- The paper presents an adaptive bit allocation method that learns bit widths and temporal lengths to optimize SNN performance while lowering resource demands.
- Experimental results show a 2.69% accuracy gain on ImageNet and a 4.16x reduction in bit budget, validating the method's efficiency.
- The refined spiking neuron model reduces quantization errors and paves the way for integration with neuromorphic hardware for real-time processing.
Overview of "Towards Efficient and Accurate Spiking Neural Networks via Adaptive Bit Allocation"
This paper presents an adaptive optimization technique for enhancing Spiking Neural Networks (SNNs) by allocating bits efficiently across different layers. This method aims to reduce memory and computation demands while maintaining or improving accuracy. The key strategy involves making temporal lengths and the bit widths of weights and spikes learnable, thus enabling sophisticated allocation of resources.
Adaptive Bit Allocation Strategy
Parametrization
The paper introduces a framework wherein temporal lengths (Tl), spike bit widths (Bs,l), and weight bit widths (Bw,l) become learnable parameters. These parameters are bounded and optimized via backpropagation. The equations for parametrization are:
Bs,l=⌊clip(B^s,l,1,Bs,bound)⌉,Tl=⌊clip(T^l,1,Tbound)⌉,Bw,l=⌊clip(B^w,l,1,Bw,bound)⌉
This approach allows for fine-tuned allocation of bit widths matching the specific requirements of different layers, minimum overhead, and improvement in network performance.
With learnable parameters, the conventional formulation was insufficient. A refined spiking neuron is proposed, modeled with a spiking neuron equation reformulated to allow rounding of membrane potentials instead of flooring, potentially reducing quantization errors.
Sout,lt=clip(⌊Vth,l1,t+Vth,l2,tvlt⌋,0,2Bs,lt−1)
This refined model includes a voltage threshold shift Vth,l2 to accommodate rounding operations.
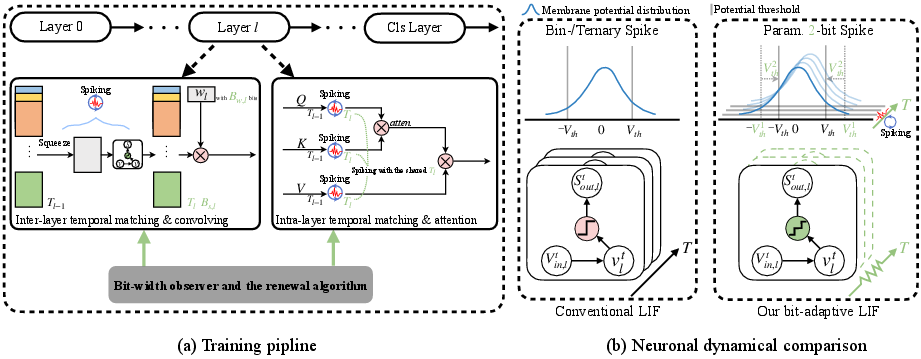
Figure 1: Overview of the proposed bit allocation method. Green notations denote the parametrized constants.
Experimental Evaluation
Results on CIFAR and ImageNet
The proposed network was tested across several datasets and architectures including ResNet-based networks on CIFAR and ImageNet. Notably, the models achieved competitive accuracy with significantly reduced memory requirements and computational effort as measured by the metrics Bit Budget and S-ACE.
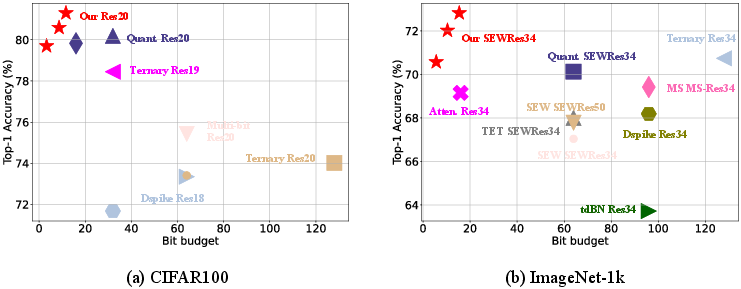
Figure 2: Comparisons with other advanced direct-trained SNNs using ResNet-based architectures on CIFAR100 and ImageNet-1k. Our models maintain the same level of model size as our baselines.
Experimentation demonstrated that the model could achieve a 2.69% accuracy gain on ImageNet with a 4.16x bit budget reduction compared to baselines. Such improvements were consistent across multiple datasets, validating the efficacy of the learning-based bit allocation strategy.
Theoretical and Practical Implications
Mitigation of Step-Size Mismatch
The model also introduces a renewal mechanism to address the step-size mismatch issue which arises when bit widths change dynamically during training. By recognizing and correcting these mismatches, the method ensures robust training of spiking networks without significant loss in accuracy.
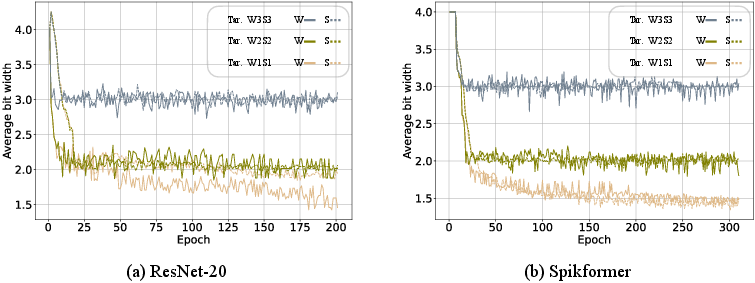
Figure 3: Average bit width changes of ResNet-20 and Spikformer on CIFAR-10 during the adaptive-bit-width training. Tar. abbreviates target bit width. W and S denote weight and spike bit width, respectively.
Future Directions
The adaptive approach underscores the potential for greater resource efficiency in computational neuroscience applications. Future considerations include integrating this approach into neuromorphic hardware platforms, thereby reducing the energy consumption and enhancing the real-time processing capabilities of SNNs.
Conclusion
Overall, the work provides a compelling framework for optimizing SNNs through adaptive bit allocation. By balancing precision and resource consumption, the method reduces computational costs while maintaining high model performance, signifying a substantial advancement in spiking neural network design methodologies.