- The paper introduces a lightweight, context-free framework that reduces computational overhead by using simple convolutions and streamlined post-processing.
- It employs an innovative linear point-wise decoder for character recognition, achieving up to 25 FPS on GPUs while maintaining high accuracy.
- The approach is optimized for mobile deployment, demonstrating less than 100ms processing time on an iPhone 11 Pro for real-time text spotting.
Context-Free TextSpotter for Real-Time and Mobile End-to-End Text Detection and Recognition
Introduction
The presented work introduces Context-Free TextSpotter, an innovative framework for scene-text recognition designed with mobile and real-time applications in mind. Unlike traditional End-to-End (E2E) text spotting methods, which depend on complex and computationally intensive components such as feature extractors and sequence modeling, Context-Free TextSpotter incorporates simple convolutions and streamlined post-processing operations. This design choice aims to reduce computational overhead, making it suitable for deployment on devices with limited resources, such as smartphones.
System Architecture
The Context-Free TextSpotter is engineered around three key components:
- Feature Extraction: Utilizing a lightweight U-Net architecture built on CSP-PeleeNet, the system efficiently extracts features without compromising on performance scalability.
- Character and Text-Box Detection: This component leverages heat-map based techniques inspired by CRAFT, employing region and affinity maps to localize character positions and text boxes.
- Character Decoding: The innovative linear point-wise decoder performs classification of character points, offering a space and time-efficient alternative to semantic-segmentation-based methods.
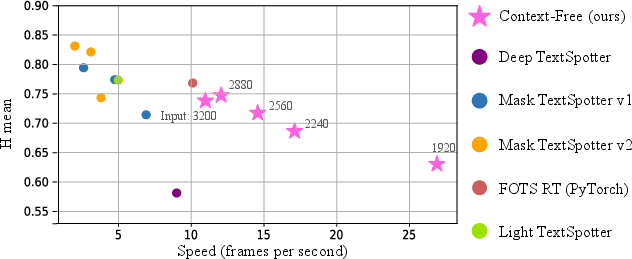
Figure 1: Recognition quality vs. speed in scene text spotters, evaluated with a GPU.
Methodology
Text-Box and Character Detection
The method adopts segment-based character and text-box detection using region and affinity maps, facilitating the localization of connected text components. This choice supports the minimalistic design as it allows character spotting without complex geometric transformations.

Figure 2: Differing characteristics of small and large texts affect labeling-based and peak-detection-based approaches differently.
Character Decoder
The linear point-wise decoder extracts feature vectors at detected character points, applying a linear transformation to classify these points. This approach consumes significantly less memory and computation, especially beneficial when recognizing large character sets like Latin or Chinese scripts.
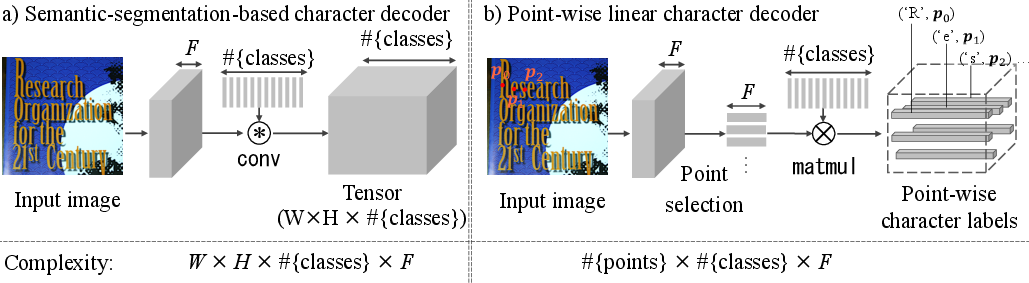
Figure 3: Comparison between semantic-segmentation-based character decoding and our linear point-wise decoding.
Experimental Evaluations
Evaluations on datasets such as ICDAR2013 and ICDAR2015 confirm that Context-Free TextSpotter outperforms existing models in terms of inference speed and parameter efficiency, achieving up to 25 FPS on GPUs with high accuracy levels for text spotting tasks.

Figure 4: Text spotting results with Context-Free TextSpotter.
Mobile Deployment Considerations
Testing performed on an iPhone 11 Pro demonstrates that the model maintains adequate performance on mobile hardware. The model achieves less than 100ms processing time using the Neural Engine, highlighting its suitability for real-time mobile applications.
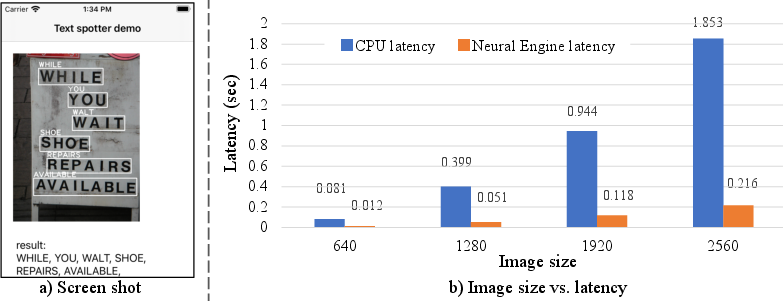
Figure 5: On-device Benchmarking with iPhone 11 Pro.
Conclusion
The Context-Free TextSpotter represents a significant step forward in enabling efficient and scalable scene-text recognition on mobile platforms. By foregoing the complexities of traditional methods and focusing on a streamlined convolutional approach, it provides a practical solution for real-time text detection and recognition applications on resource-constrained devices. Future developments may explore enhancements in language modeling and lexicon integration to further improve accuracy and robustness across differing script systems.