- The paper introduces a novel incremental decoding framework that preserves context and style in discourse-level literary translations.
- It integrates a Three-Stages Translation Pipeline with continual pre-training, interlinear text formatting, and supervised fine-tuning using the LoRA method.
- Experimental results show significant BLEU score improvements, validating the framework’s effectiveness in handling complex literary texts.
Context-aware and Style-related Incremental Decoding Framework for Discourse-Level Literary Translation
Introduction
This paper presents an advanced methodology for discourse-level literary translation, addressing the intricate challenges inherent in translating nuanced literary texts. This complexity arises from the subtle meanings, idiomatic expressions, and complex narrative structures of literary works. The proposed solution leverages the strengths of the Chinese-Llama2 model, augmented through Continual Pre-training (CPT) and Supervised Fine-Tuning (SFT). Central to this approach is an Incremental Decoding framework, which emphasizes context and style preservation, enhancing both sentence-level and document-level translation fidelity.
The primary objective is to ensure that translations not only uphold linguistic accuracy but also maintain the literary quality of the original text. The paper reports significant enhancements in BLEU scores, demonstrating the framework's capacity to handle the complexities of literary translation effectively.
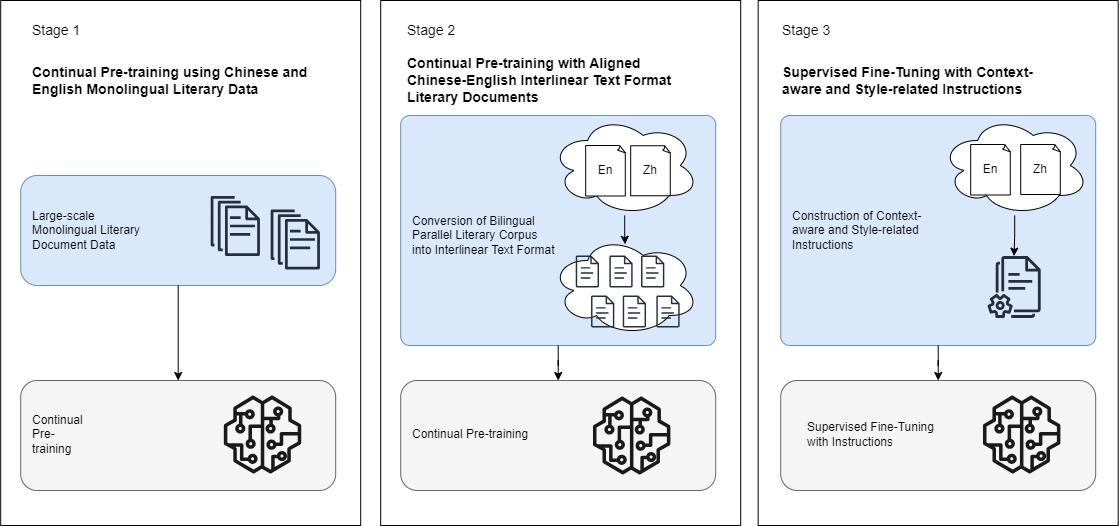
Figure 1: The overall of our approach.
Background
Machine Translation (MT) systems have traditionally relied on encoder-decoder architectures, necessitating large bilingual datasets and augmentation techniques. The advent of LLMs such as GPT has revolutionized MT by enabling translation capabilities through few-shot learning paradigms. This paper expands on these capabilities by introducing the Three-Stages Translation Pipeline (TP3) paradigm. This includes:
- Continual Pre-training with Extensive Monolingual Data: Expanding the multilingual capacities of LLMs.
- Continual Pre-training with Interlinear Text Format: Enhancing synthetic and semantic cross-lingual mappings.
- Supervised Fine-Tuning with Source-Consistent Instruction: Focusing on alignment between source language and translations.
By embedding these stages within the framework, the research aims to refine LLMs for the nuances of literary text translations.
Methodology
The paper details a systematic approach to literary translation using the TP3 paradigm, integrated with an Incremental Decoding framework.
Stage 1: Continual Pre-training
Initial pre-training focuses on utilizing comprehensive monolingual literary data in Chinese and English. This strategy adapts existing LLMs, such as Llama, to handle literary contexts more effectively. For instance, the training process treats entire novels as singular training units, incorporating contextual information crucial for handling long-range dependencies effectively.
Stage 2 introduces cross-lingual alignment through Chinese-English interlinear text formats. This step is vital for enabling the model to comprehend the syntactic and semantic parallels necessary for high-quality translations. Here, the LoRA technique facilitates an efficient and computationally feasible pre-training process.
Stage 3: Context-aware and Style-related Fine-Tuning
The final training phase involves supervised fine-tuning with specific instructions designed to maintain narrative flow and stylistic integrity. The LoRA method is leveraged again to adapt the model specifically for preserving literary style and contextual consistency.
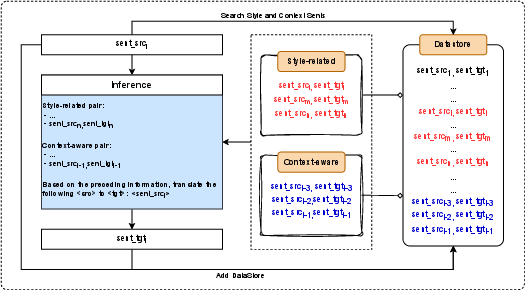
Figure 2: The overall of our incremental decoding framework.
Results
Empirical results showcase considerable improvements with the proposed methodology. Incorporating TP3 pre-training and context-aware instructions robustly enhances translation metrics—BLEU scores reflect this. Various test sets showed that both sentence-level and document-level scores improved significantly. These results underscore the framework's capability to deliver not only accurate translations but also ones that preserve the style and coherence of the original literary texts. The experiments were conducted using optimized setups involving DeepSpeed on multi-GPU environments to efficiently handle vast datasets and complex model architecture.
Conclusion
The proposed method demonstrates a significant stride forward in the field of literary translation, particularly in addressing the nuanced requirements of discourse-level translation in the Chinese-English language pair. By applying advanced techniques like TP3, Continual Pre-training, and Incremental Decoding frameworks, researchers can achieve more coherent and stylistically accurate translations. This work serves as a foundation for future developments in literary translation, suggesting further exploration into scaling and adapting similar frameworks for other language pairs and literary genres.

