- The paper presents a novel FOG architecture that employs FP8 computations in all GEMMs to boost throughput by up to 40% compared to BF16 training.
- It utilizes techniques like RMS normalization and QK entropy regularization to counteract the numerical instabilities inherent in low-precision FP8 formats.
- Experimental results across multiple model scales confirm that FOG architectures maintain robust training with sustained low activation kurtosis levels.
Towards Fully FP8 GEMM LLM Training at Scale
Introduction
The introduction of FP8 data formats for large-scale LLM training has demonstrated the potential for significant efficiency improvements by reducing computational resources. However, challenges such as stability issues during training have constrained its adoption. Existing approaches often incorporate higher-precision computations for sensitive parts of LLM architectures, which limits throughput gains. This paper presents an innovative class of transformer architectures capable of performing FP8 computations across all GEMMs within the transformer blocks, achieving unprecedented throughput improvements up to 40% without sacrificing downstream performance compared to BF16 training.
FP8 Training Challenges
FP8 formats are appealing due to their lower precision, which can accelerate computations on suitable hardware accelerators. Nevertheless, the narrow dynamic range of FP8 causes higher susceptibility to numerical instability, such as underflows and overflows. Activation functions in transformers, particularly those that produce large outlier features, exacerbate this risk and often require careful scaling techniques when transitioning from higher precision formats. The introduction of FOG architectures aims to address these outlier-related instabilities by modifying standard transformer designs to promote stable FP8 training throughout all stages of development.
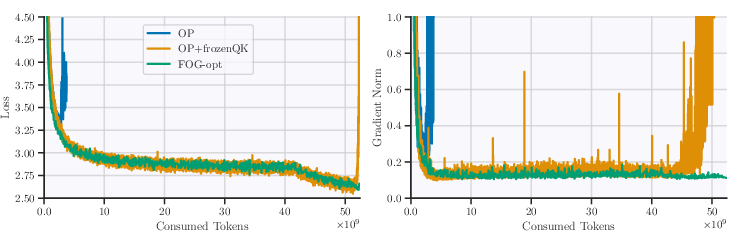
Figure 1: From OP to step by step. The first run to diverge is OP, while OP with frozen QK RMSNorm survives the stable phase but diverges during learning rate cooldown. The converged run adds post-normalization.
FOG Architecture Design
FOG architectures prioritize preventing large activation outliers to stabilize FP8 training. By altering existing transformer architectures to omit pre-normalization blocks and incorporating methods like RMS normalization and QK entropy regularization to prevent entropy collapse, they maintain signal propagation to effectively minimize training divergences. These adjustments support the utilization of FP8s across more components than previously feasible.
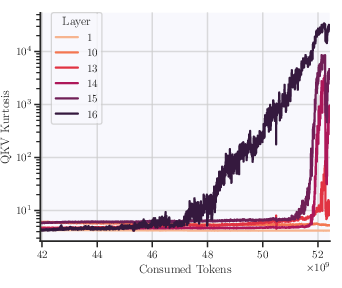
Figure 2: Kurtosis of QKV tensors during FP8DPA learning rate cooldown with OP+frozenQK architecture. Later layers show significantly larger activation outliers.
Long-term Outlier Dynamics
Kurtosis serves as a metric for assessing the extremity of deviations due to outliers in activation values throughout training. By monitoring kurtosis, which quantifies outlier prevalence in key activations of transformers, FOG ensures long-term FP8 stability. Notably, sustained low kurtosis levels during extended training regimes indicate reduced susceptibility to outlier-induced divergences, supporting the robustness claimed by the architecture.
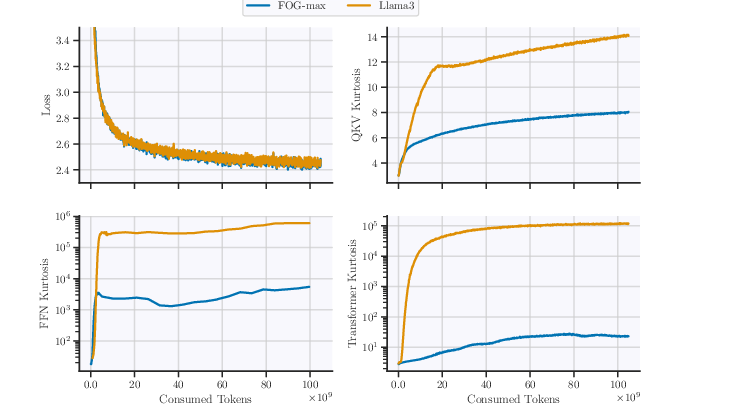
Figure 3: Loss and kurtosis training dynamics comparing models with a standard GLU-based vs. pre-normalized activation variants over 100B tokens.
Experimental Results
Extensive experiments validate the proposed architecture across varying scales and baseline adjustments. Conducted over several model sizes (0.4B, 1.5B, and 8B), results affirm the comparable performance of FOG architectures against BF16 standards, emphasizing throughput improvements up to 40%. Training was executed using FP8 computations for attention and final projection layers, showcasing significant gains in efficiency.
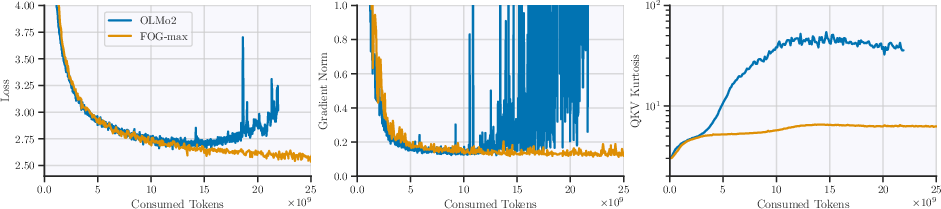
Figure 4: Training dynamics of failed vs. successful FP8DPA runs. Kurtosis diverging earlier than loss demonstrates its utility for prediction.
Limitations and Future Work
Though advancing FP8 utilization within transformers, FOG architectures still require BF16 for specific sensitive computations like final projections. Future advancements could explore more generalized FP8 applications and optimizer state adaptations to further lower precision memory burdens without compromising performance.
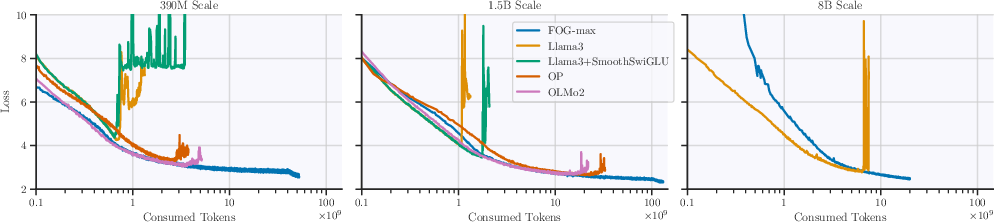
Figure 5: Cross-entropy loss plots across different architectures over long-data training regimes, showing FOG's capacity to train continuously without divergence.
Conclusion
FOG architectures represent a significant advancement in enabling FP8 LLM training across scales without sacrificing computational performance. This practical approach not only improves efficiency but provides a framework for enhancing stability in long-term training regimes, positioning FP8 formats as viable contenders for widespread LLM applications.
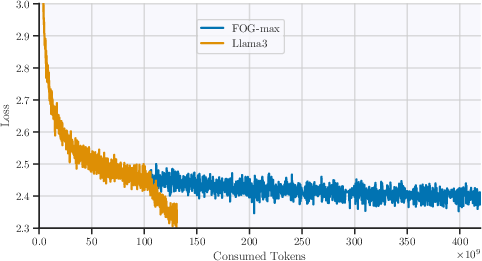
Figure 6: Long-data training regimes with FP8DPA scaled progressively against established higher precision benchmarks.
The research presented establishes the viability of FP8 for extensive LLM training, paving the way for further exploration of architecturally supportive components and techniques to enhance FP8 adoption in the future.