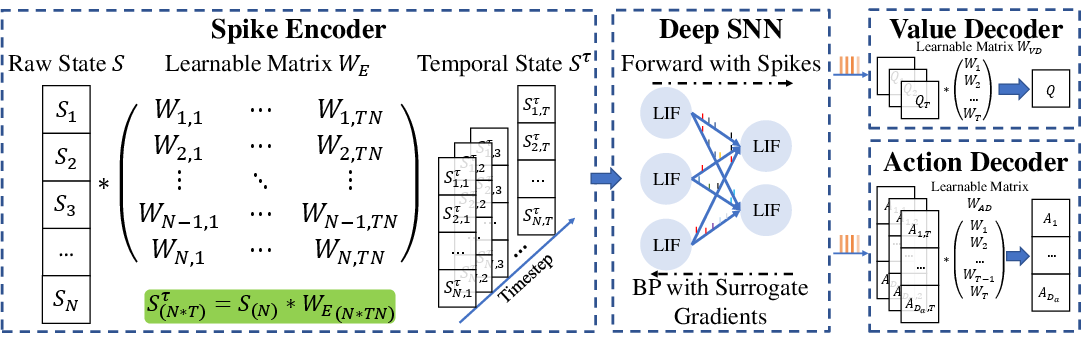
- The paper introduces a novel adaptive coding mechanism for spiking neural networks in deep reinforcement learning, reducing latency and energy usage.
- It employs learnable matrix multiplications for dynamic encoding and decoding of spike trains, enhancing performance on Atari and MuJoCo tasks.
- Experimental evaluations show that ACSF outperforms traditional DQN methods, suggesting promising applications in energy-efficient neuromorphic hardware.
Adaptive Coding Spiking Framework for Deep Reinforcement Learning
This essay provides an expert overview of the paper titled "A Low Latency Adaptive Coding Spiking Framework for Deep Reinforcement Learning" (2211.11760). The paper proposes an innovative framework designed to address the limitations of traditional deep learning methods in resource-constrained environments, specifically targeting latency and energy efficiency issues in spiking neural networks (SNNs) used within reinforcement learning (RL).
Introduction to Spiking Neural Networks in Reinforcement Learning
Spiking Neural Networks (SNNs) offer a biologically plausible alternative to traditional Deep Neural Networks (DNNs), characterized by lower power consumption and event-driven architectures. Despite these advantages, SNNs face challenges in reinforcement learning, notably high latency and limited versatility due to fixed coding methods. The proposed Adaptive Coding Spiking Framework (ACSF) introduces learnable matrix multiplication for encoding and decoding spikes, which enhances the flexibility and reduces the latency of SNNs in RL tasks.
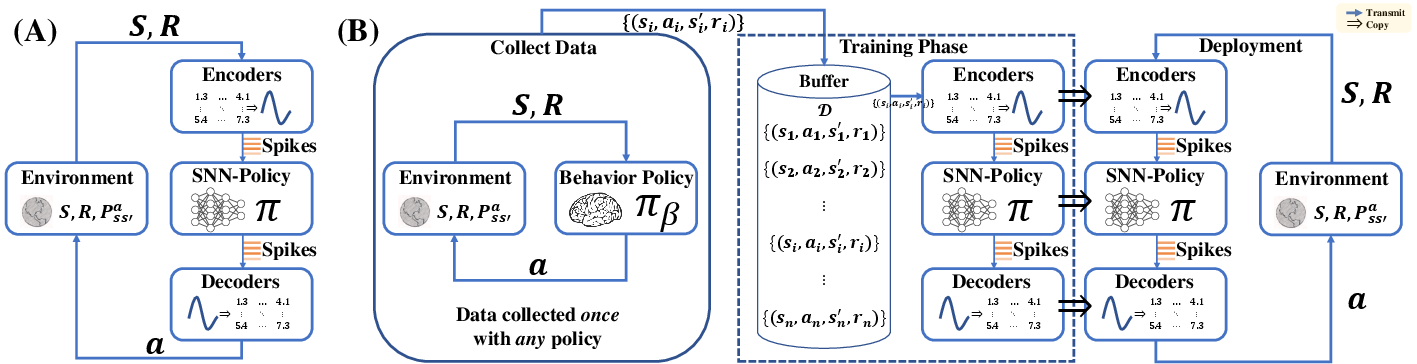
Figure 1: Online and offline SRL frameworks. Environments generally contain elements such as states (S), rewards (R), and state transition probabilities (Pss′a).
ACSF Architecture and Methodology
The architecture, named ACSF, is designed to support both online and offline reinforcement learning algorithms, broadening its applicability compared to existing SRL methods confined to specific RL paradigms.
Adaptive Coding Mechanism
At the core of ACSF is the adaptive coding mechanism that replaces fixed coding methods with learnable, adaptive coders. These coders use matrix multiplication to expand or compress inputs in the time dimension, allowing for a dynamic representation of states and actions:
Training Strategy
ACSF utilizes direct training with surrogate gradients to overcome the non-differentiable nature of spikes in SNNs, ensuring effective optimization of the learnable components within the network.
Experimental Evaluation
ACSF was rigorously evaluated in both discrete (Atari games) and continuous (MuJoCo environments) action-space tasks. The experiments demonstrated that ACSF achieves superior performance with reduced latency and enhanced energy efficiency.
Figure 3: Learning curves for DQN and ACSF. During the training process, the performance of ACSF meets or exceeds that of the DQN algorithm.
In the discrete action-space of Atari games, ACSF outperformed traditional DQN baselines and other spiking methods, enhancing both reward acquisition and computational efficiency.
Application to MuJoCo Environments
For continuous control tasks in MuJoCo, ACSF maintained its edge by delivering higher rewards compared to conventional algorithms like DDPG and BCQ, demonstrating the framework's versatility and adaptiveness.
Figure 4: Learning curves for different algorithms in the MuJoCo environment.
Implications and Future Research Directions
The introduction of ACSF marks a significant advancement in applying SNNs to reinforcement learning, offering a scalable solution without sacrificing real-time performance or energy efficiency. Future research could explore:
- Integration with Neuromorphic Hardware: ACSF's SNN foundation paves the way for deployment on energy-efficient neuromorphic devices.
- Extension to Other RL Algorithms: Exploring compatibility with a broader range of RL methods beyond the current online and offline adaptations.
- Further Reduction in Latency: Refinements to the adaptive coding strategy could push latency reductions even further, increasing real-world applicability.
Conclusion
In summation, the ACSF represents a robust and effective approach to mitigating the challenges faced by SNNs in reinforcement learning. Its adaptive coding and direct training framework allow it to excel in diverse environments while maintaining energy efficiency and low latency, setting a promising direction for future SNN-based RL research.