- The paper demonstrates that while FP8 can potentially double throughput, it introduces significant training instabilities, with about 10% divergence under default conditions.
- It introduces a novel loss landscape sharpness metric focused on output logits, which aids in predicting divergence risks more effectively than traditional input-space methods.
- The study reveals that even minor reductions in exponent bits can lead to complete training breakdowns, underscoring the need for dynamic precision tuning and hyperparameter adjustments.
Quantifying Reduced Precision Effects on LLM Training Stability: An Expert Examination
Introduction
The exponential rise in computational demands for training LLMs has driven the exploration of reduced-precision floating-point representations to enhance training efficiency. The study "To FP8 and Back Again: Quantifying Reduced Precision Effects on LLM Training Stability" offers a critical investigation into the stability of training LLMs using such reduced-precision formats, specifically FP8. In contrast with BF16, which is currently favored for LLM training due to its balance between precision and hardware compatibility, FP8 introduces challenges due to its further reduction in bit-depth.
Floating-Point Precision Reduction
The motivation to employ reduced-precision such as FP8 stems from its potential to double computational throughput, hence significantly reducing training time and resource consumption. However, prior experiences with FP16 demonstrate that lower precision can lead to training instabilities. The paper critically assesses whether FP8's reduced bit depth can be a feasible and economical alternative for LLM training, given its implications on training stability.
Training Instabilities and Their Implications
The paper reports instability in LLM training using reduced-precision even with standard mixed-precision BF16, which occasionally leads to convergence issues in approximately 10% of training runs under default conditions (Figure 1). The authors emphasize the importance of verifying training robustness across various conditions, including random seed variations and hyperparameter sensitivities.
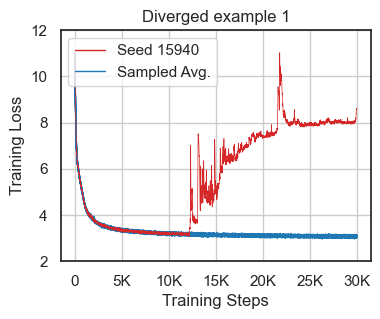
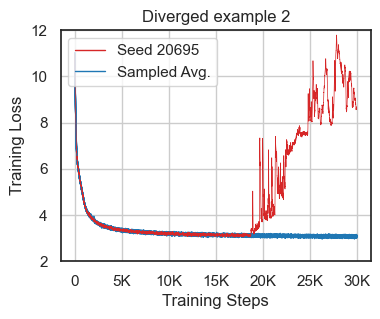
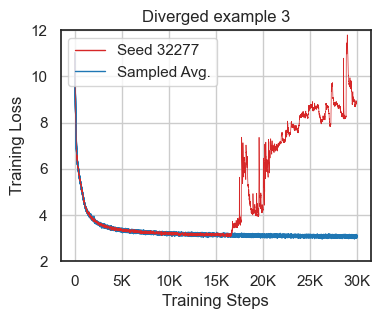
Figure 1: Loss divergence cases using the default nanoGPT configurations showcasing the challenge of instability in BF16 training.
Loss Landscape Analysis
A novel metric for loss landscape sharpness is introduced to quantify training instabilities and predict divergences. The authors propose focusing on the output logit space instead of the input space, which enhances the efficiency of determining the instability risks posed by reduced bit representations.
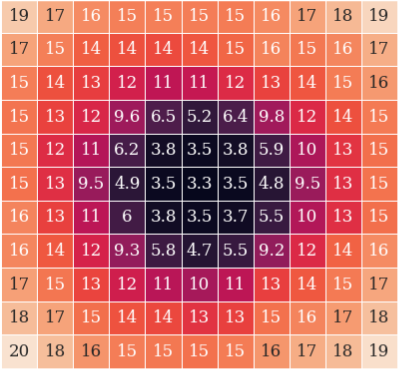
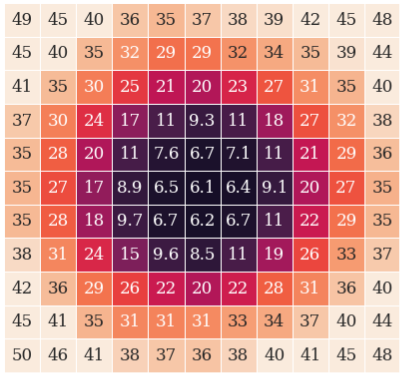
Figure 2: Loss landscape diagrams for Llama 120M E8M3 illustrating landscape characteristics at different stages of training.
Precision Implementation Techniques
The paper details an approach to emulate reduced-precision FP8 training. By clamping exponent and mantissa bits dynamically via masking during run time, the research simulates the implications of FP8 without hardware-native support. This technique highlights the architectural sensitivity to bit reductions, particularly the greater influence of exponent bits in maintaining training stability.
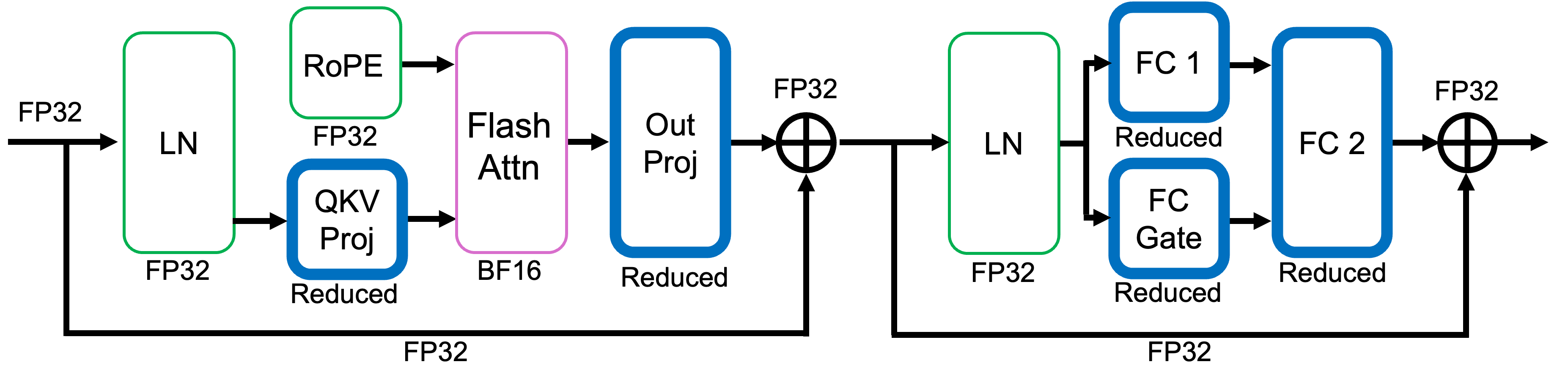
Figure 3: Precision usage diagram in a Llama decoder block illustrating the combination of high-precision and reduced-precision operations.
Experimental Results
The experiments demonstrate significant instability in models operating on reduced-precision, notably with a single bit reduction in exponent representation leading to complete training breakdowns (Figure 4). Furthermore, the experiments verify that limited adjustments in learning rate greatly affect the robustness of E8M5 configurations, even though they do not produce outright divergence (Figure 5).
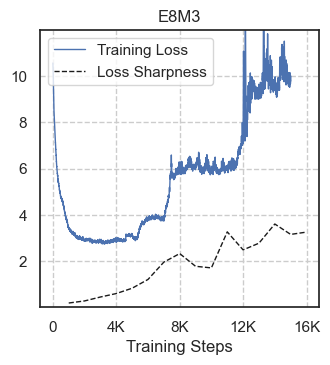
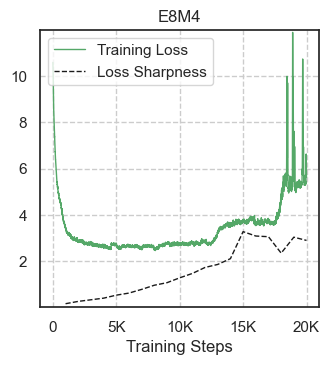
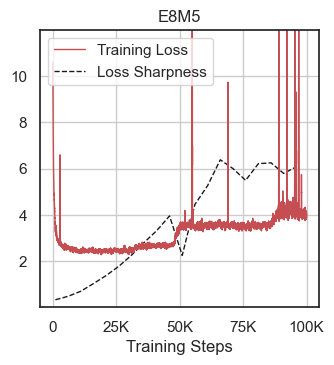
Figure 4: Simulated reduced-precision models trained to the point of loss divergence.
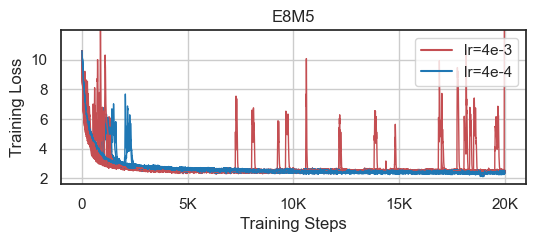
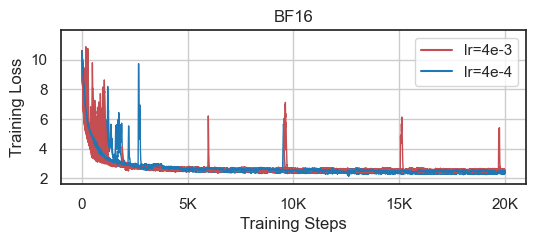
Figure 5: Learning rate robustness comparison between models trained using E8M5 masking versus standard BF16.
Discussion and Future Directions
The findings underscore the current constraints of FP8 implementations for training purposes, asserting its uneconomic viability due to the requisite hyperparameter tuning and inherent instability risks. However, potential strategies for stabilizing FP8 training, such as targeted higher-precision application in sensitive layers and dynamic precision transitions during unstable phases, are proposed for further exploration.
Conclusion
The study delineates the complex dynamics between bit precision and training stability in LLMs, illustrating that reduced-precision formats such as FP8 still require substantial development before becoming economically feasible for LLM training. The proposed sharpness metric and analysis pathways offer a foundational toolset for advancing the understanding and potential application of low-precision computation in LLM training, pointing toward more efficient yet robust training methodologies.
In sum, while FP8 shows promise for inference tasks, its application in training remains unstable under current schemes, rendering it unsuitable for widespread LLM training deployment without further stabilization techniques.

