Synergistic Reinforcement and Imitation Learning for Vision-driven Autonomous Flight of UAV Along River
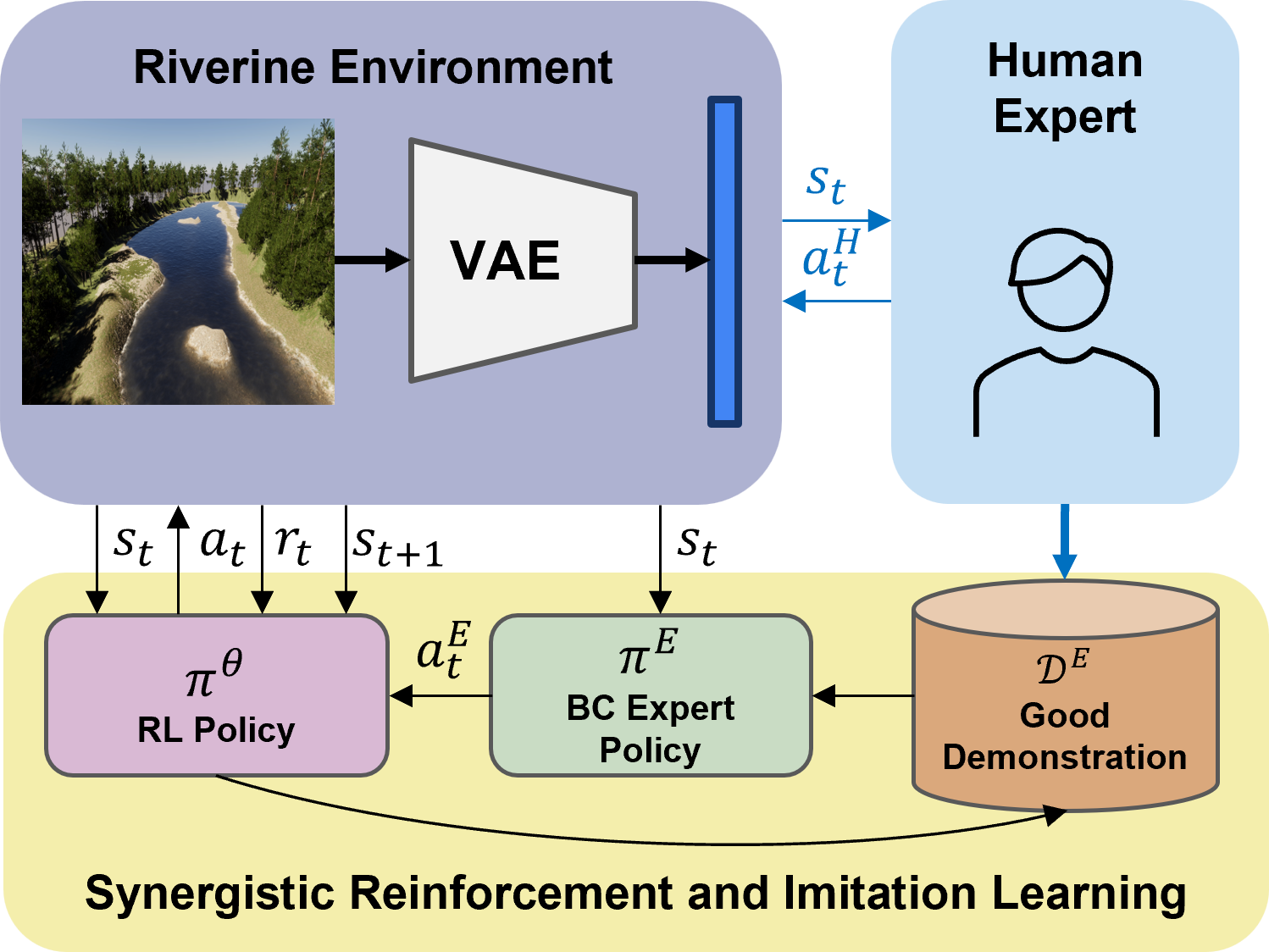
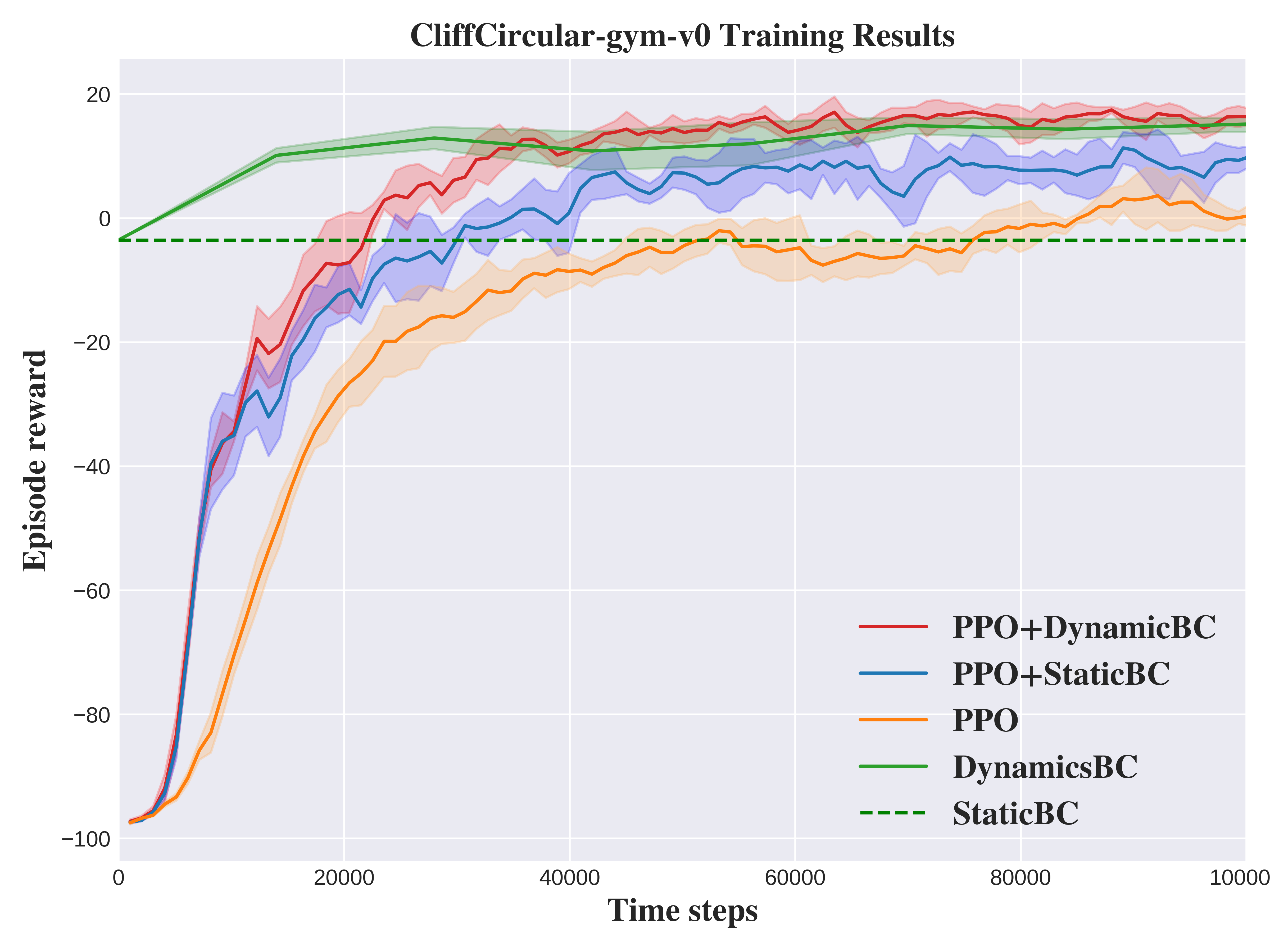
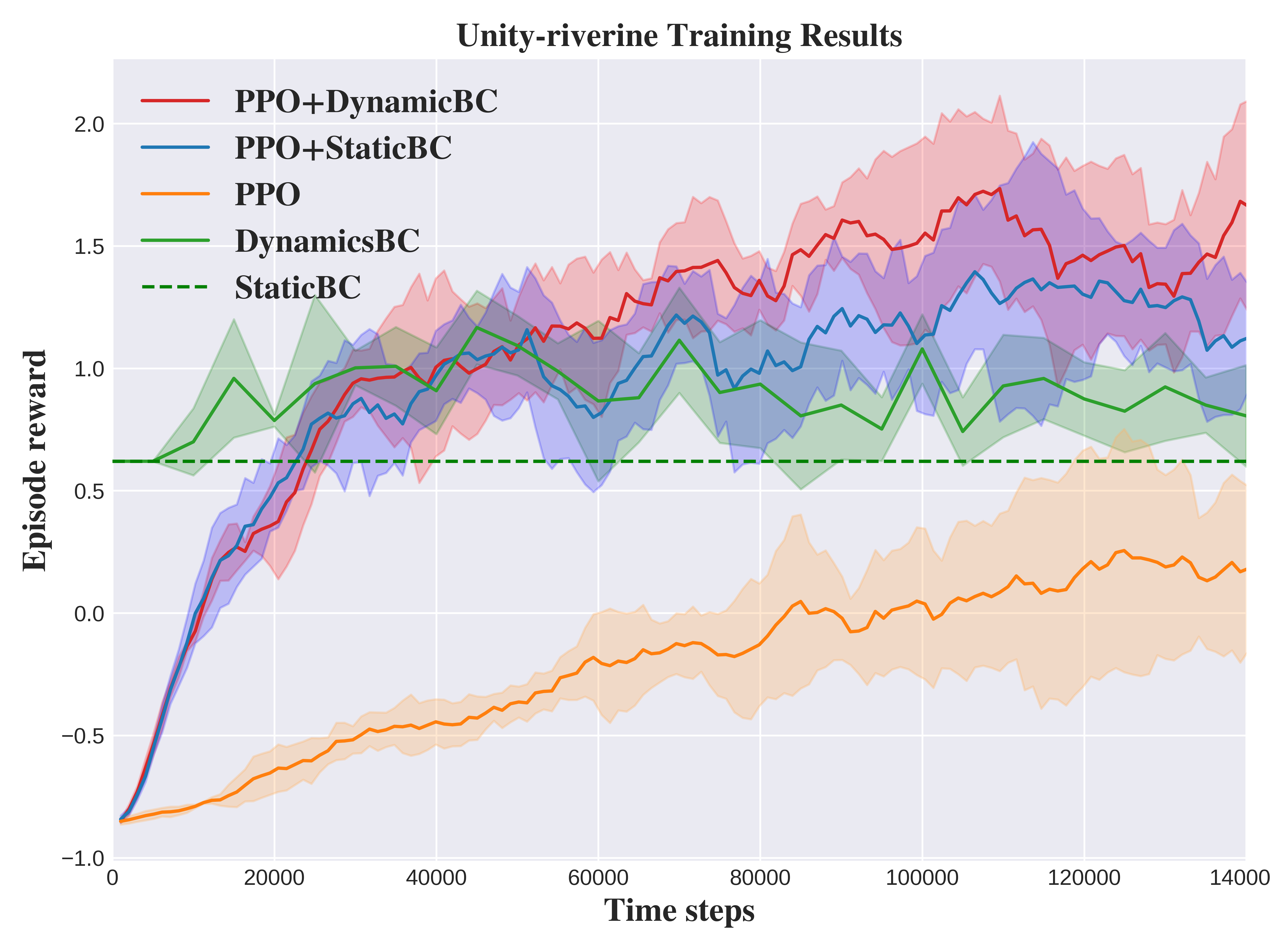
Abstract: Vision-driven autonomous flight and obstacle avoidance of Unmanned Aerial Vehicles (UAVs) along complex riverine environments for tasks like rescue and surveillance requires a robust control policy, which is yet difficult to obtain due to the shortage of trainable riverine environment simulators. To easily verify the vision-based navigation controller performance for the river following task before real-world deployment, we developed a trainable photo-realistic dynamics-free riverine simulation environment using Unity. In this paper, we address the shortcomings that vanilla Reinforcement Learning (RL) algorithm encounters in learning a navigation policy within this partially observable, non-Markovian environment. We propose a synergistic approach that integrates RL and Imitation Learning (IL). Initially, an IL expert is trained on manually collected demonstrations, which then guides the RL policy training process. Concurrently, experiences generated by the RL agent are utilized to re-train the IL expert, enhancing its ability to generalize to unseen data. By leveraging the strengths of both RL and IL, this framework achieves a faster convergence rate and higher performance compared to pure RL, pure IL, and RL combined with static IL algorithms. The results validate the efficacy of the proposed method in terms of both task completion and efficiency. The code and trainable environments are available.
- M. E. Hodgson, N. I. Vitzilaios, M. L. Myrick, T. L. Richardson, M. Duggan, K. R. I. Sanim, M. Kalaitzakis, B. Kosaraju, C. English, and Z. Kitzhaber, “Mission planning for low altitude aerial drones during water sampling,” Drones, vol. 6, no. 8, p. 209, 2022.
- S. I. Ullah and I. Fullfilment, “Vision-based autonomous mapping & obstacle avoidance for a micro-aerial vehicle (mav) navigating canal,” 2019.
- T. Huang, Z. Chen, W. Gao, Z. Xue, and Y. Liu, “A usv-uav cooperative trajectory planning algorithm with hull dynamic constraints,” Sensors, vol. 23, no. 4, p. 1845, 2023.
- J. Li, G. Zhang, and B. Li, “Robust adaptive neural cooperative control for the usv-uav based on the lvs-lva guidance principle,” Journal of Marine Science and Engineering, vol. 10, no. 1, p. 51, 2022.
- A. Gonzalez-Garcia, A. Miranda-Moya, and H. Castañeda, “Robust visual tracking control based on adaptive sliding mode strategy: Quadrotor uav-catamaran usv heterogeneous system,” in 2021 International Conference on Unmanned Aircraft Systems (ICUAS). IEEE, 2021, pp. 666–672.
- A. Juliani, V.-P. Berges, E. Teng, A. Cohen, J. Harper, C. Elion, C. Goy, Y. Gao, H. Henry, M. Mattar et al., “Unity: A general platform for intelligent agents,” arXiv preprint arXiv:1809.02627, 2018.
- A. Taufik, S. Okamoto, and J. H. Lee, “Multi-rotor drone to fly autonomously along a river using a single-lens camera and image processing,” International Journal of Mechanical Engineering, vol. 4, no. 6, pp. 39–49, 2015.
- A. Taufik, “Multi-rotor drone to fly autonomously along a river and 3d map modeling of an environment around a river,” 2016.
- Y. Song, S. Naji, E. Kaufmann, A. Loquercio, and D. Scaramuzza, “Flightmare: A flexible quadrotor simulator,” in Conference on Robot Learning. PMLR, 2021, pp. 1147–1157.
- A. Loquercio, E. Kaufmann, R. Ranftl, M. Müller, V. Koltun, and D. Scaramuzza, “Learning high-speed flight in the wild,” Science Robotics, vol. 6, no. 59, p. eabg5810, 2021.
- F. Xiang, Y. Qin, K. Mo, Y. Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y. Yuan, H. Wang et al., “Sapien: A simulated part-based interactive environment,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 097–11 107.
- E. Marchesini and A. Farinelli, “Discrete deep reinforcement learning for mapless navigation,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 10 688–10 694.
- P. Zieliński and U. Markowska-Kaczmar, “3d robotic navigation using a vision-based deep reinforcement learning model,” Applied Soft Computing, vol. 110, p. 107602, 2021.
- P. Wei, R. Liang, A. Michelmore, and Z. Kong, “Vision-based 2d navigation of unmanned aerial vehicles in riverine environments with imitation learning,” Journal of Intelligent & Robotic Systems, vol. 104, no. 3, p. 47, 2022.
- D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba, “Openai gym,” arXiv preprint arXiv:1606.01540, 2016.
- J. Li, J. Chavez-Galaviz, K. Azizzadenesheli, and N. Mahmoudian, “Dynamic obstacle avoidance for usvs using cross-domain deep reinforcement learning and neural network model predictive controller,” Sensors, vol. 23, no. 7, p. 3572, 2023.
- S. Aradi, “Survey of deep reinforcement learning for motion planning of autonomous vehicles,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 2, pp. 740–759, 2020.
- S. Feng, H. Sun, X. Yan, H. Zhu, Z. Zou, S. Shen, and H. X. Liu, “Dense reinforcement learning for safety validation of autonomous vehicles,” Nature, vol. 615, no. 7953, pp. 620–627, 2023.
- M. Bain and C. Sammut, “A framework for behavioural cloning.” in Machine Intelligence 15, 1995, pp. 103–129.
- A. Hussein, E. Elyan, M. M. Gaber, and C. Jayne, “Deep imitation learning for 3d navigation tasks,” Neural computing and applications, vol. 29, pp. 389–404, 2018.
- Z. Huang, J. Wu, and C. Lv, “Efficient deep reinforcement learning with imitative expert priors for autonomous driving,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- V. G. Goecks, G. M. Gremillion, V. J. Lawhern, J. Valasek, and N. R. Waytowich, “Integrating behavior cloning and reinforcement learning for improved performance in dense and sparse reward environments,” in Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, 2020, pp. 465–473.
- S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 627–635.
- E. Catmull and R. Rom, “A class of local interpolating splines,” in Computer aided geometric design. Elsevier, 1974, pp. 317–326.
- J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann, “Stable-baselines3: Reliable reinforcement learning implementations,” Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021. [Online]. Available: http://jmlr.org/papers/v22/20-1364.html
- A. Gleave, M. Taufeeque, J. Rocamonde, E. Jenner, S. H. Wang, S. Toyer, M. Ernestus, N. Belrose, S. Emmons, and S. Russell, “imitation: Clean imitation learning implementations,” arXiv:2211.11972v1 [cs.LG], 2022. [Online]. Available: https://arxiv.org/abs/2211.11972




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.