FlexAvatar: Learning Complete 3D Head Avatars with Partial Supervision
Abstract: We introduce FlexAvatar, a method for creating high-quality and complete 3D head avatars from a single image. A core challenge lies in the limited availability of multi-view data and the tendency of monocular training to yield incomplete 3D head reconstructions. We identify the root cause of this issue as the entanglement between driving signal and target viewpoint when learning from monocular videos. To address this, we propose a transformer-based 3D portrait animation model with learnable data source tokens, so-called bias sinks, which enables unified training across monocular and multi-view datasets. This design leverages the strengths of both data sources during inference: strong generalization from monocular data and full 3D completeness from multi-view supervision. Furthermore, our training procedure yields a smooth latent avatar space that facilitates identity interpolation and flexible fitting to an arbitrary number of input observations. In extensive evaluations on single-view, few-shot, and monocular avatar creation tasks, we verify the efficacy of FlexAvatar. Many existing methods struggle with view extrapolation while FlexAvatar generates complete 3D head avatars with realistic facial animations. Website: https://tobias-kirschstein.github.io/flexavatar/



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces FlexAvatar, a computer system that can build a complete, animated 3D head of a person from just one photo. You can then turn the head in any direction and make it smile, talk, or change expressions. The goal is to make high‑quality avatars quickly, without special cameras or long setup times.
What questions did the researchers ask?
The paper focuses on three simple questions:
- How can we make a full 3D head from a single front photo, even though we can’t see the sides or back?
- How can we make the avatar move its face realistically, even if we’ve never seen that person make different expressions?
- Can we combine cheap, common training data (single-camera videos) with better but rare training data (multi-camera recordings) so we get both strong generalization and complete 3D heads?
How did they do it?
The team built a model that learns from two kinds of video data:
- Monocular data: videos from one camera (very common online, but mostly front views).
- Multi-view data: recordings from many cameras at once (gives full coverage, but hard to collect).
The trick is to mix these data types without teaching the model bad habits.
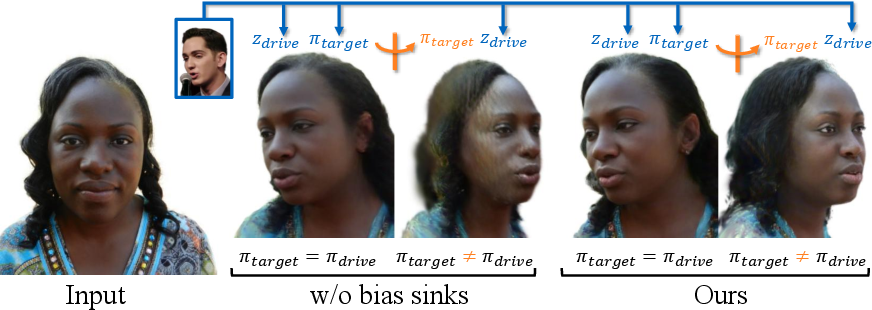
The big idea: a “mode switch” to avoid cheating
When you train only on single-camera videos, the model can “cheat.” Because the expression and the camera angle come from the same frame, the model learns to guess the viewing angle from the expression input instead of truly building a full 3D head. This leads to incomplete heads when you try to rotate the camera later.
FlexAvatar fixes this with special learnable “tokens” called bias sinks. Think of them as a simple switch the model receives during training:
- One token means “this sample is from single-camera data.”
- Another token means “this sample is from multi-camera data.”
These tokens nudge the model to handle each data type differently. During training, the model learns to absorb the quirks of single-camera data into the “single-camera token,” and to build complete 3D heads under the “multi-camera token.” At test time, the system always uses the multi-camera token so it produces a complete head from any input photo, while still benefiting from the wide variety of faces learned from single-camera videos.
The pieces of the system
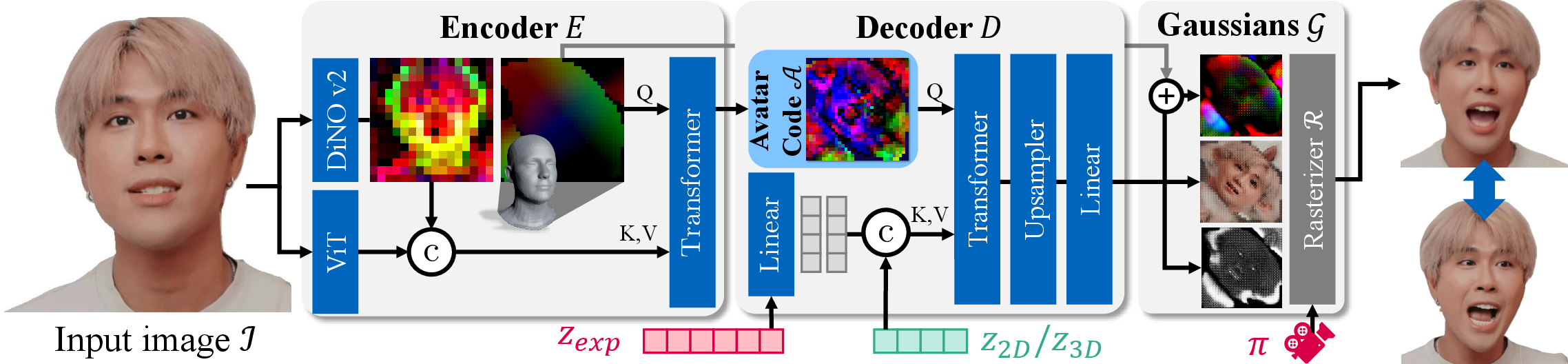
To make this work fast and look good, the system is organized into three main parts:
- Encoder: This is like a smart scanner. It reads the input photo and writes a compact “avatar code” onto a 2D template map of a head (imagine painting features onto a flattened mask). This code doesn’t lock in a camera view or an expression; it just captures the person’s identity.
- Decoder: This is like a puppeteer. It takes the avatar code and an expression signal (for example, “smile,” “open mouth,” or “turn head slightly”) and turns them into a detailed 3D representation. Instead of relying on a fixed face model with limited expressions, it learns facial motion directly from data. The bias-sink token is attached here, telling the decoder which training “mode” to follow.
- Renderer with 3D Gaussians: The 3D head is represented as many tiny, colored, soft blobs (you can imagine them as small puffs of colored mist). This approach, called 3D Gaussian Splatting, lets the computer draw realistic images of the head from any angle very quickly.
To boost visual quality, the decoder uses an upsampling design inspired by StyleGAN and PixelShuffle. In simple terms, it starts with a smaller, rough version of the face and cleverly adds detail to make it sharp, especially around eyes and mouth.
Finally, the whole setup naturally creates a smooth “avatar space,” a kind of map where nearby points represent similar faces. This makes it easy to:
- Blend identities (morph between people).
- Refine an avatar if you have more pictures or a short video (you adjust only the avatar code, keeping the model fixed, which is fast).
What did they find?
Across several tests, FlexAvatar made more complete and realistic 3D heads than other recent methods:
- Portrait animation: When animating a single photo using expressions from a video, FlexAvatar matched or beat state-of-the-art results.
- Single-image avatars with free camera: This is the hard test. Many methods break here, showing incomplete sides or backs of the head. FlexAvatar kept the head complete and maintained identity and expression quality.
- Few-shot avatars (a handful of images): Using 4 images, FlexAvatar improved sharpness and identity match while staying efficient.
- Monocular video avatars: On a public benchmark, it produced sharper, more stable results and ran faster than several strong competitors.
Why it matters: These results show you can get the best of both worlds—wide generalization from common single-camera videos and full 3D completeness from multi-camera supervision—by using the bias-sink “mode switch.”
What’s the impact?
If you can make a believable, fully rotatable 3D head from one photo in minutes, many applications become easier:
- Video calls with animated avatars that look like you.
- Personalized game characters.
- Education and AR/VR experiences.
- Fast avatar creation from a phone scan or a short video, without special hardware.
The bias-sink idea is also general. It could help in other areas where you must mix limited “perfect” data with lots of cheaper “imperfect” data, making models robust without picking up bad shortcuts.
Limitations and what’s next
- Lighting control: The lighting is “baked in” from the input photo, so changing scene lighting later is limited.
- Expression detail: In experiments, the expression signal came from an existing face model, which can miss fine details like tongue movements. The design, however, can accept richer expression inputs in the future.
Overall, FlexAvatar shows a practical path to fast, high-quality 3D head avatars from minimal input, and introduces a neat training strategy—bias sinks—that may be useful well beyond faces.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, framed so that future researchers can act on them:
- Relightability: The method bakes illumination from the input image; there is no explicit lighting model or relightable decomposition. Evaluate physically-based reflectance or learned light transport to enable lighting control and environment adaptation.
- Expression representation scope: All experiments use FLAME expression codes despite a model-agnostic design. Test with alternative drivers (audio, image-based encoders, implicit morphable models) and quantify impacts on expressiveness (tongue, teeth, mouth interior).
- Entanglement quantification: The paper argues “bias sinks” mitigate viewpoint–expression entanglement but does not directly quantify it. Develop metrics and controlled experiments that randomize driving and rendering viewpoints to measure residual leakage.
- Dataset-token generality: “Bias sinks” are implemented as two tokens (monocular vs multi-view). Explore scalability to many dataset types (e.g., synthetic, device-specific, lens/exposure), unseen datasets at inference, and adaptive routing/token selection based on input domain.
- Failure modes of bias sinks: Analyze when tokens misclassify or fail to absorb bias, and compare against alternative disentanglement strategies (adversarial training, view randomization, causal/conditional modeling).
- Use of multi-view supervision: For NeRSemble/Ava256, only the frontal camera is tracked for expression codes. Clarify whether supervision truly uses multi-view frames and ablate the effect of using all cameras on 3D completeness and generalization.
- Sensitivity to tracking noise: Cameras and expressions are extracted via Pixel3DMM; the impact of tracking errors is not studied. Perform sensitivity analyses and robust training with noisy labels or confidence-weighted supervision.
- Back-of-head plausibility: The model hallucinates unobserved regions from a single front image, but plausibility is not evaluated. Benchmark backside/head-top fidelity against multi-view scans or human studies.
- Hair, ears, and accessories: Gaussians are anchored to a template mesh; it is unclear how off-surface elements (hair, facial hair, glasses, earrings) and their dynamics are handled. Introduce datasets and metrics targeting non-skin components and occlusions.
- Mouth interior and tongue modeling: The method acknowledges limitations but does not propose or validate solutions. Investigate explicit anatomical priors, multi-view mouth supervision, or audio-to-articulator constraints.
- Geometry accuracy metrics: Results emphasize image-space metrics; geometric fidelity is not measured. Evaluate surface/volume accuracy against ground-truth scans (e.g., point-to-surface error, normal consistency).
- Latent space properties: The paper claims a “smooth avatar space” yet offers no quantitative analysis. Measure disentanglement and linearity across identity, expression, and pose via controlled traversals and identity-preservation tests.
- Fitting robustness and scalability: Fitting optimizes only the avatar code; its behavior for varying numbers of observations, noisy inputs, extreme views, and long videos is untested. Study convergence, regularization, and diminishing returns as inputs increase.
- Inference speed and resource footprint: Per-avatar creation time for single-image inference, memory usage, and real-time animation throughput are not reported. Provide latency/throughput benchmarks on commodity GPUs and mobile devices.
- Photometric consistency and view-dependence: 3DGS can produce view-dependent appearance. Assess multi-view color/specular consistency and explore reflectance-aware decoding (e.g., BRDF modeling, radiance-field hybrids).
- Robustness to extreme poses and occlusions: Stress-test on large yaw/pitch, hands-on-face, masks, and heavy occlusions; quantify degradation and identify failure cases.
- Domain and fairness analysis: Generalization across demographics (age, skin tones, genders), diverse capture conditions, and cultural attributes is not measured. Provide stratified performance and fairness audits for internet-scraped datasets.
- Ethical and privacy considerations: Data consent, potential misuse (e.g., identity cloning), and responsible deployment guidelines are not discussed. Establish protocols and safeguards for avatar creation and sharing.
- Token choice at inference: The method always uses the multi-view token at test time; this might be suboptimal for certain in-the-wild inputs. Explore adaptive token selection or multi-token blending based on input diagnostics.
- Expression retargeting limits: Cross-reenactment is evaluated, but anatomical differences (skull/soft tissue) may cause artifacts. Study biomechanically informed constraints to improve retargeting fidelity across identities.
- Hybrid geometry modeling: 3DGS lacks explicit surfaces, affecting collision/jaw articulation. Investigate hybrid Gaussian–mesh/sdf representations to improve physical plausibility and control.
- Ablation coverage gaps: There is no ablation of DINOv2/ViT encoders or perceptual losses (DINO/SAM). Quantify their individual contributions and sensitivities.
- Camera calibration robustness: Evaluate sensitivity to errors in intrinsics/extrinsics and compare against ground-truth cameras; introduce calibration-robust training objectives.
- Synthetic-to-real transfer: Cafca synthetic data is included without quantifying domain-transfer benefits. Measure how synthetic proportion and realism affect performance and explore domain adaptation.
- Training sample efficiency: Training requires ~1M steps over ~3 weeks on an A100; sample efficiency and scaling laws are unstudied. Explore curricula, distillation, parameter-efficient tuning, and smaller model variants.
- Systematic failure taxonomy: Beyond brief limitations, a structured catalog of failure modes (lighting mismatch, occlusion, identity drift, articulation errors) is missing. Provide a diagnostic suite for reproducible failure analysis.
- Reproducibility and release: The paper does not specify code/model release, exact splits, or training recipes necessary to reproduce results. Publish detailed protocols, seeds, and checkpoints to facilitate replication.
Glossary
- 3D Gaussians: A point-based 3D scene representation that models geometry and appearance with Gaussian primitives for fast novel-view rendering. "or 3D Gaussians (3DGS)~\cite{kerbl20233dgs, chu2024gagavatar, he2025lam, guo2025sega}, which allows rendering of novel viewpoints."
- 3D Gaussian Splatting (3DGS): A real-time rendering technique that rasterizes 3D Gaussian primitives to synthesize images. "In practice, we use the tile-based differentiable rasterizer from 3DGS~\cite{kerbl20233dgs} as "
- 3D Morphable Model (3DMM): A parametric face model capturing identity, expression, and shape variations for reconstruction and animation. "3D morphable models (3DMMs) such as FLAME~\cite{Blanz19993dmm, li2017flame}"
- AKD (Average Keypoint Distance): A face-specific evaluation metric measuring average pixel distance between predicted and reference facial landmarks. "Average Keypoint Distance (AKD) measured in pixels with keypoints estimated from PIPNet~\cite{jin2021pipnet}"
- APD (Average Pose Distance): A metric quantifying the difference in estimated head pose between predictions and ground truth via 3DMM parameters. "Finally, we estimate 3DMM coefficients using the forward regressor of~\cite{deng2019deep3dfacerecon} to compute Average Expression Distance (AED) and Average Pose Distance (APD) by computing the L1 distance of the corresponding 3DMM coefficients."
- ArcFace: A deep face recognition model used to compute identity embeddings for evaluating identity preservation. "cosine similarity (CSIM) of identity embeddings based on ArcFace~\cite{deng2019arcface}."
- Autodecoder: A training paradigm where each instance has its own learnable latent code, optimized without an explicit encoder. "These models are typically Autodecoder-based~\cite{park2019deepsdf} and trained on multi-view data."
- Bias sinks: Learnable dataset-level tokens appended to the expression sequence to absorb dataset-specific biases (e.g., monocular vs. multi-view). "we introduce {bias sinks}, which are two learnable tokens and that are concatenated to the expression code sequence before decoding:"
- Bilinear grid sampling: An operation that interpolates features at specified coordinates on a feature map, used to extract per-Gaussian attributes. "This is followed by bilinear grid sampling to extract one feature per Gaussian:"
- Cross-attention: An attention mechanism where queries attend to keys/values from another source to fuse information (e.g., UV queries to image features). "Finally, we perform cross-attention from the UV-anchored queries to the image features :"
- Cross-reenactment: Driving one identity’s image with another person’s expressions and head pose to evaluate generalization across identities. "We evaluate the ability to animate a single image by transferring facial motion and head pose from a driving video showing the same person (self-reenactment) or a different person (cross-reenactment)."
- CSIM (Cosine Similarity): A metric for identity preservation computed as cosine similarity between identity embeddings. "cosine similarity (CSIM) of identity embeddings based on ArcFace~\cite{deng2019arcface}."
- DINOv2: A self-supervised vision transformer used for robust feature extraction and perceptual loss computation. "We begin by first extracting image features with a pre-trained DINOv2~\cite{oquab2023dinov2} model"
- Differentiable rasterizer: A rendering module with gradients enabling end-to-end learning of 3D scene parameters from image losses. "In practice, we use the tile-based differentiable rasterizer from 3DGS~\cite{kerbl20233dgs} as "
- Entanglement (driving signal–viewpoint): A failure mode where expression inputs leak target viewpoint, leading to incomplete 3D reconstructions. "We refer to this failure mode as entanglement of driving signal and target viewpoint."
- FLAME: A 3D morphable face model providing expression codes and geometry used for control and supervision. "In practice, we use the expression codes of FLAME~\cite{li2017flame}."
- FovVideoVDP (JOD): A perceptual video quality metric sensitive to temporal artifacts, reported in Just-Objectionable-Difference units. "Temporal consistency is measured with FovVideoVDP~\cite{mantiuk2021fovvideovdp} (JOD) which is sensitive to flickering, noise and other temporal artifacts."
- GridSample: A grid-based sampling operation that extracts features at specified coordinates from a feature map. "x &= GridSample\left(h_{map}{(L)}, x_{uv}\right)"
- gsplat: A batched implementation for Gaussian splatting used to accelerate training and rendering. "In practice, we use the batched rendering implementation of gsplat~\cite{ye2025gsplat} for better training performance."
- Identity interpolation: Traversing the learned avatar latent space to smoothly blend identities for synthesis and fitting. "our training procedure yields a smooth latent avatar space that facilitates identity interpolation"
- Learned Perceptual Image Patch Similarity (LPIPS): A perceptual image similarity metric used to measure sharpness and visual fidelity. "Learned Perceptual Image Patch Similarity (LPIPS)~\cite{zhang2018lpips}."
- MMDIT: A transformer architecture whose attention implementation is used for efficient cross-attention in this work. "In practice, we use the attention implementation from MMDIT~\cite{esser2024mmdit}."
- NeRF-in-the-wild: A NeRF variant that learns per-image embeddings to model unexplainable factors (e.g., exposure, transient objects). "NeRF-in-the-wild~\cite{martin2021nerfinthewild} learns a per-image embedding that captures aspects of the input that the subsequent generalized NeRF cannot explain."
- Nerfies: A dynamic NeRF method that encodes temporal variations into learnable embeddings for reconstruction. "Similarly, methods like Nerfies~\cite{park2021nerfies} or Cafca~\cite{buehler2024cafca} bake unwanted temporal variations of the input images into learnable embeddings."
- Neural Radiance Fields (NeRFs): A continuous volumetric representation that models view-dependent radiance for photorealistic novel-view synthesis. "Neural Radiance Fields (NeRFs)~\cite{mildenhall2021nerf, li2023hidenerf, li2023goha, chu2024gpavatar, ye2024real3dportrait, deng2024portrait4dv2, tran2024voodooxp}"
- Perceptual losses: Feature-space reconstruction losses leveraging pretrained models to improve visual quality beyond pixel metrics. "Inspired by PercHead~\cite{oroz2025perchead}, we additionally employ perceptual losses based on DINOv2~\cite{oquab2023dinov2} and the Segment Anything Model (SAM)~\cite{ravi2024sam2}:"
- Pixel3DMM: A method for estimating cameras and expression codes by fitting a pixel-wise 3D morphable model. "We extract cameras and expression codes using Pixel3DMM~\cite{giebenhain2025pixel3dmm}."
- PixelShuffle: An efficient upsampling operation that rearranges channels into spatial resolution for decoder feature maps. "uses a combination of PixelShuffle~\cite{shi2016pixelshuffle} and CNN blocks inspired by StyleGAN2~\cite{karras2020stylegan2}:"
- PIPNet: A facial landmark detector used to compute keypoints for AKD evaluation. "Average Keypoint Distance (AKD) measured in pixels with keypoints estimated from PIPNet~\cite{jin2021pipnet}"
- Plucker embeddings: A camera viewpoint encoding based on Plücker coordinates to condition feature extraction. "where are the plucker embeddings of the camera viewpoint of the input image ."
- SAM (Segment Anything Model): A foundation model producing segmentation features used for perceptual supervision. "the Segment Anything Model (SAM)~\cite{ravi2024sam2}"
- Self-reenactment: Reenacting the same identity’s image with its own driving signals to assess fidelity without cross-identity generalization. "We evaluate the ability to animate a single image by transferring facial motion and head pose from a driving video showing the same person (self-reenactment) or a different person (cross-reenactment)."
- Sinusoidal frequencies: A positional encoding technique that maps coordinates to periodic feature vectors for attention queries. "and encoding them with sinusoidal frequencies:"
- SSIM (Structural Similarity Index): An image quality metric capturing luminance, contrast, and structure similarity. "Structural Similarity Index (SSIM)~\cite{wang2004ssim}"
- StyleGAN2: A generative model architecture inspiring the CNN blocks in the upsampler for high-frequency detail synthesis. "CNN blocks inspired by StyleGAN2~\cite{karras2020stylegan2}"
- StyleGAN-PixelShuffle block: The combined upsampling module that fuses PixelShuffle with StyleGAN-style CNN layers. "Architecture of the StyleGAN-PixelShuffle block."
- Transformer: A sequence modeling architecture employing attention, used for both encoding and decoding avatar representations. "we propose a transformer-based 3D portrait animation module with {bias sinks} that explicitly separate the model's behavior on the two dataset types."
- UV space: The 2D parametric domain of a mesh used to anchor and organize latent avatar features. "we employ a head template mesh with corresponding UV space which will host the avatar code's features."
- UV-anchored queries: Query vectors tied to UV positions on a template mesh for cross-attention with image features. "To map the image features into the template's UV space, we define queries anchored in UV space."
Practical Applications
Practical Applications of FlexAvatar
FlexAvatar introduces a single-image pipeline for complete, animatable 3D head avatars, a transformer-based encoder–decoder with a smooth avatar latent space, efficient 3D Gaussian decoding with a StyleGAN-PixelShuffle upsampler, and “bias sinks” (learnable dataset tokens) that resolve viewpoint–expression entanglement when training on mixed monocular and multi-view data. Below are concrete applications derived from these findings.
Immediate Applications
The following use cases can be built with today’s components and the capabilities demonstrated in the paper (minutes-per-avatar creation; single-image/few-shot/monocular support; cross-reenactment; strong generalization with complete 3D heads).
- Boldly deployable telepresence avatars for video calls (software, enterprise collaboration)
- Build a webcam-based teleconferencing mode that replaces the live camera with a FlexAvatar render. Users upload a selfie, get a 3D head avatar in minutes, and drive it with live expression tracking or a driving camera.
- Potential tools/products/workflows: “Avatar Camera” virtual webcam; Teams/Zoom plug-ins; OBS Studio source; a web SDK that takes a selfie, runs encoder + optional 1-minute fitting, and streams 3DGS renders.
- Dependencies/assumptions: Face/expression tracking must provide compatible expression codes (e.g., FLAME-like or mapped); GPU for real-time 3DGS rendering; lighting baked-in may look inconsistent across virtual backgrounds.
- Creator/VTuber pipelines from a selfie (media, entertainment)
- Rapid avatarization for streamers and short-form video, including cross-reenactment from reference performances and scripted expressions.
- Potential tools/products/workflows: Creator apps that ingest a selfie and audio or a reference video; batch render multi-angle shots; export 3DGS assets or rendered sequences.
- Dependencies/assumptions: Audio-to-expression mapping module (if audio-driven) or driver video; hair/occlusion handling depends on training coverage; baked lighting may limit scene changes.
- Game onboarding: instant head avatars from a single selfie (gaming)
- Convert a player’s selfie to an animatable head for cutscenes or social spaces; few-shot fitting improves identity in ~7 minutes.
- Potential tools/products/workflows: Unity/Unreal plug-ins to load 3DGS avatars; light retargeting layer for in-engine face controllers; optional avatar latent fitting during first launch.
- Dependencies/assumptions: 3DGS runtime integration or conversion to game-friendly formats; expression retargeting if the game uses predefined blendshapes; current method is 3DMM-free (no direct rig export).
- Customer support agents and sales reps as digital humans (enterprise CX)
- Generate customer-specific or brand personas that preserve identity while maintaining expressive, view-consistent animation.
- Potential tools/products/workflows: CRM integration to produce a representative’s avatar from a headshot; scripted animation library (greetings, empathy cues) driven via expression codes; web rendering of 3DGS.
- Dependencies/assumptions: Consent and governance for employee/customer likeness; lighting realism may need post-processing.
- Education: virtual lecturers and tutors from minimal media (education)
- Produce lecturer avatars from a profile photo and animate with course audio or pre-recorded expressions for consistent multi-view lecture content.
- Potential tools/products/workflows: LMS plug-ins to generate lecture videos with multi-camera angles; cross-reenactment to align facial articulations to audio segments.
- Dependencies/assumptions: Audio-to-expression mapper; accessibility compliance (captions, lip-sync quality).
- E-commerce try-on for head-worn items (retail)
- Use complete 3D heads to simulate glasses, hats, headphones with multi-view consistency.
- Potential tools/products/workflows: “Try-on” widgets that place products on the avatar and render multiple angles; head-shape measurement from avatar code for size recommendations.
- Dependencies/assumptions: Accurate ear/temple geometry and hair handling depend on training diversity; relighting support desirable for product realism.
- Privacy-preserving identity pseudonymization via latent interpolation (privacy/compliance)
- Interpolate in the smooth avatar latent space to produce a consistent pseudonymous avatar that preserves expressions but hides identity.
- Potential tools/products/workflows: Data collection apps that convert faces to pseudonymous avatars for research or internal review; configurable identity distance controls.
- Dependencies/assumptions: Requires policy alignment; interpolation must be validated to sufficiently reduce re-identification risk.
- Rapid 3D dataset bootstrapping from monocular videos (R&D, academia)
- Convert existing 2D/monocular archives to complete, animatable 3D head assets for training downstream models (e.g., synthesis, tracking, lip-reading).
- Potential tools/products/workflows: Batch avatarization farm using FlexAvatar + bias sinks; automate camera/expression extraction (Pixel3DMM).
- Dependencies/assumptions: Quality depends on tracker accuracy and diversity of expressions; ensure licensing for source media.
- Mixed-dataset training with “bias sinks” to correct entanglement (ML platform/academia)
- Apply dataset-level tokens to absorb modality biases (monocular vs. multi-view), enabling unified training without sacrificing 3D completeness.
- Potential tools/products/workflows: PyTorch modules for dataset tokens; training recipes for other domains (e.g., multi-dataset pose/body reconstruction).
- Dependencies/assumptions: At least some multi-view supervision remains necessary; token usage must be carefully enforced only at training and selected at inference.
- Video post-production: quick head doubles (media, VFX)
- Create 3D head doubles from limited stills for pickups, ADR, or alternate angles in editing.
- Potential tools/products/workflows: On-set capture from a single frame; few-shot fitting; render matching camera intrinsics for scene composites.
- Dependencies/assumptions: Lighting baked-in; match-move and relighting may be required; hair fidelity depends on training data.
- Daily-use social avatars and AR filters (consumer apps)
- Build personalized avatars for chat, stickers, and AR masks that preserve user expressions and identity with multi-view consistency.
- Potential tools/products/workflows: Mobile app that makes a 3D head from one portrait; simple pose/expression controls; export to messaging platforms as short videos or 3D objects.
- Dependencies/assumptions: On-device or edge GPU acceleration for responsiveness; safety controls to prevent impersonation.
- Benchmarking and evaluation augmentation (academia)
- Use FlexAvatar metrics and fitting workflow to test robustness across single-image, few-shot, monocular regimes and novel-view consistency.
- Potential tools/products/workflows: Reproducible evaluation scripts combining PSNR/SSIM/LPIPS with face metrics (AKD, CSIM) and temporal JOD.
- Dependencies/assumptions: Comparable trackers (Pixel3DMM) and consistent preprocessing across methods.
- Immediate governance steps: labeling and consent workflows (policy, compliance)
- Introduce content labeling (“virtual avatar” badges) and consent capture when generating someone’s avatar from a photo.
- Potential tools/products/workflows: Watermarking of rendered frames; audit logs tying avatars to consent records; opt-out mechanisms.
- Dependencies/assumptions: Organizational policy support; user interfaces for consent and disclosure; watermark robustness not guaranteed against aggressive post-processing.
Long-Term Applications
These use cases benefit from FlexAvatar’s core ideas but require further research, productization, or ecosystem support (e.g., relighting, full-body modeling, regulatory standards).
- Relightable, environment-aware telepresence (software, XR)
- Integrate explicit lighting models so avatars adapt to virtual scenes and dynamic illumination.
- Potential tools/products/workflows: Neural relighting head module; environment map estimation from the user’s room; XR runtime integration (Vision Pro, Quest).
- Dependencies/assumptions: New training with lighting disentanglement; face–hair–skin BRDF modeling; mobile inference optimization.
- Full-body digital humans from sparse inputs (software, robotics, XR)
- Extend the encoder–decoder and bias sinks paradigm from heads to full bodies for telepresence, teleoperation, and embodied AI.
- Potential tools/products/workflows: Unified body UV latent space; body expression drivers; robotics HRI avatars; VR socials with full-body animation.
- Dependencies/assumptions: Multi-view body datasets still scarce; motion retargeting and clothing dynamics; compute and latency budgets.
- Healthcare diagnostics and therapy tooling (healthcare)
- Quantify facial asymmetry, pain, or recovery using consistent 3D reconstructions; support speech therapy via accurate articulation visualization.
- Potential tools/products/workflows: Clinical dashboards that track 3D expression biomarkers longitudinally; telemedicine avatarization for patient comfort.
- Dependencies/assumptions: Clinical validation and regulation (e.g., FDA/CE); demographic fairness audits; secure handling of biometric data.
- Secure identity verification and anti-impersonation (finance, platform integrity)
- Use avatar-based liveness and passive reconstruction signals as part of KYC or account protection, plus watermarks to deter deepfake abuse.
- Potential tools/products/workflows: Passive 3D reconstruction as a second factor; cross-check avatar–camera consistency; cryptographic render provenance (e.g., C2PA extensions).
- Dependencies/assumptions: Strong attack models; adversarial robustness; privacy-preserving protocols; regulatory alignment.
- Standards for dataset-level bias control in multi-source training (policy, ML governance)
- Codify techniques like bias sinks into best practices for training across disparate datasets (modality, domain, or demographic imbalances).
- Potential tools/products/workflows: Open specifications for dataset-token interfaces; auditing tools that measure entanglement and leakage across sources.
- Dependencies/assumptions: Community buy-in; reproducible auditing; legal clarity on cross-dataset use.
- Cross-modal drivers and expressive control (media, accessibility)
- Train with richer drivers (audio, EMG, text prompts) to control expressions and emotional nuance beyond FLAME coefficients.
- Potential tools/products/workflows: Universal expression encoders; text-to-expression prompts for directing performances; accessibility interfaces for users with limited mobility.
- Dependencies/assumptions: Large-scale paired data; careful control of style vs. identity; latency and stability in live scenarios.
- Cultural heritage and archival reconstruction (museums, education)
- Reconstruct 3D heads from limited historical photos for interactive exhibits, with controlled expressions and multiple viewpoints.
- Potential tools/products/workflows: Archive ingestion pipelines; curator tools to constrain plausible expressions; exhibit-ready rendering systems.
- Dependencies/assumptions: Ethical guidelines, provenance, and consent where applicable; photo quality variability; artistic vs. scientific fidelity balance.
- Synthetic data engines for 3D perception (autonomy, AR, vision)
- Use avatar latent sampling and interpolation to generate diverse, labeled 3D head datasets for training detectors, trackers, and reenactment systems.
- Potential tools/products/workflows: Parameterized identity generation; domain randomization (hair, accessories, lighting) once relighting is available.
- Dependencies/assumptions: Coverage gaps (e.g., hair, occlusions) addressed; licensing for any real-identity baselines; validation of synthetic-to-real transfer.
- On-device, private avatarization (mobile, edge computing)
- Run encoder and minimal fitting on-device to avoid server-side processing of biometric data.
- Potential tools/products/workflows: Distilled lightweight models; mixed-precision 3DGS rendering on mobile GPUs; private expression tracking.
- Dependencies/assumptions: Significant model compression; energy constraints; OS-level privacy frameworks.
- Regulatory frameworks for ethical avatarization (policy)
- Develop guidance and rules for consent, data retention, watermarking, provenance, and redress related to avatar creation and use.
- Potential tools/products/workflows: Compliance SDKs that enforce disclosure/watermarking; dynamic risk scoring (e.g., when cross-reenacting others).
- Dependencies/assumptions: Multi-stakeholder standards; international coordination; impact assessments on bias and misuse.
Notes on feasibility across applications:
- FlexAvatar currently bakes lighting; relighting is a key dependency for many production uses.
- Expression drivers are model-agnostic, but operational pipelines need a reliable source (FLAME-compatible tracker, audio-to-expression model, or learned general expression encoders).
- Bias sinks require at least some multi-view supervision during training; synthetic multi-view can help close coverage gaps.
- Real-time deployment assumes GPU support for 3D Gaussian Splatting; mobile/XR requires further optimization.
- Ethical, legal, and reputational risks (impersonation, deepfake misuse) necessitate watermarking, consent, and provenance measures in any user-facing product.
Collections
Sign up for free to add this paper to one or more collections.

