- The paper introduces a decentralized vision-based control framework where drones predict 3D velocity commands by imitating a classical flocking algorithm.
- It employs a compact CNN and domain adaptation techniques to bridge the sim-to-real gap, enabling real-time onboard inference with limited hardware.
- Simulation and real-world experiments validate the approach by demonstrating robust collision avoidance and swarm cohesion without explicit communication.
Vision-Based Decentralized Control of Drone Swarms via Imitation Learning
Introduction and Motivation
The paper addresses the challenge of achieving fully decentralized, communication-free coordination in drone swarms using only onboard vision. Traditional multi-agent aerial systems typically rely on centralized control or explicit position sharing via GNSS or motion capture, introducing single points of failure and limiting scalability in environments with unreliable communication. The authors propose an end-to-end learning-based approach where each drone predicts its 3D velocity commands directly from raw omnidirectional images, imitating a classical flocking algorithm. This eliminates the need for position sharing or visual markers, moving towards robust, scalable, and markerless swarm autonomy.

Figure 1: Vision-based multi-agent experiment in a motion tracking hall, demonstrating fully decentralized, collision-free collective motion using only local omnidirectional visual inputs.
Methodology
Flocking Algorithm as Expert Policy
The expert policy is based on a modified Reynolds flocking algorithm, incorporating only separation (collision avoidance) and cohesion (flock centering) terms, with an optional migration term for goal-directed navigation. The velocity command for each agent is computed as:
vi=visep+vicoh+vimig
where visep and vicoh are functions of the relative positions of neighboring agents within a cutoff radius, and vimig directs the agent towards a global migration point. The velocity is capped at a maximum speed to ensure safety and stability.
Each drone is equipped with six cameras arranged in a cube-map configuration, providing omnidirectional grayscale images (128×128 per camera, concatenated to 128×768). The hardware implementation uses OpenMV Cam M7 modules, an NVIDIA Jetson TX1 for onboard inference, and a Pixracer autopilot for low-level control.
Imitation Learning Framework
The control policy is learned via on-policy imitation learning using DAgger. The neural network maps the concatenated omnidirectional image to a 3D velocity command in the drone's body frame. Data is collected iteratively: the current policy is executed, and the expert (flocking algorithm) provides target actions for the observed states. The dataset is aggregated and the policy is retrained after each iteration.
Domain Adaptation
To bridge the sim-to-real gap and minimize the need for real-world data, the authors introduce a simple domain adaptation technique. Simulated drone images (foreground) are composited onto real background images collected from the deployment environment, producing visually realistic training samples without requiring labeled real-world data.
Visual Policy Architecture
A compact convolutional neural network is used, optimized for regression of velocity commands. The architecture avoids multi-head outputs to simplify optimization. Training uses Adam with regularized MSE loss, data augmentation (brightness, contrast, yaw rotation), and batch normalization. The network is trained until validation loss plateaus.
Simulation Results
The learned vision-based controller is evaluated in simulation against the position-based expert. Two scenarios are tested: (1) all agents share a common migration goal, and (2) agents are split into subgroups with opposing migration goals.
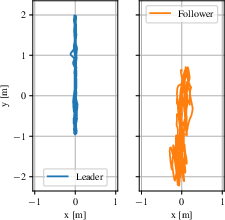

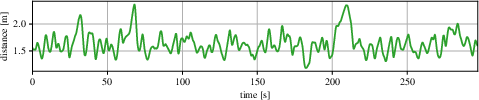
Figure 2: Top-view trajectories of agents under the vision-based controller, showing coherent migration and collision avoidance.
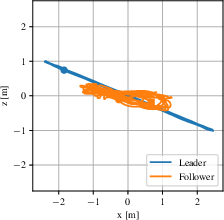
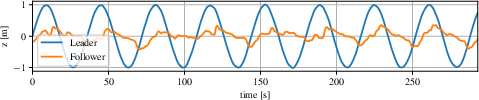
Figure 3: Top-view trajectories for the opposing migration goals scenario, demonstrating swarm cohesion despite diverging objectives.
The vision-based controller closely matches the expert in both minimum and maximum inter-agent distances, maintaining collision-free operation and group cohesion. Notably, the vision-based swarm reaches migration goals more slowly than the position-based swarm, indicating a trade-off between perception-based control and optimality.
Real-World Experiments
Three real-world experiments validate the approach:
- Circle Experiment: A vision-based follower maintains stable cohesion with a leader executing a circular trajectory.
- Carousel Experiment: The follower tracks a leader with modulated altitude, demonstrating full 3D control.
- Push-Pull Experiment: The follower avoids collisions when placed on a direct path with the leader, confirming learned separation behavior.
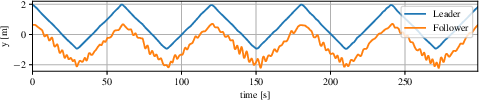
Figure 4: Top-view trajectories from real-world experiments, illustrating the ability of the vision-based controller to maintain cohesion and avoid collisions in dynamic scenarios.
Attribution and Interpretability
A Grad-CAM-based attribution study reveals that the network learns to localize other agents in the visual input, with the most salient regions corresponding to the positions of neighboring drones. Some attention is also paid to visually cluttered regions, likely due to background variability.

Figure 5: Heat map visualization of pixel importance in the visual input for velocity prediction; red regions indicate high influence on control commands.
Implementation Considerations
- Computational Requirements: The policy network is lightweight enough for real-time onboard inference on embedded hardware (Jetson TX1).
- Sample Efficiency: The DAgger-based imitation learning loop, combined with domain adaptation, reduces the need for extensive real-world data collection.
- Scalability: The approach is inherently scalable, as each agent operates fully independently, relying only on local perception.
- Limitations: The current system is validated with up to nine agents in simulation and two in real-world experiments. Performance in larger, more cluttered environments and with more agents remains to be demonstrated.
- Deployment: The method is suitable for indoor environments with known backgrounds; generalization to outdoor or highly dynamic scenes may require more advanced domain adaptation or unsupervised representation learning.
Implications and Future Directions
This work demonstrates the feasibility of decentralized, vision-based control in drone swarms without explicit communication or markers. The approach is a significant step towards robust, scalable, and infrastructure-free multi-agent aerial systems. The results suggest that end-to-end learning from visual input can capture both collision avoidance and group cohesion, provided sufficient expert demonstrations and domain adaptation.
Future research directions include:
- Scaling to larger swarms and more complex environments
- Incorporating obstacle avoidance and dynamic scene understanding
- Leveraging unsupervised or self-supervised learning for improved generalization
- Extending to outdoor scenarios with variable lighting and backgrounds
- Integrating attention mechanisms or explicit agent detection for improved interpretability and robustness
Conclusion
The paper presents a practical and effective method for learning decentralized, vision-based control policies for drone swarms via imitation of a classical flocking algorithm. The approach eliminates the need for position sharing or visual markers, achieving robust collision avoidance and group cohesion using only local visual input. The combination of efficient imitation learning, simple domain adaptation, and real-time onboard inference demonstrates the viability of fully decentralized, markerless swarm flight, with promising implications for scalable and resilient multi-agent systems.