- The paper introduces SNN-DT, integrating three-factor plasticity, phase-shifted positional encoding, and dendritic routing to achieve energy-efficient sequence control.
- Experimental results show that SNN-DT converges faster and reaches lower validation loss on tasks like CartPole and MountainCar compared to standard Decision Transformers.
- The model processes about 8,000 spikes per inference, consuming approximately 40 nJ on neuromorphic hardware, highlighting its suitability for power-constrained applications.
Introduction
The paper introduces the Spiking Decision Transformer (SNN-DT), a hybrid architecture that integrates biologically inspired spiking neural dynamics with decision transformer models. The main objective is to leverage the inherent energy efficiency of Spiking Neural Networks (SNNs) while preserving the powerful sequential decision-making capabilities of transformers. This integration is particularly significant for deployment on power-constrained neuromorphic hardware, suggesting applications in real-time control scenarios, such as robotics and IoT devices.
The SNN-DT architecture modifies a standard Decision Transformer by incorporating several neuromorphic elements: three-factor synaptic plasticity, phase-shifted positional spike encodings, and dendritic-style routing.
- Three-Factor Plasticity: Replaces backpropagation in the action head with synaptic updates based on local eligibility traces and modulatory signals from the return-to-go, mimicking biologically observed learning rules.
- Phase-Shifted Positional Spike Encoding: Substitutes conventional timestep embeddings with spiking generators that emit unique phase-coded spikes for each head, enhancing temporal representation without dense embeddings.
- Dendritic-Style Routing: Implements a lightweight MLP to dynamically gate attention heads, inspired by the gating mechanisms in biological neurons, allowing adaptive focus on the most relevant temporal features.
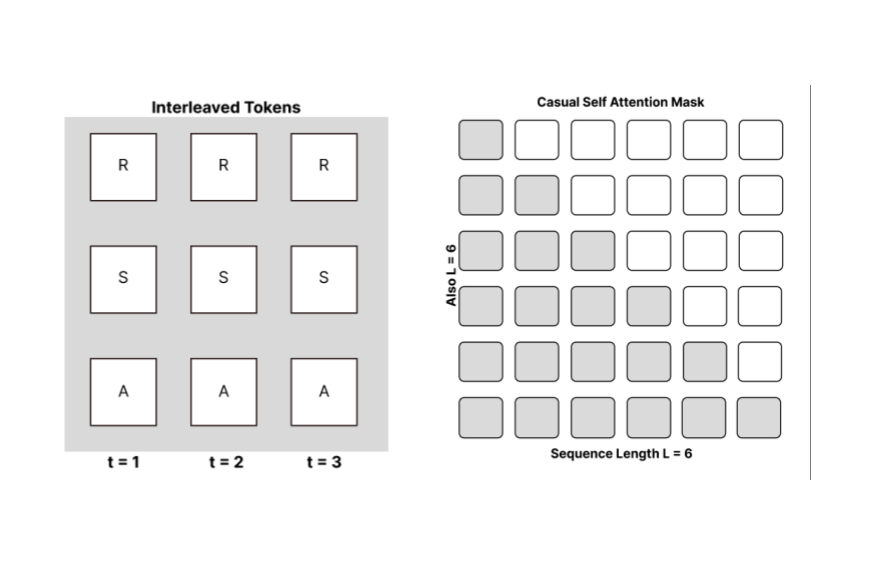
Figure 1: Illustration of token processing in the Decision Transformer. (a) Interleaved return, state, and action tokens in the input sequence (left). (b) Causal self-attention mask applied over the sequence to preserve auto-regressive dependencies (right).
Experimental Evaluation
Energy Efficiency and Hardware Suitability
The paper's empirical results demonstrate that SNN-DT significantly reduces energy consumption per inference step, attributable to the drastically lower spike rates compared to conventional dense transformers. The architecture's average spike count is about 8,000 per inference, translating to an energy cost of approximately 40 nJ on neuromorphic hardware platforms.
The architecture is poised for deployment on processors like Intel's Loihi 2, Forecasting microjoule-level energy usage per decision step, thereby enabling sustainable, long-duration operations on edge devices.
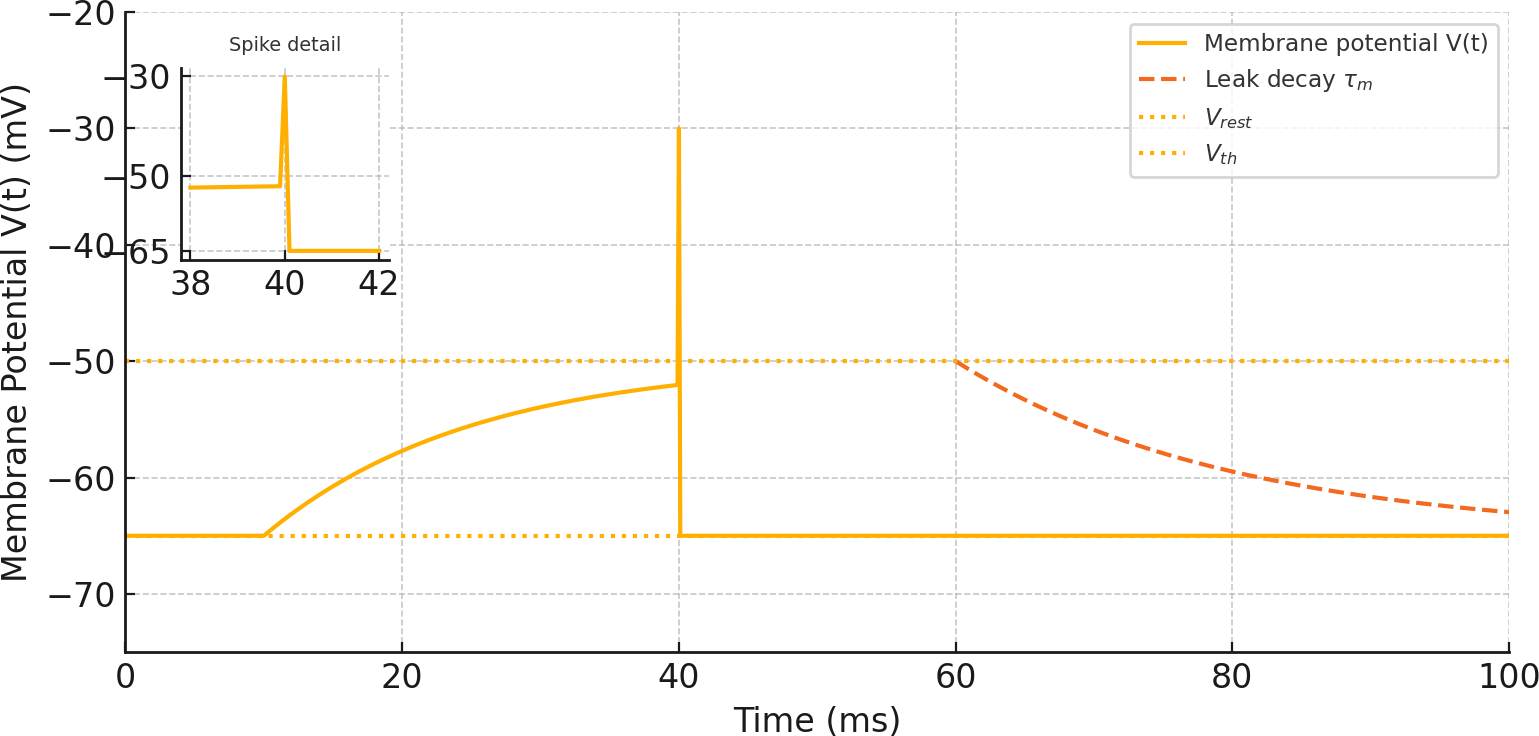
Figure 2: Leaky Integrate-and-Fire Membrane Potential Dynamics.
SNN-DT's performance on various control tasks (CartPole, MountainCar, Acrobot, Pendulum) indicates that it achieves or surpasses the baseline Decision Transformer. The combined benefits of phase-shifted spikes and dendritic routing provide early convergence and reduced validation loss, enhancing both learning speed and final accuracy.
Validation Loss and Adaptability
The proposed model exhibits substantial improvements in validation loss over epochs, with the full configuration yielding the best results in all tested environments. This suggests that the SNN-DT can effectively learn complex temporal dependencies while maintaining energy efficiency.
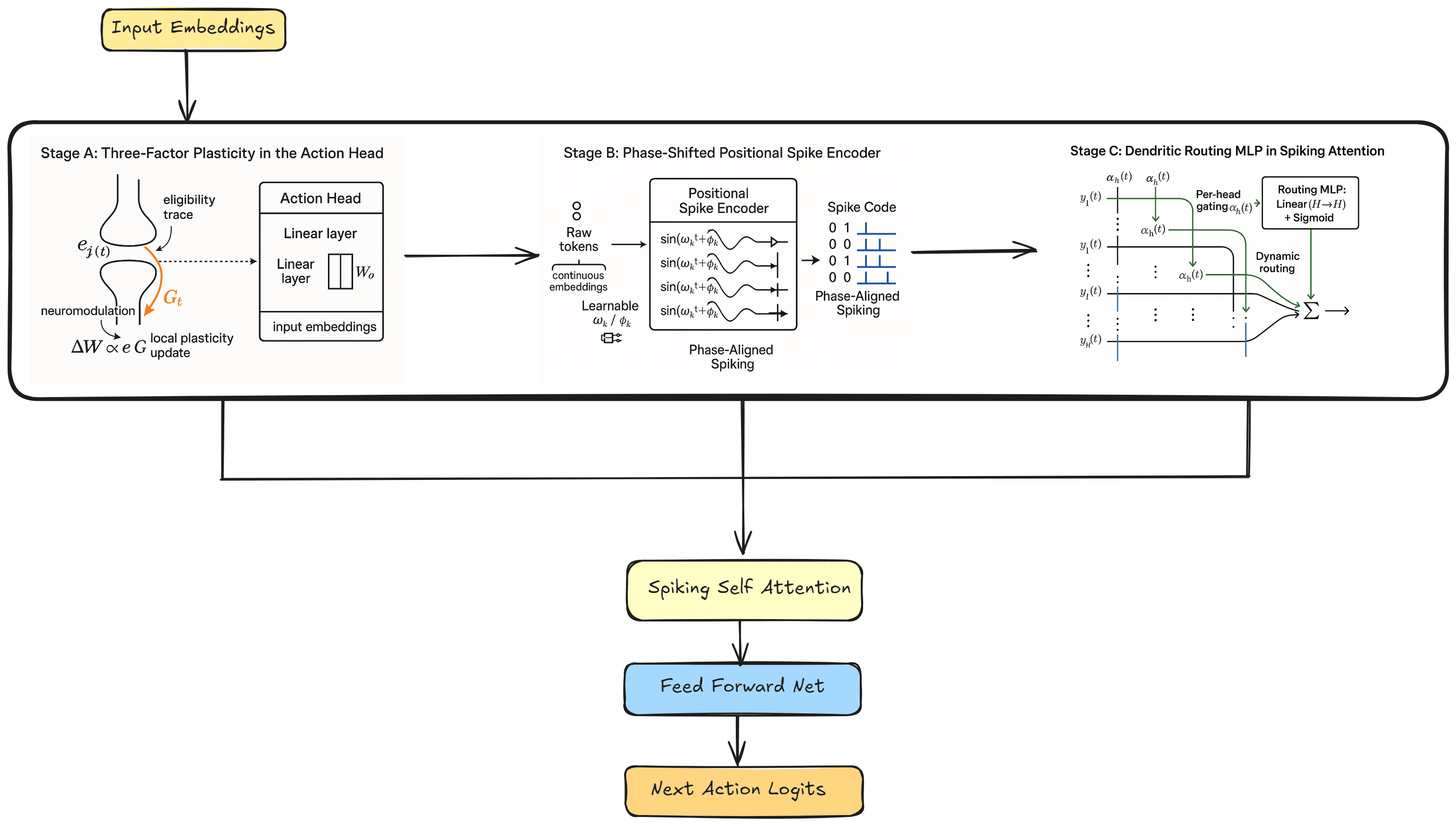
Figure 4: Overall SNN-DT architecture. Highlight: (A) three-factor plasticity in the action head, (B) phase-shifted positional spike encoder, (C) dendritic routing MLP in each attention block.
Discussion
Implications and Future Directions
The SNN-DT represents a significant step towards practical, low-power intelligence for real-time applications. It introduces a viable approach for deploying Transformer-like architectures on neuromorphic platforms, balancing power efficiency with learning capabilities.
Future work could explore extended scalability for longer sequences via sparsification techniques, enhance continual learning mechanisms to reduce buffer dependencies, and validate on physical neuromorphic boards to establish robustness and real-world applicability. Additionally, incorporating hybrid local-global learning paradigms could support ongoing adaptation post-deployment.
Conclusion
By integrating synaptic plasticity, spike-based positional encoding, and adaptive routing, SNN-DT marries the data-driven aptitude of Decision Transformers with SNNs' energy-efficient operation, making it a promising candidate for energy-constrained AI applications across various fields. Transitioning from proof-of-concept to broader utility will involve addressing challenges such as sequence length scalability and hardware validation.