- The paper demonstrates that decomposing the translation process into distinct stages leads to statistically significant improvements in quality over zero-shot methods.
- It introduces a multi-turn framework where LLMs perform pre-translation research, drafting, refinement, and proofreading, mimicking human translation practices.
- Empirical evaluations on WMT datasets using MetricX-23 confirm that the step-by-step method consistently outperforms traditional monolithic translation approaches.
Step-by-Step Translation Methodology for Long-Form Texts
The paper "Translating Step-by-Step: Decomposing the Translation Process for Improved Translation Quality of Long-Form Texts" presents a novel framework that decomposes the machine translation task into a process more aligned with human translation methodologies. This approach involves LLMs in a multi-turn interaction to perform sub-tasks such as pre-translation research, drafting, refining, and proofreading. By observing this structured method, the study has shown a significant improvement in translation quality over traditional zero-shot translation techniques.
Step-by-Step Framework
The core proposition of the paper is a shift from viewing translation as a monolithic task to a decomposed, iterative process. This model is influenced by the "chain-of-thought" paradigm which requires LLMs to break down complex tasks into simpler sub-tasks to derive final results.
Pre-Translation Research
This initial phase focuses on understanding the context and challenges of the source text. The model identifies idiomatic expressions and figurative usage, aiming to align more closely with human translators' preparation processes.
Drafting
During this stage, the LLM is tasked with generating an initial translation draft that emphasizes faithfulness to the source text. The focus is on capturing the text's meaning accurately without yet focusing on fluency.
Refinement
The third phase involves improving the fluency of the draft translation. This editing process enhances readability and clarity without deviating from the source's intended meaning, making the translation smoother and more natural.
Proofreading
The final stage, proofreading, ensures grammatical correctness and stylistic appropriateness, offering a polished translation. In practice, this mirrors the standard human proofreading step after the culmination of an editorial process.
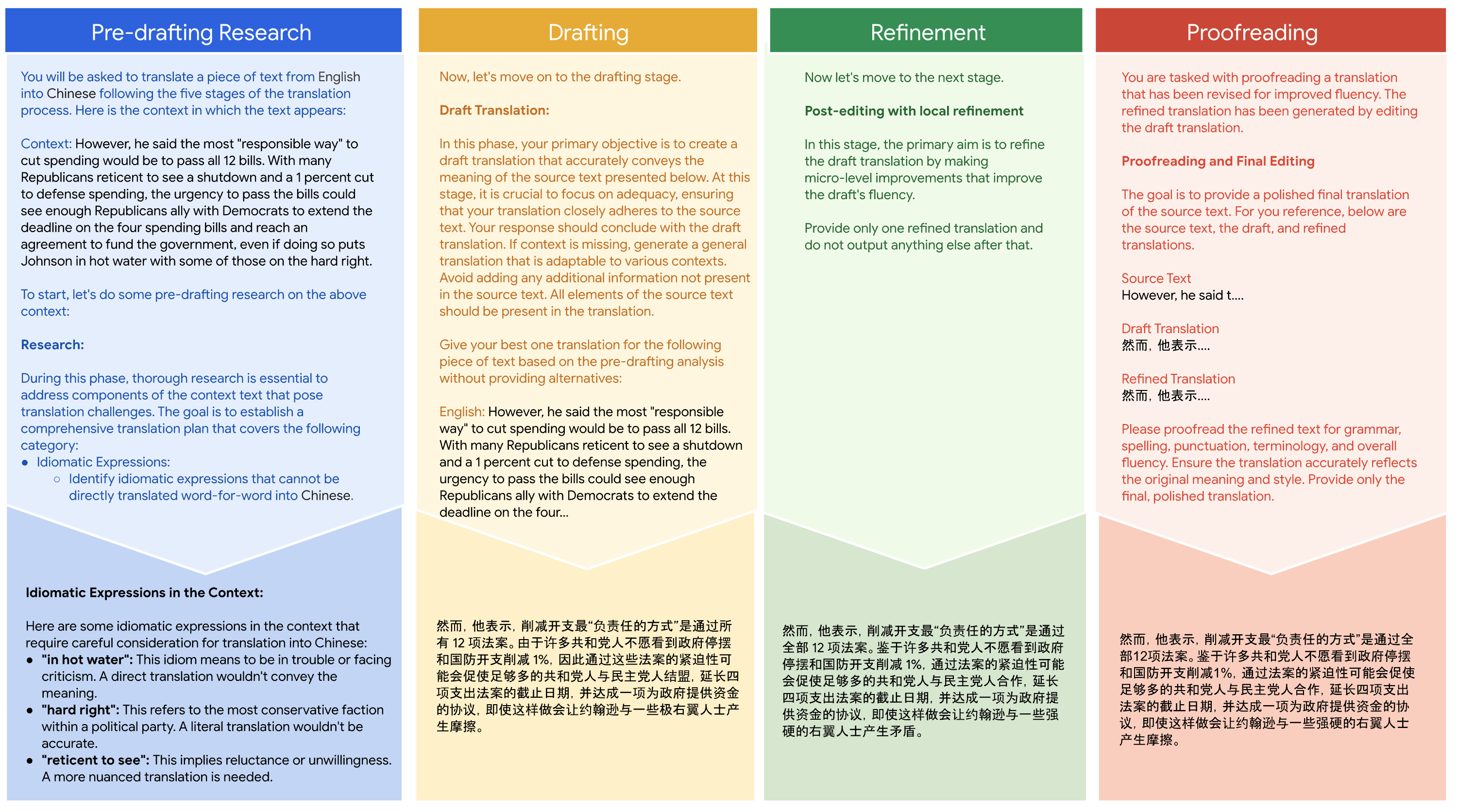
Figure 1: Translate Step-by-Step prompting framework. User prompts (top) and Gemini's responses (bottom) for the translation of an English document into Chinese.
Empirical Evaluations
The framework is evaluated on datasets from the WMT 2023 and WMT 2024 translation tasks, using the Gemini 1.5 Pro model. The automatic evaluation uses MetricX-23, which measures translation quality comprehensively, leveraging both reference-based and quality estimation metrics.
Results and Comparisons
The evaluation results indicate a systematic improvement in translation quality when using the step-by-step method compared to zero-shot translations. The improvements are statistically significant across several languages, supporting the assertion that a decomposed approach leads to better translation quality for long-form texts (Figure 2).
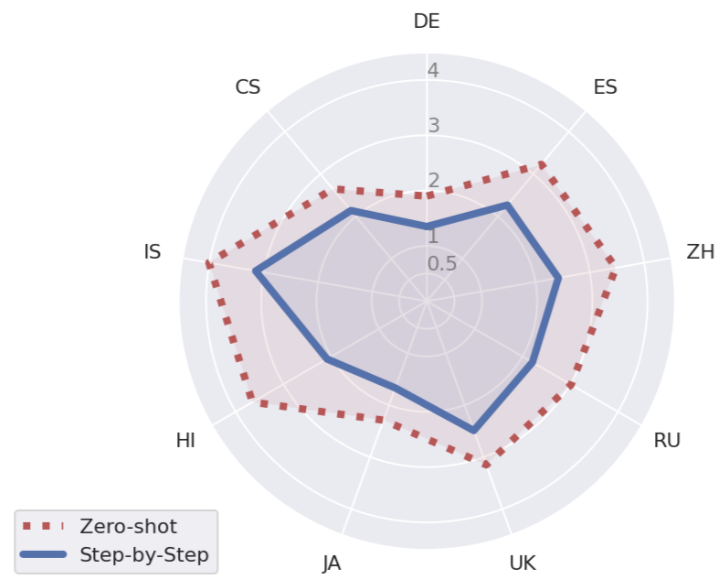
Figure 2: MetricX-23 quality improvements (where lower scores indicate better translation quality) on document-level translation on the wmt24 test set. Translate step-by-step with Gemini 1.5 Pro consistently outperforms zero-shot translation.
Furthermore, the step-by-step framework was tested against established approaches leveraging non-parametric knowledge for translation selection. In these comparisons, step-by-step consistently delivered superior results without relying on external resources, underscoring the efficacy of parametric models in translation tasks.
Implications and Future Directions
The implications of this research include refining machine translation systems and enhancing their applicability to contexts requiring high-quality outputs, such as literary and technical document translations. The step-by-step method redefines the expectations of LLM-driven translations, showing the potential for machine systems to achieve results reminiscent of human translation quality.
Looking forward, this approach could herald a new paradigm in translation studies, focusing on modular, iterative processes. Future research could explore further optimizations within translation sub-tasks or the adaptation of this framework to other LLMs beyond Gemini, assessing its adaptability and scalability.
Conclusion
This paper demonstrates that adapting the translation task to mimic more complex, human-like processes can significantly improve translation quality, particularly for long-form texts. The step-by-step methodology provides a structured approach that bridges the gap between current LLM capabilities and the nuanced execution required for superior translation outputs, presenting a compelling case for the decomposition of tasks across various NLP applications.

