- The paper introduces a comprehensive benchmark (CREATE) for Chinese short video retrieval and titling, featuring over 210K annotated video clips.
- It presents the ALWIG model, which uniquely integrates a tag-driven video-text alignment module with a GPT-based generation module.
- Experimental results show improved video retrieval (Recall@K) and titling (CIDEr) metrics, outperforming traditional models.
CREATE: A Benchmark for Chinese Short Video Retrieval and Title Generation
The paper "CREATE: A Benchmark for Chinese Short Video Retrieval and Title Generation" describes the development of a large-scale dataset and the introduction of a novel model aimed at enhancing video titling and retrieval tasks, particularly within the context of Chinese short videos. This essay provides a detailed analysis of the CREATE benchmark, the associated ALWIG model, and their implications in the field of multi-modal learning.
Benchmark Overview
The CREATE benchmark is the first comprehensive dataset designed for Chinese short video titling and retrieval tasks. It comprises over 210K finely labeled video clips and two expansive pre-training datasets with millions of videos. This benchmark encompasses 51 categories and spans over 50K distinct tags, making it significantly more diverse compared to existing datasets like VATEX and T-VTD. Notably, CREATE aims to bridge the gap between objective video captioning and the more subjective and engaging video titling. The annotations and video tags are meticulously curated, serving as an invaluable resource for benchmarking and enhancing multi-modal learning algorithms.
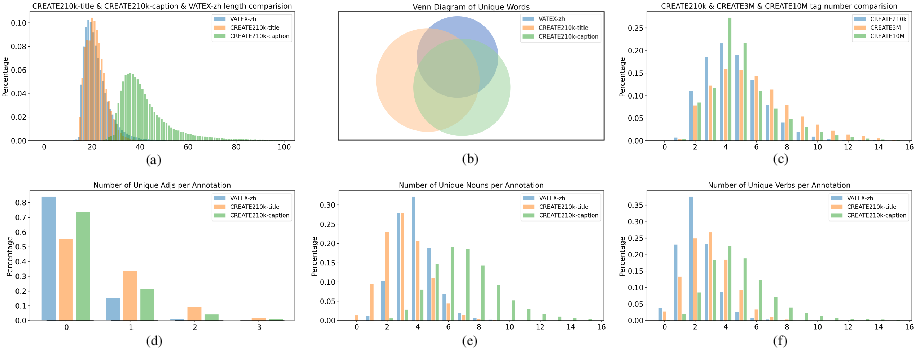
Figure 1: Some statistics on the datasets indicate our datasets and annotations have better diversity. (a) indicates the distribution of the annotation length in three datasets. (b) indicates the inclusion relation of unique words by Venn Diagram in three datasets. (c) represents the distribution of the number of tags. (d)-(f) shows the distribution on three part-of-speech of unique words.
ALWIG Model Architecture
The ALWIG model is designed to address the challenges in video retrieval and titling by employing a hybrid approach that leverages both video retrieval and generation tasks. It incorporates a tag-driven video-text alignment module and a GPT-based generation module. The alignment module uses video tags for semantic alignment between video and text, utilizing a ViT-based encoder for video feature extraction. These features, combined with tag embeddings, are input into cross-encoder and textual-encoder frameworks for multi-modal alignment.
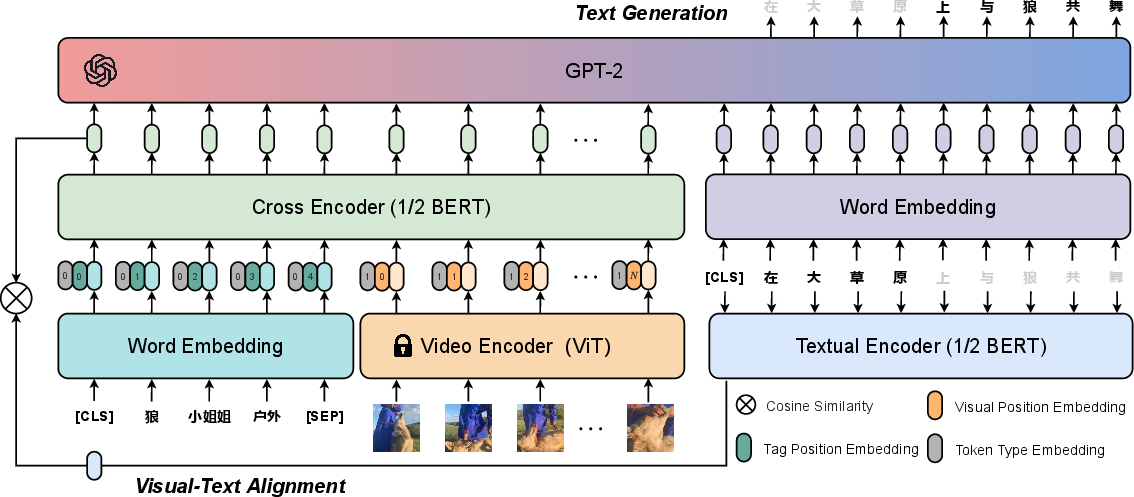
Figure 2: Overall framework of our proposed ALWIG model. ALWIG consists of a tag-driven video-text alignment module and a GPT-based generation module for video titling and retrieval tasks.
The generation module leverages a GPT decoder to facilitate the creation of engaging video titles, ensuring the model captures both semantic and attractive linguistic expressions. This combination of alignment and generation allows ALWIG to outperform traditional methods by integrating multi-modal insights and facilitating high-quality video title generation.
Experimental Evaluation
The paper presents comprehensive experiments that illustrate the superior performance of ALWIG over existing models like UniVL and OSCAR. In video retrieval tasks, ALWIG exhibits improved Recall@K metrics, demonstrating its efficacy in matching video-text pairs. The model's video titling capabilities are particularly noteworthy, highlighted by a significant boost in CIDEr scores, which underscores the model's ability to generate contextually rich and enticing titles. Moreover, the inclusion of tags as anchor points for modal alignment plays a critical role in enhancing both retrieval and generation tasks.
Implications and Future Directions
The establishment of the CREATE benchmark and the introduction of ALWIG pave the way for advancements in video titling and retrieval, particularly in the context of Chinese short videos. By bridging video content with compelling textual descriptions, this work has significant implications for content recommendation systems and search engines. Future research could explore more sophisticated models that further distill semantic nuances and enhance practical applications, such as personalized video content recommendations. Furthermore, the framework's adaptability to other languages and domains represents a promising avenue for expanding its applicability and impact.
Conclusion
The CREATE benchmark and the ALWIG model represent significant advancements in the domain of Chinese short video retrieval and titling. By providing a rich dataset and demonstrating the capabilities of a novel multi-modal learning model, the paper sets a foundation for future research and applications aimed at enhancing video content engagement and discoverability. The work underscores the importance of combining robust data annotation with innovative architectures to drive progress in AI-driven content generation and retrieval.

