- The paper introduces a two-stage adaptation using MultiFLARE reconstruction and encoder tuning to build personalized, high-precision 3D face avatars from unconstrained videos.
- It employs innovative metrics like Semantic IoU and image warping for objective, pose-agnostic evaluation of facial geometry.
- The method bridges the gap between real-time capture and high-fidelity results, advancing applications in AR and digital face animation.
SPARK: Self-supervised Personalized Real-time Monocular Face Capture
Introduction to Monocular Face Capture
3D facial performance capture is integral to applications requiring detailed visual representations, such as augmented reality (AR) telepresence and visual effects. Conventional capture techniques necessitate substantial resources, including sophisticated hardware and comprehensive actor involvement. These methodologies encompass high-cost setups for 3D capture [debevec2000acquiring], marker-based systems [bennett2014adopting], and head-mounted displays [brito2019recycling], often leading to complex procedures with limited scalability.
Recent trends favor monocular face capture solutions powered by neural networks capable of real-time regressing parametric 3D face models from single images [feng2021learning]. These systems, although robust to varying poses and illuminations, sacrifice geometric precision, which hampers tasks requiring high fidelity, such as face swapping and digital aging. SPARK introduces a novel self-supervised method leveraging unconstrained video databases to refine face rendering precision beyond coarse parametric models.
Method: Two-Stage Adaptation
SPARK employs a two-stage adaptation mechanism to enhance real-time monocular face capture:
- MultiFLARE Reconstruction: The initial stage constructs detailed 3D face avatars using a diverse collection of videos for individual subjects. This inverse rendering technique capitalizes on neural advances, allowing detailed geometry and appearance modeling, which are subsequently used for expressive animations.
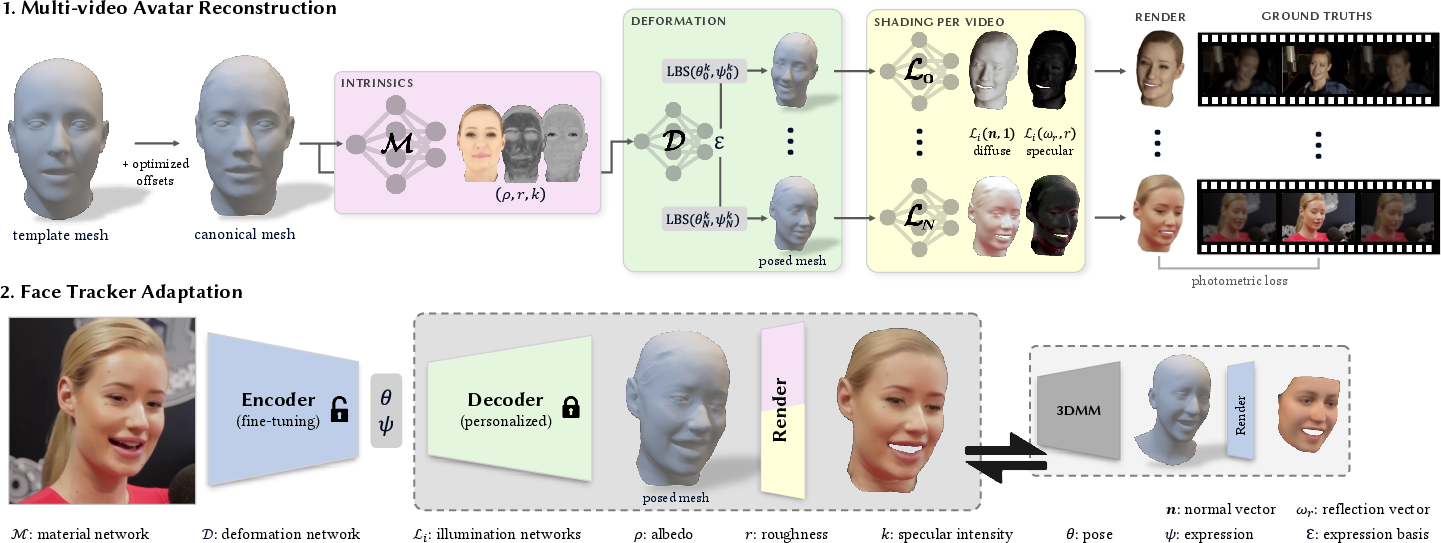
Figure 1: Illustration of our-two stage adaptation process. In stage 1, we rely on a collection of different video sources of the same person to build a personalized geometry decoder through inverse rendering.
- Encoder Tuning and Transfer Learning: The secondary phase utilizes pre-trained encoders adapted via transfer learning, utilizing the personalized geometry models obtained from MultiFLARE. This refinement process addresses shortcomings in expression and pose alignment, enabling accurate mesh recovery ubiquitously, regardless of unseen input conditions.
Extensive qualitative assessments reveal marked improvements over existing baselines, demonstrating efficacy across lighting and expressive challenges.
Empirical Evaluation and Novel Metrics
The SPARK methodology introduces innovative metrics to objectively evaluate posed geometry:
- Semantic Intersection-over-Union (IoU): This metric employs BiSeNet [yuBiSeNetBilateralSegmentation2018] to generate ground-truth semantic masks, assessing alignment independent of shading and albedo influences.






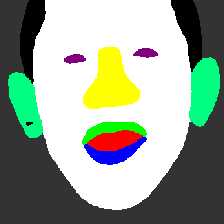


Figure 2: Illustration of our semantic Intersection-over-Union metric. Left: manually annotated semantic masks for FLAME. Right: two examples with ground-truth segmentation, a render of EMOCA's tracked mesh and our tracked mesh.
- Image Warping Metric: Utilizing tracked geometry, image pairs are warped to measure pose accuracy, considering occlusions and dynamic motions within video sequences.



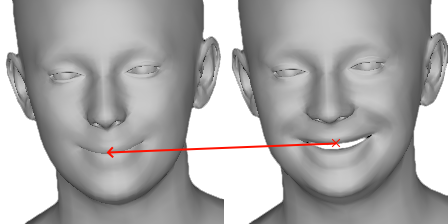
Figure 3: Illustration of our image warping metric. The background and hair are masked out in both frames. We use the tracked geometry to backtrack each rasterized pixel of image It to a pixel in image $I_{t-k}.
The evaluation comprehensive metrics demonstrate SPARK's superiority in capturing detailed dynamics in facial geometry, with quantitative confirmations across multiple subjects.
Implications and Future Directions
SPARK's approach offers transformative potential for visual effects and digital face applications, enhancing animatable avatar capabilities with limited-resource requirements. By integrating extensive video data, SPARK bridges the gap between high-precision facial models and real-time applicability, paving avenues for improved visual fidelity in consumer-grade hardware scenarios.
Future research may explore expansions of personalization strategies and the refinement of light estimating techniques to bolster robustness in variable capture environments. The adaptability of SPARK's transfer learning scheme suggests potential extensions to broader identity generalization scenarios.
Conclusion
SPARK presents a paradigm shift in monocular face capture, achieving high-quality geometric reconstructions through an innovative use of self-supervision and personalized modeling. By redefining encoder adaptation in combination with detailed MultiFLARE avatars, SPARK provides reliable real-time pose estimation and expression recovery, outperforming existing methodologies in practical applications. This work contributes significantly to advancements in face capture technology, advocating further explorations in personalized digital modeling and animation fidelity.
