Large Language Models Can Learn Temporal Reasoning
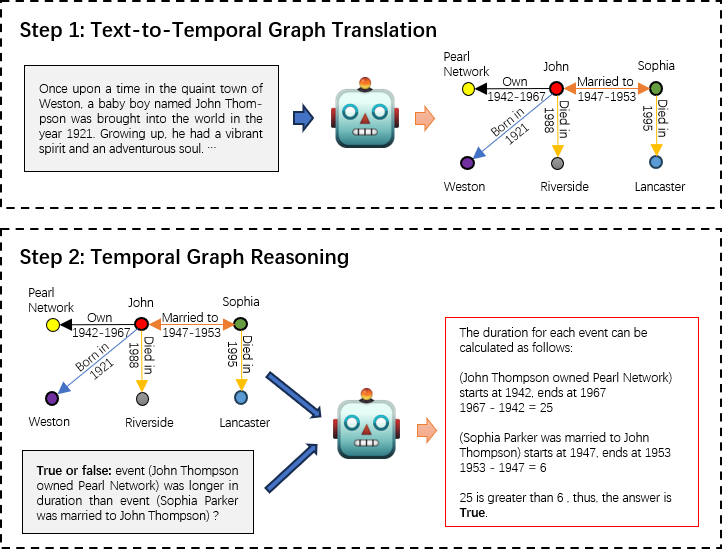
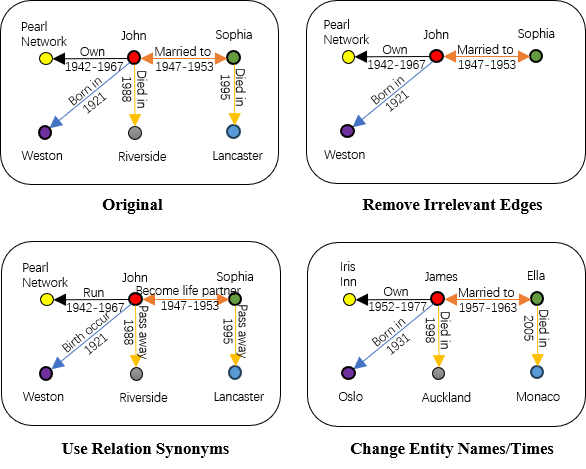
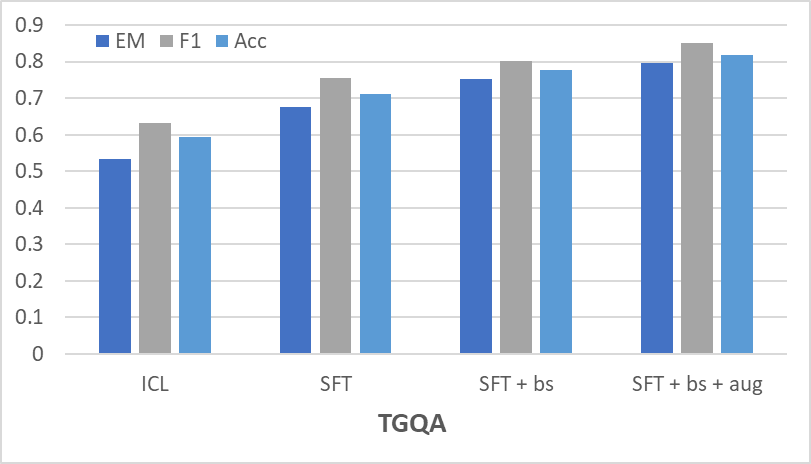
Abstract: While LLMs have demonstrated remarkable reasoning capabilities, they are not without their flaws and inaccuracies. Recent studies have introduced various methods to mitigate these limitations. Temporal reasoning (TR), in particular, presents a significant challenge for LLMs due to its reliance on diverse temporal concepts and intricate temporal logic. In this paper, we propose TG-LLM, a novel framework towards language-based TR. Instead of reasoning over the original context, we adopt a latent representation, temporal graph (TG) that enhances the learning of TR. A synthetic dataset (TGQA), which is fully controllable and requires minimal supervision, is constructed for fine-tuning LLMs on this text-to-TG translation task. We confirmed in experiments that the capability of TG translation learned on our dataset can be transferred to other TR tasks and benchmarks. On top of that, we teach LLM to perform deliberate reasoning over the TGs via Chain-of-Thought (CoT) bootstrapping and graph data augmentation. We observed that those strategies, which maintain a balance between usefulness and diversity, bring more reliable CoTs and final results than the vanilla CoT distillation.
- A dataset for answering time-sensitive questions.
- Timebench: A comprehensive evaluation of temporal reasoning abilities in large language models.
- Hyte: Hyperplane-based temporally aware knowledge graph embedding. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 2001–2011.
- Learning sequence encoders for temporal knowledge graph completion. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4816–4821, Brussels, Belgium. Association for Computational Linguistics.
- Wes Gurnee and Max Tegmark. 2023. Language models represent space and time.
- Is neuro-symbolic ai meeting its promises in natural language processing? a structured review. Semantic Web, (Preprint):1–42.
- Large language models are reasoning teachers.
- Lora: Low-rank adaptation of large language models.
- Do large language models know about facts?
- Jie Huang and Kevin Chen-Chuan Chang. 2023. Towards reasoning in large language models: A survey.
- Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213.
- Recallm: An adaptable memory mechanism with temporal understanding for large language models.
- Kalev Leetaru and Philip A Schrodt. 2013. Gdelt: Global data on events, location, and tone, 1979–2012. In ISA annual convention, volume 2, pages 1–49. Citeseer.
- Retrieval-augmented generation for knowledge-intensive nlp tasks.
- Unlocking temporal question answering for large language models using code execution.
- Grounding complex natural language commands for temporal tasks in unseen environments.
- Tlogic: Temporal logical rules for explainable link forecasting on temporal knowledge graphs.
- Chatrule: Mining logical rules with large language models for knowledge graph reasoning.
- Joint reasoning for temporal and causal relations.
- Torque: A reading comprehension dataset of temporal ordering questions.
- Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114.
- Time is encoded in the weights of finetuned language models.
- OpenAI. 2023. Gpt-4 technical report.
- Training language models to follow instructions with human feedback.
- Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning.
- Ali Payani and Faramarz Fekri. 2019a. Inductive logic programming via differentiable deep neural logic networks.
- Ali Payani and Faramarz Fekri. 2019b. Learning algorithms via neural logic networks.
- Lis Kanashiro Pereira. 2022. Attention-focused adversarial training for robust temporal reasoning. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 7352–7359.
- Timedial: Temporal commonsense reasoning in dialog.
- Are large language models temporally grounded?
- Rnnlogic: Learning logic rules for reasoning on knowledge graphs.
- Time masking for temporal language models.
- Language models are greedy reasoners: A systematic formal analysis of chain-of-thought.
- Neuro-symbolic artificial intelligence. AI Communications, 34(3):197–209.
- Neuro-symbolic ai: An emerging class of ai workloads and their characterization.
- Leap-of-thought: Teaching pre-trained models to systematically reason over implicit knowledge. Advances in Neural Information Processing Systems, 33:20227–20237.
- Towards benchmarking and improving the temporal reasoning capability of large language models.
- Towards robust temporal reasoning of large language models via a multi-hop qa dataset and pseudo-instruction tuning.
- Llama: Open and efficient foundation language models.
- Llama 2: Open foundation and fine-tuned chat models.
- Large language models still can’t plan (a benchmark for llms on planning and reasoning about change). arXiv preprint arXiv:2206.10498.
- Scott: Self-consistent chain-of-thought distillation.
- Yuqing Wang and Yun Zhao. 2023. Tram: Benchmarking temporal reasoning for large language models.
- Chain-of-thought prompting elicits reasoning in large language models.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Menatqa: A new dataset for testing the temporal comprehension and reasoning abilities of large language models.
- Tilp: Differentiable learning of temporal logical rules on knowledge graphs. In The Eleventh International Conference on Learning Representations.
- Teilp: Time prediction over knowledge graphs via logical reasoning. arXiv preprint arXiv:2312.15816.
- Gentopia: A collaborative platform for tool-augmented llms.
- Differentiable learning of logical rules for knowledge base reasoning.
- Once upon a Time in Graph: Relative-time pretraining for complex temporal reasoning.
- Neuro-symbolic integration brings causal and reliable reasoning proofs.
- Learn to explain efficiently via neural logic inductive learning.
- Harnessing the power of large language models for natural language to first-order logic translation.
- Improving event duration prediction via time-aware pre-training.
- Tree of thoughts: Deliberate problem solving with large language models.
- Back to the future: Towards explainable temporal reasoning with large language models.
- Making large language models perform better in knowledge graph completion.
- "going on a vacation" takes longer than "going for a walk": A study of temporal commonsense understanding.
- Temporal common sense acquisition with minimal supervision.
- Temporal reasoning on implicit events from distant supervision.
- Large language models can learn rules.
- Toolqa: A dataset for llm question answering with external tools.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.