- The paper demonstrates that reinforcement learning can efficiently discover fault-tolerant quantum circuits that reduce gate counts and ancillary qubit usage.
- It introduces a complementary tableau distance metric and reward shaping to overcome sparse reward challenges in the RL-driven quantum circuit design.
- The RL-generated circuits achieve competitive performance across various QEC codes, suggesting a scalable pathway for advanced quantum computing.
Quantum Circuit Discovery for Fault-Tolerant Logical State Preparation with Reinforcement Learning
Overview
The paper entitled "Quantum Circuit Discovery for Fault-Tolerant Logical State Preparation with Reinforcement Learning" investigates a novel approach to designing fault-tolerant quantum circuits necessary for large-scale quantum computing. The study capitalizes on reinforcement learning (RL) to automate and optimize the discovery of fault-tolerant circuits for logical state preparation, taking into account hardware constraints like qubit connectivity and available gate sets.
The authors propose utilizing RL to discover efficient quantum circuits that require fewer gates and ancillary qubits compared to traditional methods. The application of RL in this domain not only facilitates the exploration of different qubit connectivity but also leverages transfer learning to accelerate circuit discovery. This method extends beyond logical state preparation to tasks such as magic state preparation and logical gate synthesis, hinting at a broad applicability across quantum error correction (QEC) tasks.
Quantum Error Correction and Fault Tolerance
Quantum systems inherently suffer from errors due to decoherence, necessitating the implementation of quantum error correction (QEC) to safeguard quantum information. QEC encodes logical qubits into multiple physical qubits, allowing for error detection and correction without compromising the logical state. The study emphasizes the critical role of fault-tolerant (FT) circuits in quantum computation, which are designed to prevent error multiplication and ensure scalable quantum computing.
The paper discusses various FG strategies, including stabilizer codes like the Steane and Reed-Muller codes, providing a robust foundation for implementing QEC. It explores fault-tolerant logical state preparation, highlighting the importance of minimizing possible faults, which the proposed RL-based approach seeks to address.
Reinforcement Learning Framework
The study introduces an RL framework where an RL agent learns to propose quantum circuits by observing the circuit's state and choosing discrete Clifford gate actions. The agent evaluates the quality of the proposed circuits based on rewards designed to enhance fault tolerance and logical state fidelity.
To overcome the sparse reward problem common in RL applications, the authors devise a complementary tableau distance metric, which effectively guides the RL agent by providing continuous feedback on the circuit's progress toward the target state. This metric, along with reward shaping techniques, facilitates efficient learning and rapid convergence of the RL models.
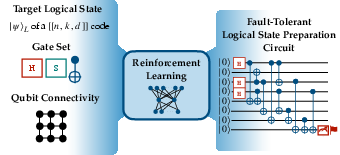
Figure 1: Illustration of the reinforcement learning framework for fault-tolerant quantum circuit discovery.
Logical State Preparation
The RL approach is benchmarked across various QEC codes, including the [[5,1,3]] perfect code and the [[7,1,3]] Steane code. The study reports substantial reductions in gate counts compared to existing heuristic and SAT-based methods. In scenarios with constrained qubit connectivity and specific gate sets, RL models exhibit adaptability, resulting in compact, optimized circuits.
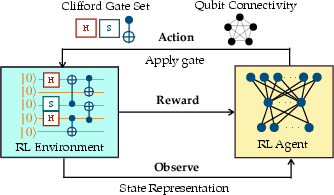
Figure 2: Performance comparison of RL-discovered circuits versus traditional methods for logical state preparation.
Verification Circuit Synthesis
For FT circuit discovery, RL outperforms or matches existing circuits in minimizing gate numbers and qubit usage. The RL-generated circuits display competitive acceptance and logical error rates, affirming their practical applicability.
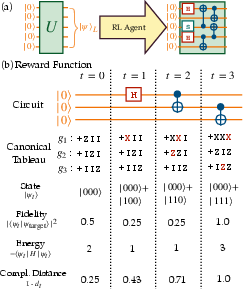
Figure 3: Example of a verification circuit discovered by reinforcement learning showing reduced gate complexity.
Integrated Fault-Tolerant Logical State Preparation
A key highlight is the integrated approach that directly prepares FT logical states, surpassing traditional segregated tasks of state preparation and error correction. By integrating these tasks, RL agents develop more sophisticated strategies, yielding circuits with improved performance metrics.
(Figure 4)
Figure 4: Fault-tolerant logical state preparation circuit synthesized via reinforcement learning in integrated task settings.
Implications and Future Directions
The integration of reinforcement learning in quantum circuit design marks a significant shift towards automated, hardware-tailored quantum computing solutions. This approach addresses critical scalability and performance issues, paving the way for more resilient quantum processors.
The paper suggests future research across tasks like magic state preparation and logical gate synthesis, emphasizing the potential of RL in broader quantum computing applications. Moreover, the study indicates avenues for scaling RL techniques to larger distance codes and optimizing the RL framework for enhanced efficiency and generalization.
Conclusion
This work underscores the potential of reinforcement learning in transforming the landscape of quantum error correction circuits. By bridging the gap between theoretical QEC models and practical, hardware-constrained quantum systems, the study sets a precedent for leveraging AI-driven methods to advance the frontiers of quantum computing technology.