- The paper introduces L2D, a dual distillation framework that combines multi-label logits and label-wise embedding distillation for improved performance.
- It transforms multi-label tasks into binary classification problems to overcome softmax limitations and capture fine-grained label distinctions.
- Experiments on datasets like MS-COCO and VOC2007 demonstrate that L2D achieves state-of-the-art mean average precision and F1-scores.
Multi-Label Knowledge Distillation: A Detailed Analysis
The paper "Multi-Label Knowledge Distillation" (2308.06453) addresses the complexities of knowledge distillation (KD) within the context of multi-label learning (MLL). Unlike traditional KD methods focused on single-label classification, this work proposes a novel method aimed at multi-label scenarios, where each instance can correspond to multiple class labels. The proposed approach, termed L2D, incorporates a dual-focused strategy that leverages multi-label logits distillation (MLD) and label-wise embedding distillation (LED) to enhance classification performance.
Introduction and Challenges
The primary challenge addressed by this paper lies in the limitations of existing KD methods when applied to MLL scenarios. Traditional KD typically involves imparting knowledge from a teacher network to a student network by minimizing the difference between their respective logits. However, this approach falters in MLL due to the absence of a summation-to-one constraint in prediction probabilities. The paper posits that conventional logits-based KD is inadequate for MLL due to its reliance on the softmax function. Similarly, feature-based KD approaches often overlook minor class distinctions within a complex semantic landscape.
Proposed Approach: L2D Framework
To tackle the issues identified, the proposed L2D framework innovatively executes a two-pronged strategy:
- Multi-Label Logits Distillation (MLD): This approach adapts a one-versus-all reduction strategy, transforming the multi-label task into multiple binary classification problems. The method seeks to minimize the divergence between the binary predicted probabilities of the teacher and student models. By exploiting the semantic knowledge encapsulated in the teacher model’s logits, MLD aims to furnish informative guidance to the student model.
- Label-wise Embedding Distillation (LED): This component enhances the distinctiveness of feature representations by leveraging structural information from label-wise embeddings. It introduces two types of structural consistency: class-aware label-wise embedding distillation (CD), which enhances intra-class compactness, and instance-aware label-wise embedding distillation (ID), which promotes inter-class dispersion. These constraints enable the student model to capture semantic structures more effectively.
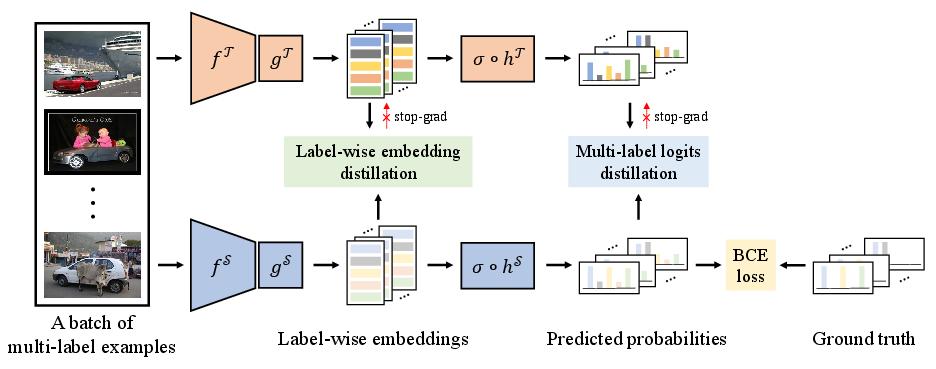
Figure 1: An illustration of the L2D framework. The framework simultaneously performs multi-label logits distillation and label-wise embedding distillation to improve the performance of the student model.
Experimental Evaluation
Extensive experiments were conducted on benchmark datasets such as MS-COCO, VOC2007, and NUS-WIDE. The results consistently demonstrated the superiority of the proposed L2D framework over competing KD methods in various metrics such as mean average precision (mAP), overall F1-score (OF1), and per-class F1-score (CF1).
The L2D framework achieved state-of-the-art results, significantly outperforming baseline models across all metrics. Notably, when both teacher and student models employed the same architectural framework, L2D approached teacher-level performance, even surpassing it in certain configurations, suggesting effective knowledge transfer.
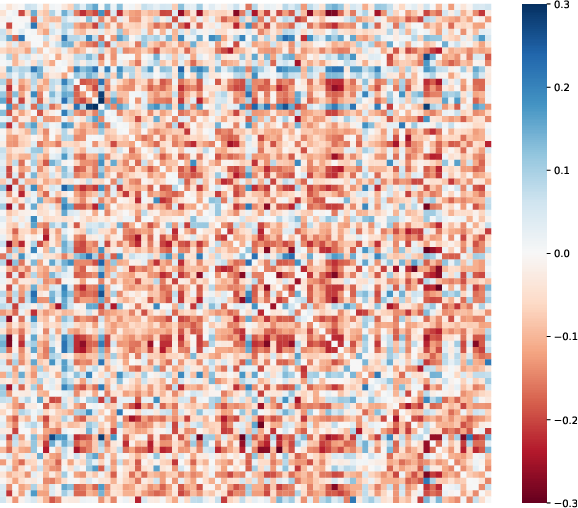
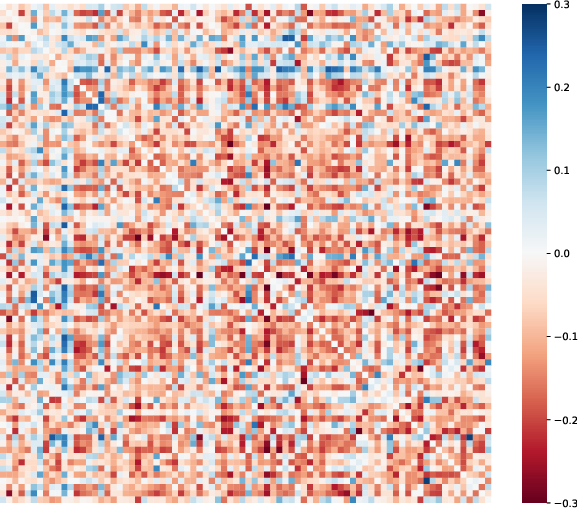

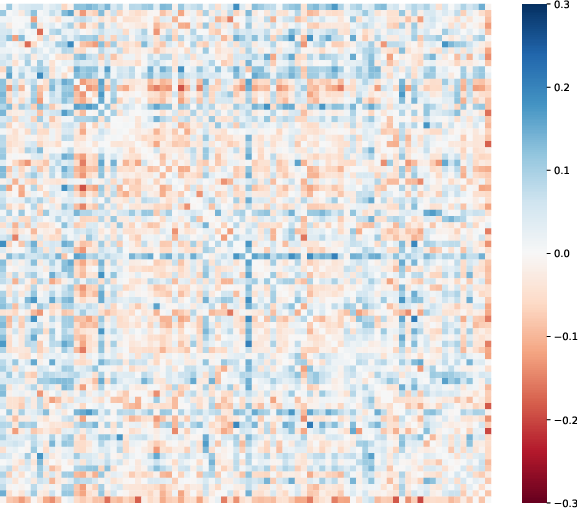
Figure 2: The differences between correlation matrices of student and teacher predicted probabilities on MS-COCO.
Ablation Studies and Insights
Ablation studies confirmed the importance of each component within the L2D framework. The multi-label logits distillation and label-wise embedding distillation individually contributed to the enhanced performance observed, with a combined application yielding the most significant improvements. These findings underline the efficacy of the proposed dual-distillation approach in capturing complex semantic relationships that characterize multi-label datasets.
Conclusion
This work presents a compelling advancement in the application of knowledge distillation to multi-label learning scenarios. By addressing the inherent challenges of existing KD methods, the L2D framework not only improves student model performance but also opens avenues for further exploration of structural knowledge distillation techniques. Future research could further enhance MLKD effectiveness by integrating additional structural information, thereby advancing the functional capacity of machine learning models in resource-constrained environments.
