- The paper introduces a unified transformer-based framework that synergizes text detection and recognition without relying on character-level annotations.
- It employs a dilated Swin-Transformer backbone and a Recognition Conversion module to enhance feature extraction and suppress background noise.
- Experimental results on datasets like ICDAR 2015 and Total-Text demonstrate enhanced robustness and state-of-the-art performance.
SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text Recognition
Introduction
SwinTextSpotter addresses the limitations of state-of-the-art scene text spotting methods by enhancing the synergy between text detection and recognition. Traditional approaches often treat these tasks separately, leading to inefficiencies and error accumulations. Instead, SwinTextSpotter uses a transformer-based approach to unify detection and recognition tasks, achieving better performance without relying on additional modules such as character-level annotations.
SwinTextSpotter's framework consists of a four-component architecture:
- Backbone: Utilizes Swin-Transformer with a Feature Pyramid Network (FPN) to extract multi-scale features.
- Query-based Text Detector: Develops a set-prediction problem using a sequence of proposal features and boxes for efficient text localization.
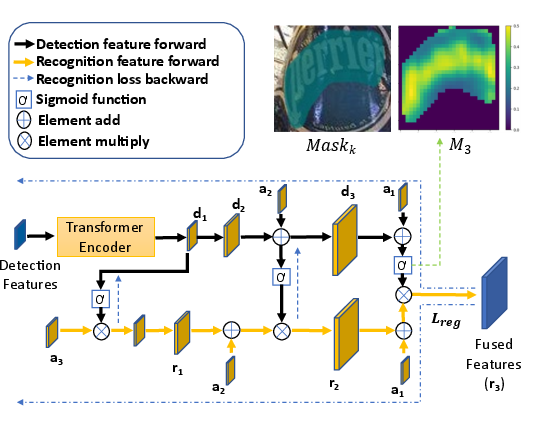
- Recognition Conversion (RC) Module: Bridges text detection and recognition by injecting detection features into the recognition stage.
- Attention-based Recognizer: Implements a two-level self-attention mechanism to improve sequence modeling.

Figure 1: The framework of the proposed SwinTextSpotter. The gray arrows denote the feature extraction from images. The green arrows and orange arrows represent the detection and recognition stages, respectively.
Key Components and Methodologies
The backbone features a Dilated Swin-Transformer that incorporates dilated convolutions for larger receptive fields, enabling better handling of dense and arbitrarily shaped text instances.
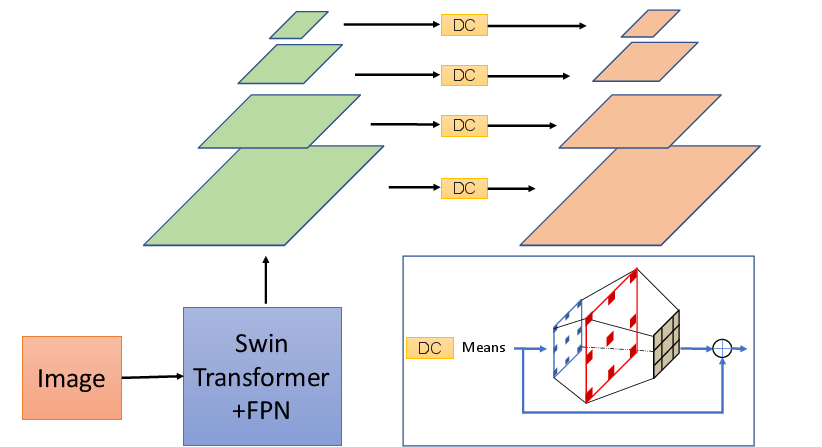
Figure 2: Illustration of the designed Dilated Swin-Transformer. The DC refers to two dilated convolution layers, a vanilla convolution layer, and a residual structure.
Recognition Conversion
The RC module plays a pivotal role by:
Query-based Detection
Leveraging the Transformer encoder with a dynamic head, the detection head processes proposal features through multiple stages of refinement, enhancing robustness across scales and aspect ratios.
Experimental Evaluations
SwinTextSpotter demonstrated its effectiveness across various datasets:
- ICDAR 2015 & RoIC13: Achieved superior F-measure for strong lexicon tasks and robustness against rotation.
- ReCTS & VinText: Showed significant gains in multilingual text spotting without character-level annotations.
- Total-Text & SCUT-CTW1500: Outperformed existing methods in both detection and spotting tasks, although challenges remain for long, arbitrarily-shaped text.
Limitations and Future Work
Despite its successes, SwinTextSpotter exhibits limitations with long, arbitrary text instances, particularly noted in SCUT-CTW1500. Future work could explore improving feature extraction resolution to address recognition mismatches for complex text shapes.
Conclusion
SwinTextSpotter advances the field of scene text spotting by harnessing the power of Transformer networks and Recognition Conversion to synergize text detection and recognition tasks. This unified approach not only simplifies the framework by eliminating the need for rectification modules but also sets new benchmarks across multiple public datasets, showcasing the potential of integrated text spotting systems.