- The paper introduces the Performance-Guided Refinement algorithm to focus training on challenging tracks, thereby enhancing policy robustness.
- It utilizes editable Gaussian Splatting with a novel Edit API to rapidly generate diverse static and dynamic navigation environments.
- The framework demonstrates robust sim-to-real transfer, achieving 100% success on unseen tracks in simulation for both fixed-wing UAVs and quadrotors.
Introduction and Motivation
The paper presents FalconGym 2.0, a photorealistic simulation framework for visual aerial navigation, leveraging Gaussian Splatting (GSplat) and a novel Edit API for rapid, programmatic generation of diverse static and dynamic tracks. The central contribution is the Performance-Guided Refinement (PGR) algorithm, which iteratively focuses policy training on challenging tracks, thereby improving generalization and robustness. The framework is validated across two aerial platforms—fixed-wing UAVs and quadrotors—demonstrating superior generalization to unseen tracks and robust sim-to-real transfer.
FalconGym 2.0: Editable GSplat Simulation
FalconGym 2.0 advances prior NeRF-based simulators by adopting GSplat for efficient photorealistic rendering and introducing a world-frame Edit API. The GSplat scene is parameterized as a set of N anisotropic Gaussians, each with mean μj, covariance Σj, color cj, and opacity αj. The Edit API exposes seven composable operations (add, translate, rotate, scale, duplicate, delete, lighting), enabling rapid synthesis of new tracks and dynamic environments.

Figure 1: The Edit API in FalconGym 2.0 enables programmatic world-frame placement and transformation of gates, supporting rapid generation of diverse static and dynamic tracks.
This editability is critical for scalable policy training, allowing for domain randomization and curriculum learning strategies without additional real-world data collection.
Closed-Loop Visual Policy Architecture
The closed-loop system in FalconGym 2.0 comprises a photorealistic renderer, platform-specific dynamics (Dubins airplane for UAVs, 12-state quadrotor model), a perception module, and a controller. The perception module is a U-Net trained to segment gate masks from onboard RGB images, with ground-truth masks generated analytically via 3D-to-2D projection. The controller consumes the predicted mask and a short history of past actions to output the next control command.
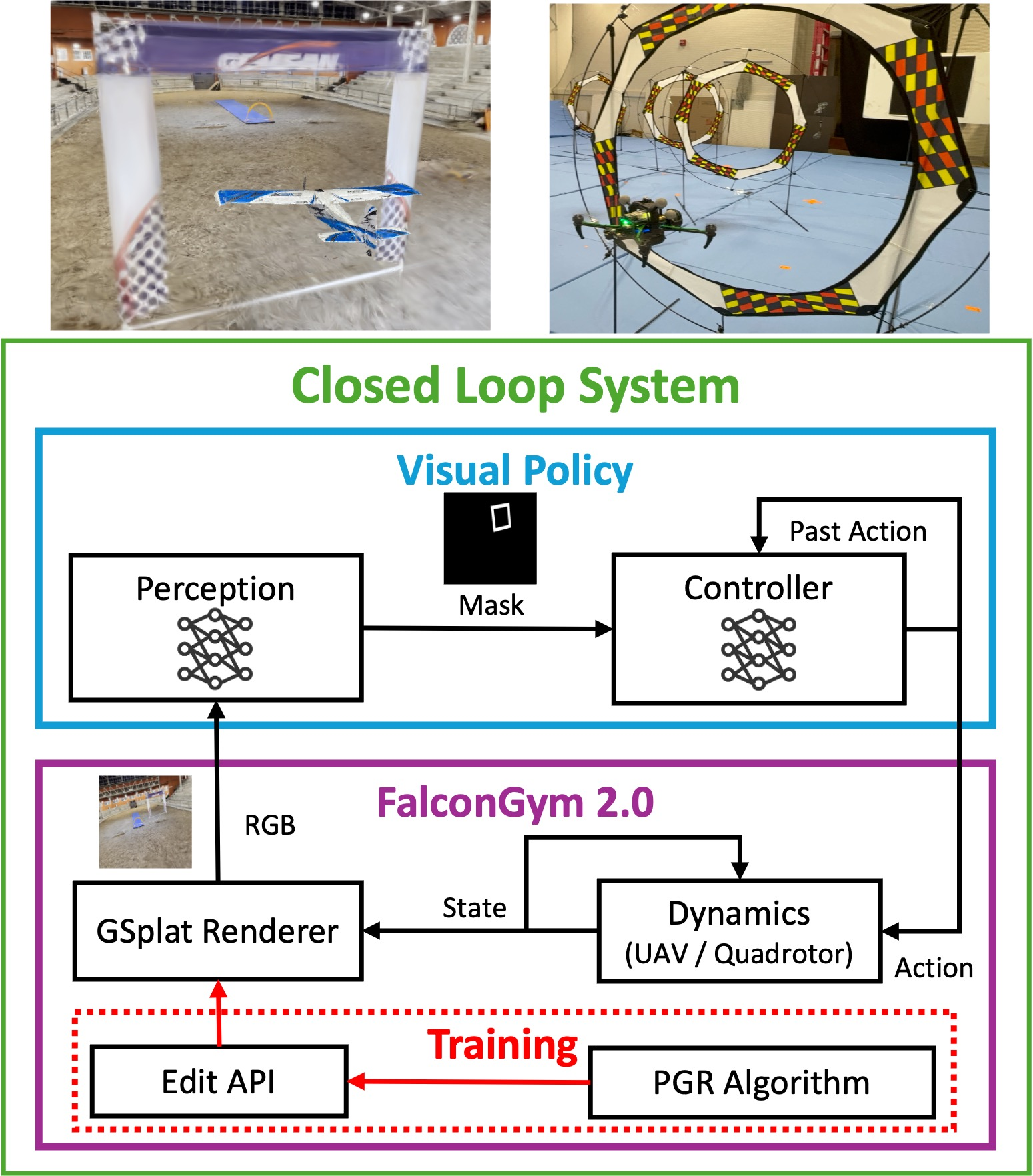
Figure 2: FalconGym 2.0 closed-loop system: dynamics propagate state, GSplat renderer generates RGB, perception predicts gate mask, controller outputs next action; PGR focuses training on challenging tracks.
This modular architecture mitigates overfitting observed in prior end-to-end ViT-based policies, which tended to memorize background features and failed to generalize to new tracks. By decoupling perception and control, the system supports onboard deployment and improved generalization.

Figure 3: UAV trajectories in FalconGym 2.0 across three unseen tracks; red overlays indicate predicted gate masks from the perception module.

Figure 4: Quadrotor trajectories in FalconGym 2.0 across three unseen tracks, demonstrating generalization of the visual policy.
PGR formulates policy training as a min-max optimization problem:
θming∈GmaxEτ∼πθ[L(τ;g)]
where g parameterizes a two-gate track, G is the feasible/observable gate space, and L penalizes collisions, timeouts, and gate crossing error. The algorithm partitions G into grids, evaluates policy performance per grid, and adaptively samples new training tracks from grids with high loss, mixing in uniform sampling to avoid mode collapse.
This approach concentrates data collection on policy failure modes, efficiently improving robustness and generalization. PGR is applied to both perception and controller modules in the fixed-wing UAV case study, and to perception only in the quadrotor case due to onboard compute constraints.
Experimental Results
Fixed-Wing UAV Case Study
Three tracks (Spatial-S, Random, Moving) are synthesized using the Edit API. Five policies are evaluated: state-based expert, two visual baselines (retrained in FalconGym 2.0), and two variants of the proposed method (uniform sampling, PGR). The baselines achieve high success on the training track but fail to generalize (0–50% SR) on unseen tracks. In contrast, both proposed variants generalize with 100% SR across all tracks, with PGR reducing mean gate error (MGE) compared to uniform sampling.
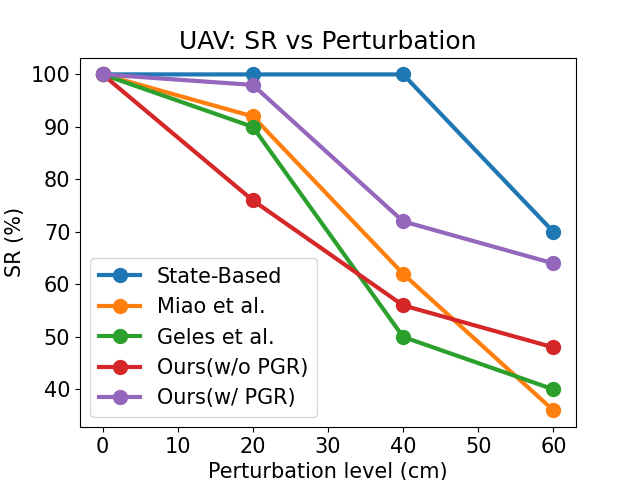
Figure 5: Robustness to gate-pose perturbations for UAV policies; PGR maintains higher success rates under increasing perturbation compared to baselines.
Quadrotor Case Study
Three tracks (Left-Turn, Random, Moving) are evaluated in both simulation and real hardware. Baselines overfit to the training track and degrade on unseen tracks. The proposed methods maintain 100% SR in simulation and ≥93% SR in real-world zero-shot transfer, with PGR providing modest improvements in MGE. The Moving track is evaluated with lateral tracking only for safety.

Figure 6: Real hardware quadrotor trajectories; visual policy trained in FalconGym 2.0 transfers zero-shot to hardware with high success rate.
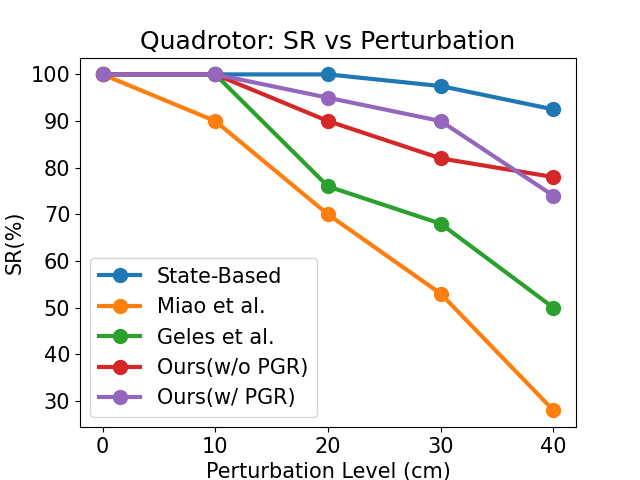
Figure 7: Gate perturbation robustness for quadrotor policies; PGR and uniform sampling outperform baselines as perturbation increases.
Implementation and Deployment Considerations
- GSplat Rendering: Training and inference leverage NeRFStudio Splatfacto pipeline; Edit API operations are tensorized for rapid execution (∼4ms per operation on RTX 4090).
- Perception Module: U-Net segmentation trained on synthetic image-mask pairs generated via Edit API; ground-truth masks computed analytically.
- Controller: Imitation learning from state-based expert; for hardware deployment, classical controller replaces neural controller for real-time constraints.
- PGR Algorithm: Grid-based sampling, adaptive weighting, and uniform mixing to avoid mode collapse; scalable to high-dimensional gate spaces.
- Sim-to-Real Transfer: Policies trained in FalconGym 2.0 are deployed zero-shot to ModalAI Starling 2 quadrotor with onboard inference at 8Hz.
Implications and Future Directions
The results demonstrate that editable photorealistic simulation, combined with performance-guided refinement, enables training of visual policies that generalize across diverse tracks and transfer robustly to real hardware. The modular architecture and Edit API facilitate scalable data generation and efficient policy improvement. The strong numerical results—100% SR on unseen tracks in simulation, 98.6% SR in real hardware—underscore the efficacy of the approach.
Future work should address:
- Relaxing observability constraints to handle occluded gates and more complex environments.
- Scaling to higher-speed flight regimes and more realistic UAV dynamics.
- Distilling the full perception-control stack for onboard deployment at higher frequencies.
- Extending the Edit API to broader robotics domains (e.g., ground robots, manipulation).
Conclusion
FalconGym 2.0, with its editable GSplat simulation and PGR algorithm, establishes a robust framework for visual aerial navigation policy training. The approach achieves strong generalization and sim-to-real transfer, outperforming state-of-the-art baselines in both robustness and success rate. The modular design and efficient data generation pipeline position FalconGym 2.0 as a practical tool for scalable, real-world deployment of visual navigation policies.