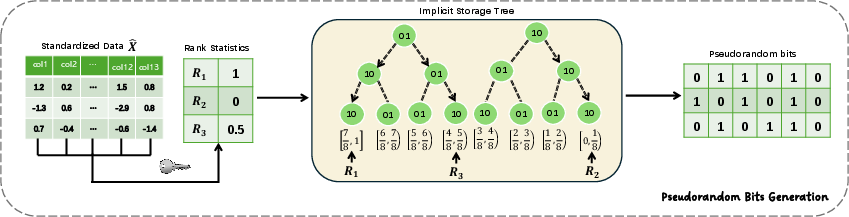
Figure 2: Illustration of the row-wise rank-based traversal for pseudorandom bit sequence generation for each table row.
The authors provide explicit theoretical analyses quantifying entry-wise distortion, column-level distributional shift, and the preservation of essential statistics (means, pairwise correlations) under watermarking. The linearity and symmetry of the DFT/IDFT pipeline ensure:
- Column means are exactly unchanged.
- Empirical distributional shift (measured by Wasserstein-2 distance) is tightly upper-bounded as a function of the embedding hyperparameters and feature covariance.
- Under standard normality and independence assumptions, the watermark-specific Z-score statistic displays an exponential separation between watermarked and unwatermarked data, provably surviving additive Gaussian noise and a spectrum of partial-deletion attacks.
The theory is extended to sub-Gaussian data, encompassing bounded, quantized, or discrete distributions.
Empirical Evaluations
Comprehensive experiments on five public datasets (Adult, Magic, Shoppers, Default, Drybean) and multiple generative models (TabSyn, TabDDPM, STaSy) demonstrate:
- High fidelity: Distortion metrics (density alignment, inter-column correlation, C2ST indistinguishability, downstream ML performance) degrade by less than 1% relative to the original data, outperforming or matching prior art.
- Strong detectability: The Z-score and TPR/FPR metrics are optimal for most datasets, with critical values robust to varying table sizes.
- Superior robustness: Tab-Drw achieves consistently high watermark detectability after attacks including 10–20% row/column/cell deletion, quantization, discretization, and both random and adaptive noise addition. Competitors’ TPR drops precipitously under these conditions.
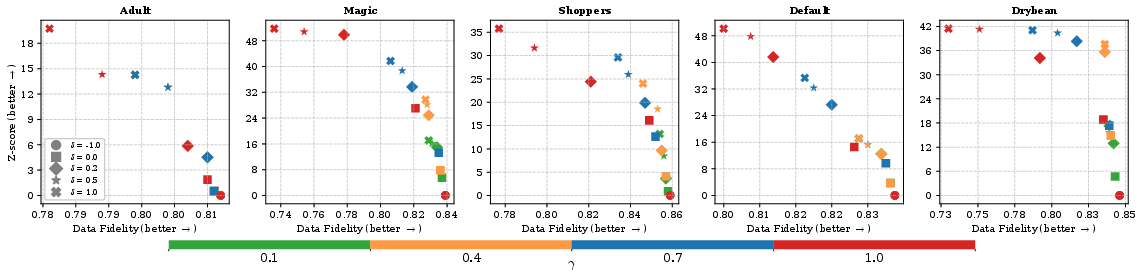
Figure 3: Trade-off curve between watermark Z-score and data fidelity as hyperparameters (γ,δ) vary.
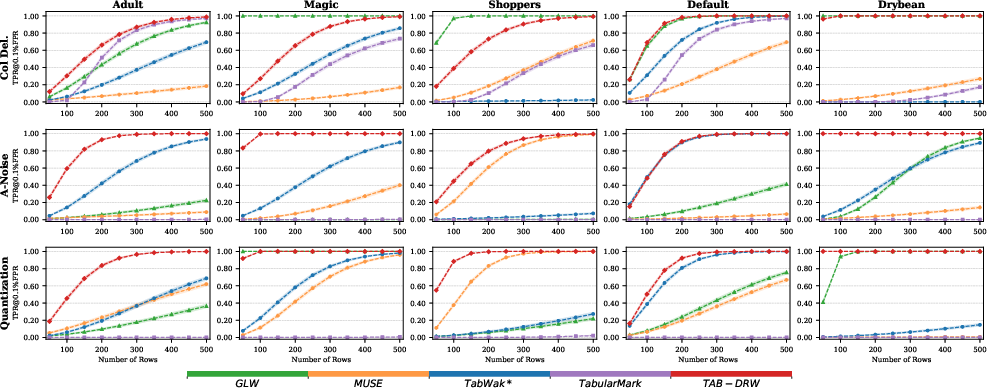
Figure 4: [email protected]% FPR for Tab-Drw versus row count under representative attacks and datasets, indicating rapid rise to near-perfect detectability with modest table sizes.
- Resilience to adaptive attacks: Even when adversaries attempt to disrupt rank statistics via targeted row deletion or keyless “re-watermarking,” Tab-Drw maintains high Z-scores, unless fidelity is explicitly sacrificed.
Additional ablations confirm the low impact of rounding, the benefit of YJT, and the robustness to column selection strategies. Handling of low-cardinality categorical variables is shown to be semantically consistent—flips are rare and typically associated with misclustered or marginal samples.
Implementation and Deployment Considerations
Tab-Drw is efficient for both embedding and detection: post-editing requires seconds per 1k rows on CPU, far outpacing methods dependent on generative model inversion. A privacy-enhanced variant is provided, supporting multi-key scenarios via keyed column permutations, with empirical results confirming a negligible false positive rate for key collisions.
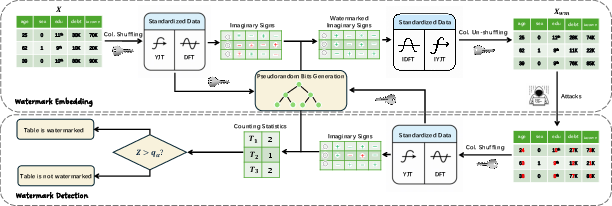
Figure 5: Overview of privacy-enhanced pipeline workflow, accommodating multi-user secret keys.
Theoretical and Practical Implications
Tab-Drw establishes a new watermarking paradigm for tabular data, balancing fidelity, efficiency, applicability, and robustness against adversarial post-processing. Its post-editing design sidesteps the computational bottlenecks and architectural dependencies of earlier diffusion/generative watermarking schemes, while enabling formal analysis reminiscent of recent works on text watermarking for LLMs (see (2511.21600) for extended related work).
From the perspective of practical governance, Tab-Drw enables scalable, model-agnostic watermark deployment for synthetic data in high-risk domains. The mechanism is suitable for both private stewardship and third-party auditing of generative outputs.
Future Directions
Further work should formalize optimal DFT perturbation trade-offs for arbitrary tabular distributions, investigate differentially private variants, and explore adaptive strength assignment based on downstream application sensitivity.
Conclusion
Tab-Drw resolves core challenges in robust watermarking for generative tabular data by leveraging frequency-domain row-wise modifications and a rank-based stable pseudorandom bit mechanism. It guarantees strong watermark detectability and high data utility across heterogeneous datasets, and demonstrates provable and empirical resilience to a wide attack surface—all with efficient, post-editing operation and applicability to practically relevant mixed-type tables (2511.21600).