- The paper introduces a novel dual-stage system identification process that pre-trains with non-task-specific trajectories and refines policies via Bayesian Optimization for real-world transfer.
- It proposes the Projected Universal Policy to reduce training complexity by mapping high-dimensional dynamics to a lower-dimensional latent space for robust adaptation.
- Results on the Darwin OP2 robot show significant improvements in mobility and balance over baselines, reducing the number of trials and adjustment time required.
Sim-to-Real Transfer for Biped Locomotion
Introduction to Sim-to-Real Transfer
The paper "Sim-to-Real Transfer for Biped Locomotion" (1903.01390) introduces a novel approach to bridge the reality gap in transferring dynamic control policies from simulation to physical robots. The focus is on developing biped locomotion controllers using a two-stage system identification process: pre-training system identification (pre-sysID) and post-training system identification (post-sysID). These stages leverage data-driven insights to approximate model parameters crucial for policy training and refinement. The core innovation is the Projected Universal Policy (PUP), allowing for an efficient modulated policy conditioned on a latent space, which aids in enhancing sim-to-real transfer efficacy.
Methodology: Two-Stage System Identification
Pre-training System Identification
In pre-sysID, model parameters such as friction and center-of-mass are estimated using non-task-specific trajectories. This stage optimizes parameter bounds (μlb and μub) for domain randomization during policy training. The trajectory collection involves standard motion sequences which, although not task-specific, help approximate a wide range of model dynamics critical for robust policy development.
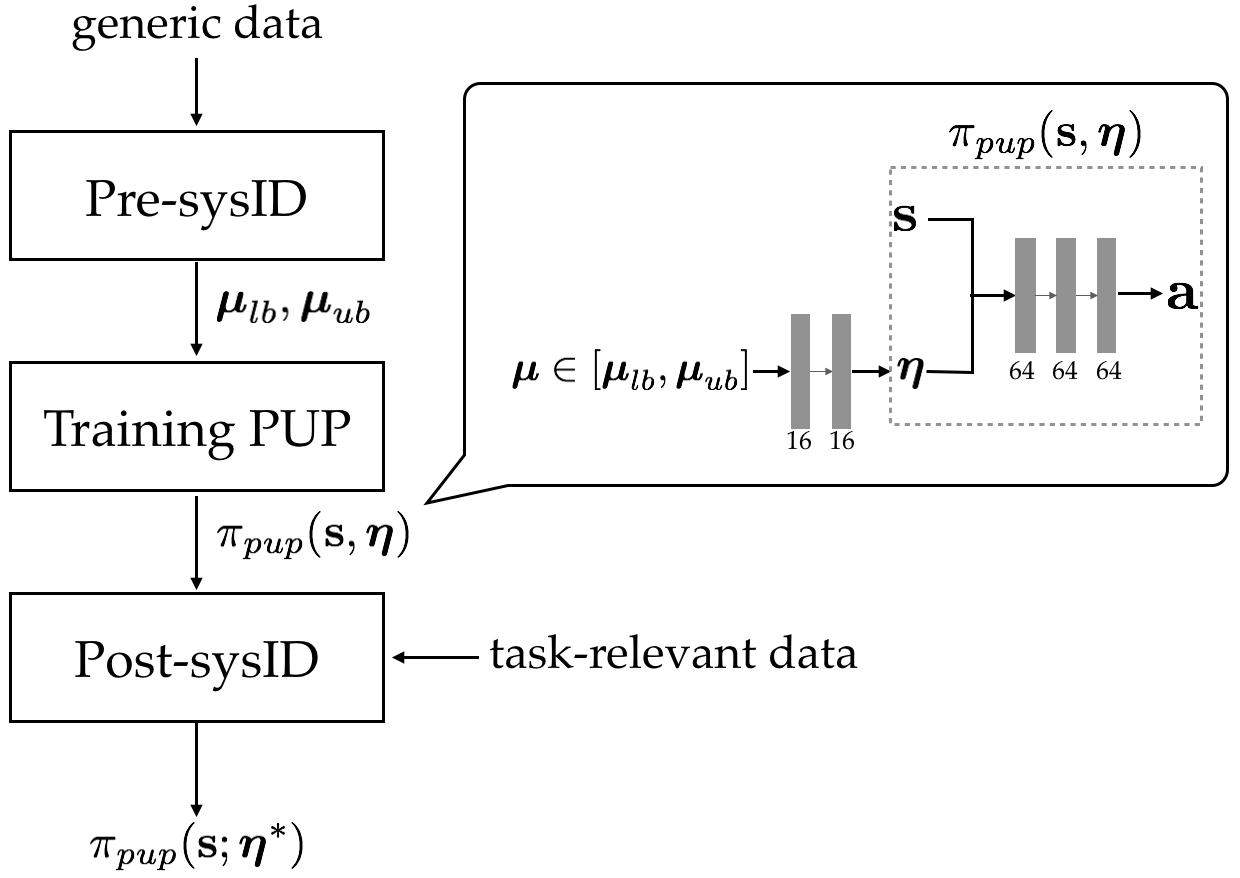
Figure 1: Overview of the proposed algorithm.
Post-training System Identification
Post-sysID utilizes task-relevant data, optimizing the latent variable η that conditions the PUP. This optimization is achieved through Bayesian Optimization, which efficiently searches the parameter space to maximize real-world policy performance, demonstrated by the distance traversed by the robot. This step significantly enhances policy transfer, requiring minimal trials on physical hardware.
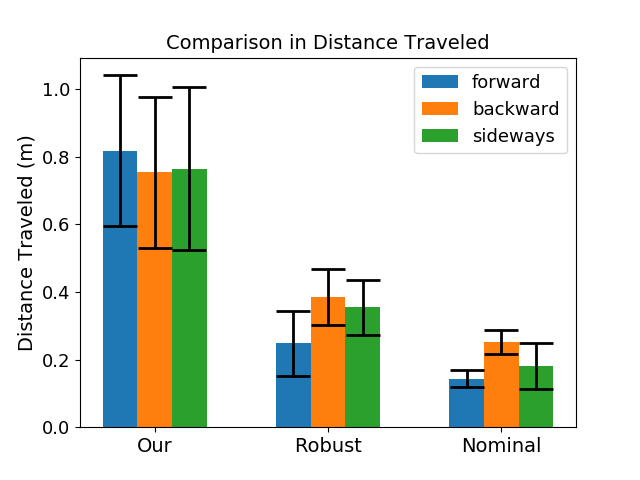
Figure 2: Comparison of the distance travelled by the robot using our method and the baselines.
Projected Universal Policy (PUP)
The PUP is central to modulating policy behavior for different environmental conditions within the identified parameter range. By projecting high-dimensional model parameters μ onto a lower-dimensional latent space η, the training complexity is reduced, enabling effective adaptation across a variety of simulation scenarios. This conditional aspect of PUP exhibits diverse behavioral attributes necessary for agile biped locomotion.
Practical Implications and Results
The methodology is demonstrated on the Darwin OP2 robot, executing various locomotion tasks such as walking forwards, backwards, and sideways. Key performance indicators show substantial enhancement in the sim-to-real transfer, with the robot achieving the desired mobility in fewer trials and less time compared to baseline methods like nominal and robust policy training. The integration of neural network-based PD controllers was crucial in accurately modeling actuator dynamics, thereby improving transfer success.
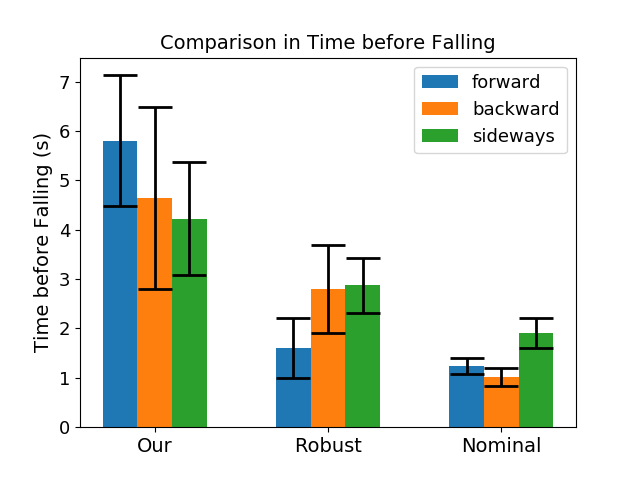
Figure 3: Comparison of the elapsed time before the robot loses balance using our method and baselines.
Implications and Future Directions
The proposed approach not only optimizes locomotion controllers for biped robots but also sets a foundation for extending sim-to-real transfer strategies to other robotic tasks and platforms. The introduction of PUP offers a promising route to tackle varied environmental dynamics and actuator variability without exhaustive manual tuning.
Future research could explore automating the selection of model parameters to generalize the approach across different robots and tasks, such as dexterous manipulation or complex terrain traversal. Developing enhanced models for actuator dynamics and refining projection strategies might further amplify sim-to-real transfer fidelity.
Conclusion
This paper demonstrates a successful transfer learning framework for robotic control policies, emphasizing the sim-to-real transition with improved locomotion performance. The dual-stage identification process offers a compelling advancement in reducing the reality gap, fostering efficient deployment of simulated policies to real-world robotic systems. As the field seeks more adaptable and resilient AI-driven solutions, such methodologies will likely gain prominence in various robotic applications.

