- The paper introduces FastTextSpotter, a framework that integrates a Swin Transformer backbone, dual-decoder Transformer, and SAC2 attention to boost multilingual scene text spotting efficiency.
- It employs a dynamic query formulation and reference point sampling strategy to precisely detect and recognize text across various orientations and languages.
- Experimental results on ICDAR2015, TotalText, CTW1500, and VinText show superior accuracy and recall compared to existing state-of-the-art models.
FastTextSpotter: A High-Efficiency Transformer for Multilingual Scene Text Spotting
The paper presents FastTextSpotter, a novel framework geared towards efficient multilingual scene text spotting, leveraging advanced transformer architectures to enhance processing speed without sacrificing accuracy. This work integrates a Swin Transformer visual backbone with a Transformer Encoder-Decoder setup, enriched by the SAC2 attention module to bolster both speed and adaptability.
Introduction
Scene text spotting entails the localization and recognition of text within natural scenes, often presenting challenges due to diverse orientations, languages, and annotation styles. Existing state-of-the-art models have significantly bolstered text detection capabilities using CNNs and Transformers, yet struggle to balance precision with processing efficiency, particularly in time-sensitive environments. The novel FastTextSpotter framework, detailed in this paper, aims to address these challenges, demonstrating improved scene text detection and recognition across varied datasets.
FastTextSpotter is built upon a flexible architecture, incorporating the Swin Transformer framework along with a double-decoder Transformer setup. Swin Transformer offers robust feature extraction capabilities crucial for recognizing text in arbitrary shapes, optimized by the SAC2 attention module - a faster self-attention unit. This specialized module is pivotal in accelerating processing speeds, making FastTextSpotter conducive for real-world applications requiring multilingual text spotting.
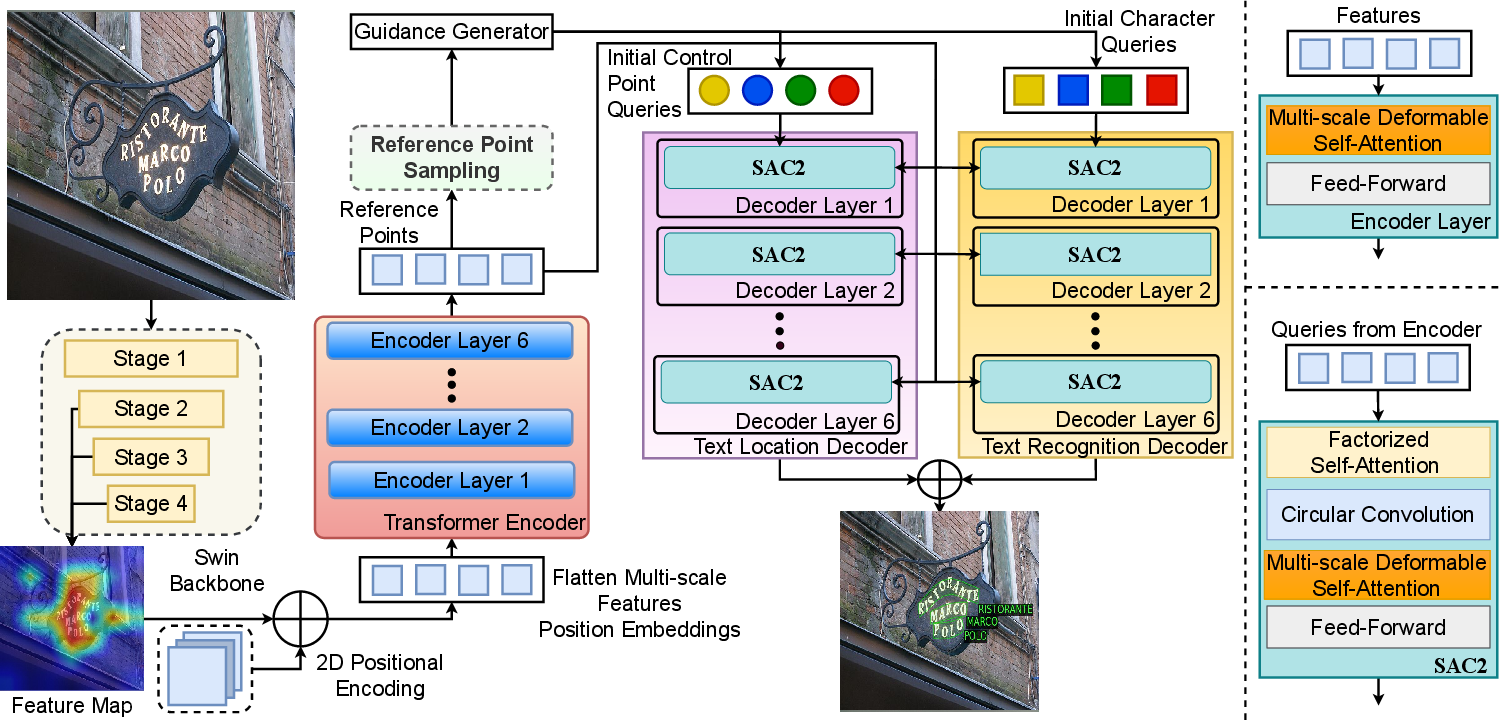
Figure 1: Overview of FastTextSpotter illustrating a Swin Transformer visual backbone with a Transformer Encoder-Decoder framework. Key features include the SAC2 attention module, dual decoders for accurate text localization and recognition, and the Reference Point Sampling system for effective text detection across various shapes and languages.
Methodology
Model Architecture
FastTextSpotter’s architecture centers around a Swin Transformer backbone, ensuring efficient visual feature extraction. Following this, a dual-decoder Transformer setup addresses text detection and recognition simultaneously, managing the complex localization of text regions across varying orientations and shapes. This setup is essential for maintaining accuracy while reducing computational demands.
SAC2 Attention Module
The SAC2 attention module represents a pivotal enhancement, facilitating faster training and model convergence. Its integration of circular convolution techniques into self-attention mechanisms ensures robust handling of spherical shapes, refining text spotting precision.
A dynamic point update strategy, coupled with advanced reference point sampling, underscores the system’s efficiency. By systematically resampling points and refining positional queries through anchored boxes, FastTextSpotter ensures precise text detection within scenes, enhancing both learning and inference.
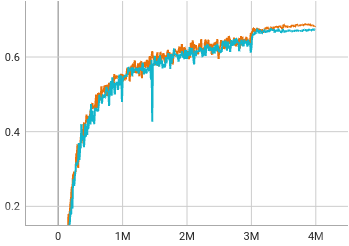
Figure 2: Trade-off between text spotting performance h-mean vs number of training iterations: The blue curve indicates the model without the SAC2 attention module while the orange curve depicts the model performance with our proposed SAC2 module.
Experimental Results
FastTextSpotter demonstrates notable improvements across benchmark datasets, including ICDAR2015, TotalText, CTW1500, and VinText. Compared to prior models, FastTextSpotter achieves superior accuracy in end-to-end recognition tasks on these benchmarks, particularly outperforming competitors in recall metrics.








Figure 3: Some illustration of our method on different datasets. Zoom in for better visualization. First two images from Total-Text, third and fourth images from CTW1500, fifth and sixth images from ICDAR15, and the last two images from Vintext.
When compared with state-of-the-art text spotting models, FastTextSpotter shows the best performance in detection precision and efficiency metrics. Its advantage lies in the use of optimized attention mechanisms and dynamic query adjustments, substantially accelerating processing speeds while maintaining high detection accuracy across complex language scenarios.
Conclusion
FastTextSpotter establishes itself as a robust and efficient solution for multilingual scene text spotting, accentuating its operational efficiency and accuracy improvements over existing models. The framework's versatility across diverse linguistic contexts, combined with its enhanced processing speed, presents significant applications for real-world OCR tasks. Future work envisages the extension of FastTextSpotter's capabilities to encompass a wider array of languages and script complexities, further exemplifying its utility in global text spotting applications.

