- The paper introduces IPA, a lightweight adapter that uses reinforcement learning to steer extreme-scale LLMs without modifying the base model’s parameters.
- It demonstrates substantial performance gains in reducing toxicity, enforcing lexical constraints, and enhancing dialogue safety compared to baseline methods.
- The IPA method offers a scalable and cost-effective alternative to fine-tuning, paving the way for broader applications and future research in controllable AI.
Inference-Time Policy Adapters (IPA): Tailoring Extreme-Scale LMs Without Fine-tuning
Introduction
The research on "Inference-Time Policy Adapters (IPA): Tailoring Extreme-Scale LMs without Fine-tuning" tackles the limitations of current LLMs, particularly the restricted control via pure prompting and the prohibitive cost of traditional fine-tuning. Addressing these issues, the authors introduce Inference-time Policy Adapters (IPA), a technique that leverages reinforcement learning to dynamically guide LLMs like GPT-3 during inference without altering the model's inherent parameters. This approach is evaluated across several challenging tasks, demonstrating substantial performance improvements over baselines, including some that rely on expensive fine-tuning.
Background and Problem Statement
LLMs like GPT-3 achieve state-of-the-art performance across numerous tasks but lack precise control for tasks requiring specific constraints or objectives, such as toxicity reduction or lexical constraints. Traditional fine-tuning approaches are costly and, in some cases, infeasible due to the limited accessibility of model parameters in commercial offerings like GPT-4. The proposed IPA method operates by integrating a lightweight policy adapter, optimized through reinforcement learning, to effectively drive the LLM's outputs to align with user-specified objectives without necessitating parameter updates.
Methodology: Inference-time Policy Adapters
IPA integrates reinforcement learning with an inference-time strategy, utilizing a lightweight policy adapter to modulate a base LLM's output:
- Policy Adaptation: The adapter policy collaborates with the base policy to form a "tailored policy" by multiplying their output probabilities, allowing alterations in the output distribution without necessitating parameter access.
- Adapter Training: Using reinforcement learning, the adapter is optimized with a focus on maximizing a reward function that aligns with user objectives. The training freezes the base model's parameters, optimizing only the adapter.
- Approximate Policy: For extremely large models where direct integration is computationally expensive, a smaller approximate policy is employed during adapter training. This policy can be a lesser model from the same family or a distilled version of the target model.
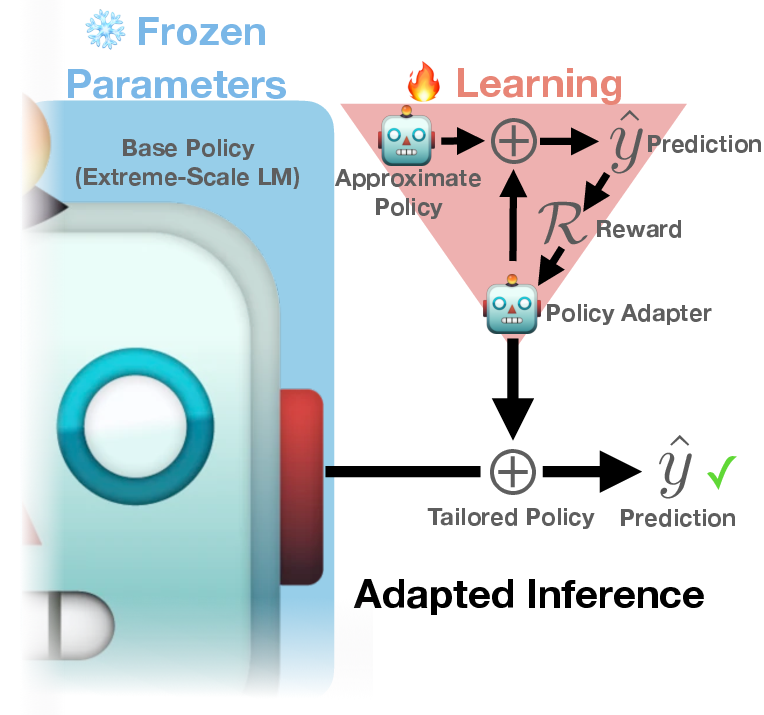
Figure 1: Inference-time Policy Adapters (IPA) efficiently steer a large-scale LLM (such as GPT-3) during decoding-time through a lightweight policy adapter trained to optimize any arbitrary user objective with reinforcement learning.
Experimental Evaluation
IPA was evaluated on five different text generation tasks, showing consistent improvements:
- Toxicity Reduction: IPA significantly reduced toxicity in text generation when applied to GPT-2 and GPT-3, outperforming state-of-the-art methods like DAPT and Quark in both toxicity metrics and linguistic quality.
- Lexically Constrained Generation: IPA showed substantial gains in lexical constraint adherence on the CommonGen dataset, surpassing even more advanced models like GPT-3.5 and GPT-4.
- Open-ended Generation: In open-domain settings, IPA enhanced coherence and human-likeness, with noticeable improvements in Mauve and critic scores compared to baselines.
- Dialogue Safety Control: IPA tailored Blenderbot models delivered safer and more coherent responses than other advanced dialogue systems.
- Knowledge-grounded Dialogue: It significantly improved the faithfulness of the generated dialogue content without sacrificing engagement or coherence.
Implications and Future Work
IPA presents a scalable, efficient alternative to traditional LLM fine-tuning methodologies. By enabling academic-level resources to perform effective model alignment, it opens the door for broader use in various NLP applications requiring stringent control over output characteristics. Future work could explore more diverse adapters and extend the approach to multimodal models, potentially enhancing applications in dialogue systems, automated writing, and content creation. The dual-use nature of IPA, when combined with potent LLMs, suggests that while beneficial for several applications, responsible usage is paramount to avoid misuse in generating harmful content.
Conclusion
Inference-Time Policy Adapters propose a novel, paradigm-shifting method for effectively steering large-scale LLMs towards user-desired objectives without the overhead and accessibility concerns of full fine-tuning. The empirical results across multiple tasks underscore IPA’s potential to serve as a leading technique for tasks demanding precise output control, paving the way for further advancements in controllable AI systems.