Cross-Session Decoding of Neural Spiking Data via Task-Conditioned Latent Alignment
Abstract: Cross-session nonstationarity in neural activity recorded by implanted electrodes is a major challenge for invasive Brain-computer interfaces (BCIs), as decoders trained on data from one session often fail to generalize to subsequent sessions. This issue is further exacerbated in practice, as retraining or adapting decoders becomes particularly challenging when only limited data are available from a new session. To address this challenge, we propose a Task-Conditioned Latent Alignment framework (TCLA) for cross-session neural decoding. Building upon an autoencoder architecture, TCLA first learns a low-dimensional representation of neural dynamics from a source session with sufficient data. For target sessions with limited data, TCLA then aligns target latent representations to the source in a task-conditioned manner, enabling effective transfer of learned neural dynamics. We evaluate TCLA on the macaque motor and oculomotor center-out dataset. Compared to baseline methods trained solely on target-session data, TCLA consistently improves decoding performance across datasets and decoding settings, with gains in the coefficient of determination of up to 0.386 for y coordinate velocity decoding in a motor dataset. These results suggest that TCLA provides an effective strategy for transferring knowledge from source to target sessions, enabling more robust neural decoding under conditions with limited data.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making brain-computer interfaces (BCIs) work better over time. BCIs read brain signals to figure out what someone is trying to do (like move a cursor). The problem is that brain signals recorded on one day can look different on another day, so a model that works well today might fail tomorrow—especially if you don’t have much new data to retrain it. The authors propose a new method, called Task-Conditioned Latent Alignment (TCLA), to fix that.
What questions were they trying to answer?
- Can we reuse knowledge learned from one recording day (the “source” day) to help decode brain signals on a later day (the “target” day) when we have only a little new data?
- Can we align brain signal patterns across days in a way that respects how the task is done (for example, different movement directions), so that the decoder stays accurate?
How did they do it? (In simple terms)
Think of brain activity like many noisy voices talking at once across lots of microphones (the electrodes). Each day, some microphones might be quieter or louder, or some voices shift—so the recording sounds a bit different. But the overall “tune” of the task (for example, moving toward the top-right) is similar across days.
The authors’ approach has two key ideas:
- Learn a simple “map” of the signals
- They use an autoencoder, a kind of neural network that compresses complex data into a smaller, simpler representation and then tries to reconstruct the original.
- Imagine taking a detailed photo (the raw brain spikes) and shrinking it down to a small sketch that still captures the main shapes (the “latent” representation), then expanding it back. If the sketch is good, it becomes a useful summary of what matters.
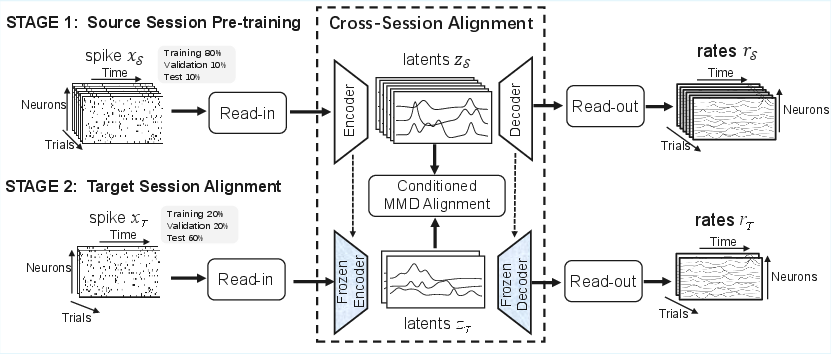
- They train this autoencoder on one day with plenty of data (the source session) so it learns a strong, low-dimensional summary of how the brain signals relate to movements.
- Align new-day signals to that map, per task condition
- On a new day (the target session), they don’t retrain the whole system (because data are limited). Instead, they keep the shared “map” fixed and only adjust small session-specific layers that translate between the new day’s signals and the shared map.
- Crucially, they align signals by task condition—for example, aligning all “move left” trials together and all “move up” trials together—rather than mixing everything. This helps preserve differences that matter for decoding behavior.
- To measure and reduce the mismatch between source and target in the small latent space, they use a statistic called MMD (Maximum Mean Discrepancy). You can think of it like adjusting the new day’s clusters so they overlap with the old day’s clusters for each movement direction.
A few practical details (explained simply):
- “Latent space” = the small, compressed space where the main patterns live.
- “Session-specific layers” = small adapters that translate day-specific signals into the shared latent space.
- “Coordinated dropout” = randomly hiding parts of the input during training so the model learns smooth, general patterns and doesn’t just memorize the data.
- After getting smooth firing-rate estimates from the autoencoder, they train a separate, simple decoder (an LSTM) to predict movement (position or velocity).
What did they find?
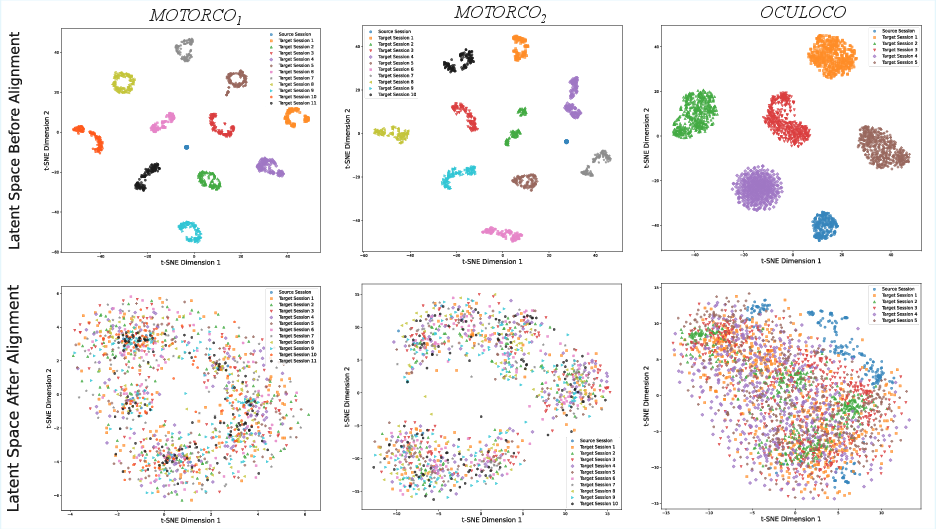
- Better alignment across days: When they looked at the latent space (using a visualization method called t-SNE), signals from different days clustered together by movement direction instead of splitting apart by day. That means the model learned a shared “language” of brain activity that worked across sessions.
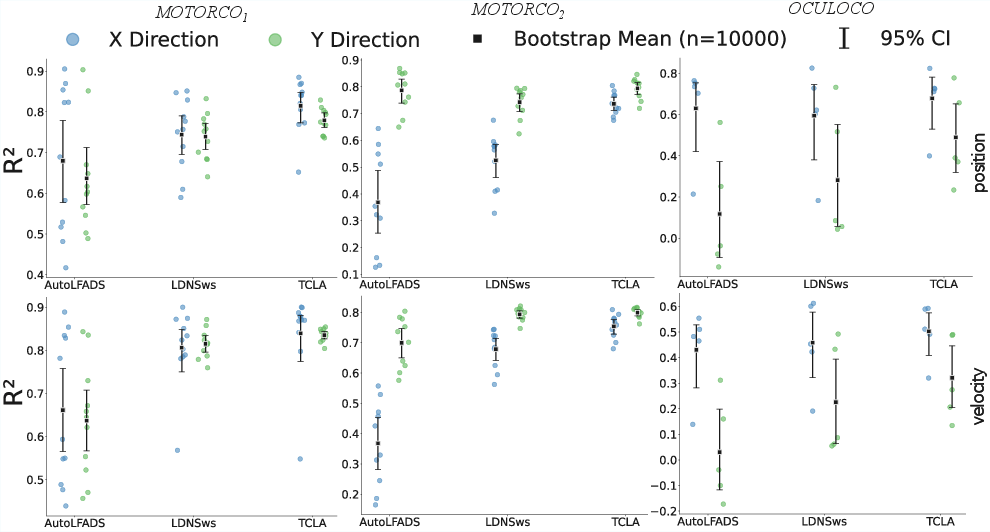
- Higher decoding accuracy with little new data: Across three datasets from monkeys doing “center-out” tasks (moving or looking from the center toward targets around a circle), their method improved how well they could predict movements from brain signals. They measured performance using R² (how well predictions match the real movement), and TCLA gave consistent and sometimes large boosts. In one case, the improvement for velocity in the y-direction reached up to 0.386 in R²—quite a big jump.
- Biggest gains where the baseline was weak: The improvements were strongest for directions or coordinates that were harder to decode to begin with. This matches a common pattern in transfer learning: you benefit most where you were struggling.
Why is this important?
- More stable BCIs over time: People using invasive BCIs shouldn’t need long recalibration sessions every day. TCLA shows a way to reuse yesterday’s knowledge to make today’s decoding better, even with little new data.
- Keeps task structure intact: By aligning “move left” with “move left,” and so on, the method preserves meaningful differences between actions, which helps decoding.
- Practical for real-world use: The approach separates shared knowledge (the stable latent map) from day-specific adapters, making it easier to update just a small part of the system when conditions change.
A simple caveat:
- The method needs task labels (like which movement direction a trial belongs to) to align conditions. If those labels are missing or unclear, extra steps would be needed.
Overall, this work suggests a practical path toward BCIs that stay accurate across days by learning a shared, low-dimensional “language” of brain activity and aligning each new day’s signals to that language in a task-aware way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Reliance on task-condition labels: Develop and evaluate unsupervised or weakly supervised conditional alignment when labels are noisy, ambiguous, or unavailable, including semi-supervised variants and label uncertainty modeling.
- Sensitivity to alignment objective: Compare multi-kernel MMD to alternative alignment objectives (e.g., optimal transport, adversarial/domain-invariant training, contrastive metric learning, conditional normalizing flows) and quantify impacts on decoding.
- Kernel and hyperparameter robustness: Systematically assess sensitivity to the Gaussian kernel bandwidths, number of kernels J, scaling K, and the alignment weight β3; provide tuning guidelines or automatic selection (e.g., median heuristic, cross-validation).
- Sequence-aware alignment: Investigate alignment methods that respect temporal dependencies (e.g., sequence MMD, dynamic time warping, recurrent OT, time-contrastive learning) rather than treating latent samples as i.i.d.
- Source session selection: Quantify how choice of source session affects transfer; design strategies for automatic source selection, multi-source pretraining/aggregation, and detect/mitigate negative transfer under large source–target mismatch.
- Handling label-set mismatch: Extend TCLA to target sessions with missing or novel conditions (e.g., different number of movement directions) via continuous condition embeddings, compositional labels, or zero-shot alignment.
- Class imbalance across conditions: Evaluate alignment robustness under imbalanced per-direction trial counts; introduce reweighting or importance sampling in MMD to counter imbalance.
- Sample efficiency characterization: Vary target-session training sizes (e.g., 5, 10, 25, 50, 100 trials) to establish scaling laws and minimum data requirements for acceptable decoding performance.
- Quantitative alignment metrics: Complement t-SNE with quantitative measures (e.g., domain discrepancy metrics, Fréchet distance, CCA alignment scores, silhouette/domain-cluster overlap) to track alignment quality.
- Decoder dependence: Test a shared decoder trained on source and applied to target via aligned latents (as proposed for future work) versus per-session LSTM; assess end-to-end joint training of decoder with alignment.
- Closed-loop and real-time performance: Evaluate latency, stability, and online adaptation in closed-loop BCI settings; characterize robustness to within-session nonstationarity and drift.
- Task generalization: Validate TCLA on more complex behaviors beyond center-out (e.g., curved reaches, force control, cognitive tasks) and on human intracortical BCI datasets; test across cortical areas.
- Robustness to severe ensemble changes: Stress-test alignment under electrode loss/gain, large channel count changes, re-referencing, and significant manifold drift; map failure modes and recovery strategies.
- Cross-subject transfer: Explore alignment across animals (and potentially across subjects/species), including subject-invariant latent spaces and personalization layers.
- Preprocessing dependence: Assess robustness to bin width (e.g., 2–20 ms), spike sorting versus threshold crossings, smoothing choices, and alternative noise models (Poisson vs. negative binomial/zero-inflated).
- Computational scalability: Profile time/memory for large-session alignment (e.g., >2000 trials); investigate approximate MMD (random Fourier features, Nyström) or subsampling to scale to long recordings.
- Hyperparameter selection protocol: Specify and evaluate tuning procedures for β1/β2 (latent smoothness), coordinated dropout, latent dimension q, and read-in/out layer capacity; analyze generalization across datasets.
- Neurophysiological interpretability: Test whether aligned latents preserve tuning properties (preferred directions, gain, phase), manifold geometry, and across-day stability; quantify alignment-induced distortions.
- Alignment granularity: Move beyond direction-only conditioning to include speed, task epoch (prep/move/hold), or trial phase; evaluate hierarchical/multifactor conditioning schemes.
- Out-of-distribution conditions: Measure performance when target sessions contain conditions not present in source (e.g., unseen directions or speed profiles); evaluate zero-shot and few-shot generalization.
- Baseline comparison breadth: Include head-to-head comparisons with existing manifold alignment methods (e.g., Degenhart 2020; Jude 2022; Karpowicz 2025) under identical low-data splits and statistical protocols.
- Evaluation metrics diversity: Complement R² with NMSE, CCC, temporal alignment error, robustness under synthetic noise/drift; report effect sizes and correct for multiple comparisons across axes/tasks.
- Long-timescale stability: Analyze performance versus inter-session interval (days/weeks/months) to quantify degradation and alignment resilience over extended periods.
- Freezing strategy during adaptation: Test partial unfreezing of the shared encoder with regularization (e.g., EWC, L2-SP, feature distillation) to balance adaptability and stability; compare to full freezing.
- MMD implementation details: Clarify whether MMD operates at trial-level or timepoint-level; evaluate variants (segment-wise, epoch-wise) and their impact on temporal fidelity and decoding.
- Channel-count variability: Quantify how performance scales with channel count changes; ablate the capacity of 1×1 conv read-in/out layers and introduce channel-dropout robustness measures.
- Leveraging LDNS diffusion: Explore using the LDNS diffusion component for data augmentation or generative replay to enhance alignment and decoding under extreme low-data target conditions.
- Overfitting control in target adaptation: Provide diagnostics (learning curves, validation leakage checks) and regularization strategies (weight decay, early stopping, augmentation) specific to low-data targets.
- Practical deployment protocol: Define a calibration workflow (minutes of data, alignment criteria, acceptance thresholds), compute resource requirements, and user-centric performance metrics for clinical BCI use.
Glossary
- AutoLFADS: A latent variable model for inferring firing rates from spiking activity; used here as a baseline trained per session. "AutoLFADS\cite{pandarinath2018inferring}, \cite{keshtkaran2022large}, a widely used latent variable model that infers firing rates from spiking activity and is trained independently on each target session."
- Binned neural spike counts: Spike counts aggregated into fixed-width time bins for analysis. "denotes binned neural spike counts (5 ms window length, non-overlapping)"
- Bootstrap: A resampling method to estimate statistics and uncertainty from data. "We report the bootstrap mean and 95\% confidence intervals (CI) of across target sessions (10,000 resamples)."
- Brain-computer interfaces (BCIs): Systems that translate neural activity into control signals for external devices. "Cross-session nonstationarity in neural activity recorded by implanted electrodes is a major challenge for invasive Brain-computer interfaces (BCIs), as decoders trained on data from one session often fail to generalize to subsequent sessions."
- Center-out task: A behavioral paradigm with movements from a central start to peripheral targets. "Eight-direction motor center-out task."
- Coefficient of determination: The R2 metric quantifying how well predictions match ground truth. "Decoding performance is quantified using the coefficient of determination () between the predicted and the ground-truth behavior."
- Confidence intervals (CI): Intervals indicating uncertainty around an estimated statistic. "We report the bootstrap mean and 95\% confidence intervals (CI) of across target sessions (10,000 resamples)."
- Coordinated dropout: A masking strategy during training that prevents memorization and encourages smooth rate inference. "In both training stages, we use coordinated dropout~\cite{keshtkaran2019enabling} by randomly masking input time bins and computing the loss only at the masked locations."
- Conv1d: One-dimensional convolutional layer used to map session-specific channels to shared embeddings. "session-specific read-in and read-out layers, a pair of 1Ã1 convolutional (Conv1d) layers"
- Diffusion models: Generative models based on iterative denoising/diffusion processes. "While LDNS further applies diffusion models on the latents to generate realistic neural spiking data, we focus solely on the autoencoder module for latent representation learning."
- Firing rates: Continuous-valued estimates of neuronal spiking activity intensity over time. "and reconstructs smoothed firing rates"
- Frontal Eye Fields (FEF): A cortical area involved in the control of eye movements. "Spiking activity was recorded simultaneously from the Frontal Eye Fields (FEF) and Medial Temporal area (MT), together with the corresponding behavioral measurements."
- Gaussian kernel: A radial basis function used in kernel methods to measure similarity. "The kernel function is implemented as a Gaussian kernel,"
- LDNS: A latent diffusion framework for neural spiking data that includes an autoencoder for latent representation learning. "LDNS is a diffusion-based generative framework that employs an autoencoder to project spiking data into latent space."
- Latent space: A low-dimensional representation space capturing essential structure in the data. "aligns neural activity from target sessions into this latent space via a task-conditioned alignment process"
- Latent variable models: Models that infer hidden variables explaining observed data structure. "latent variable models have shown strong potential for capturing low-dimensional neural dynamics and improving decoding performance"
- Long Short-Term Memory (LSTM): A recurrent neural network architecture for sequence modeling. "For each target session, we train a separate downstream Long Short-Term Memory (LSTM) decoder on the inferred firing rates"
- Maximum Mean Discrepancy (MMD): A kernel-based distance between probability distributions used for alignment. "alignment is performed separately for each condition using a multi-kernel Maximum Mean Discrepancy (multi-kernel MMD)"
- Medial Temporal area (MT): A visual cortical area (MT) associated here with recorded spiking activity. "Spiking activity was recorded simultaneously from the Frontal Eye Fields (FEF) and Medial Temporal area (MT), together with the corresponding behavioral measurements."
- Neural manifold: A low-dimensional structure underlying patterns of neural population activity. "population neural activity can exhibit a relatively stable low-dimensional manifold over extended periods"
- Neural population dynamics: The evolving activity patterns across many neurons over time. "The objective is to learn a latent representation that accurately captures neural population dynamics within the source session."
- Nonstationarity: Changes in the statistical properties of neural signals over time or sessions. "Cross-session nonstationarity in neural activity recorded by implanted electrodes is a major challenge"
- Oculomotor: Pertaining to eye movements and their neural control. "We also used an oculomotor center-out dataset (denoted as ) reported in~\cite{noneman2024decoding}."
- Poisson negative log-likelihood: A loss function appropriate for modeling count data such as spikes. "the autoencoder is trained by minimizing the Poisson negative log-likelihood of the source-session spike counts"
- Primary Motor Cortex (M1): A motor cortical area from which arm-movement-related spiking was recorded. "Neural spiking activity was recorded from the Primary Motor Cortex (M1) using a chronically implanted 96-channel Utah array,"
- Read-in layer: A session-specific layer that projects raw spikes into a fixed-dimensional embedding. "For each session, a session-specific read-in layer first projects the raw spiking activity into an embedding with a fixed dimension"
- Read-out layer: A session-specific layer that maps latent representations back to reconstructed firing rates. "The shared decoder and session-specific read-out layers then map the latent representation back to reconstructed smoothed firing rates."
- Task-Conditioned Latent Alignment (TCLA): The proposed framework that aligns latent representations across sessions conditioned on task variables. "we propose a Task-Conditioned Latent Alignment framework (TCLA) for cross-session neural decoding."
- t-distributed Stochastic Neighbor Embedding (t-SNE): A nonlinear dimensionality-reduction technique for visualizing high-dimensional data. "we apply t-distributed Stochastic Neighbor Embedding (t-SNE)\cite{maaten2008visualizing} to latent trajectories inferred from the test sets"
- Utah array: A high-density implanted microelectrode array for recording neuronal activity. "using a chronically implanted 96-channel Utah array"
- Wilcoxon signed-rank test: A nonparametric statistical test for paired comparisons. "mean improvement from 0.033 to 0.386 in , in these cases, Wilcoxon signed-rank test"
Practical Applications
Overview
Below are practical, real-world applications that follow from the paper’s findings, methods, and innovations around Task-Conditioned Latent Alignment (TCLA) for cross-session neural decoding. Each item includes sector linkage, potential tools/workflows, and assumptions/dependencies. Applications are grouped by their deployability timeline.
Immediate Applications
These applications can be piloted or deployed now in research and development settings, and (with appropriate validation) in some preclinical or assistive technology contexts.
- Reduced per-session calibration for invasive BCI decoding — healthcare, assistive technology
- What: Use TCLA’s two-stage pipeline (source pre-training, task-conditioned latent alignment) to cut the amount of target-session data needed to reach acceptable decoding accuracy for motor or oculomotor BCIs.
- Tools/workflows: PyTorch/PyTorch Lightning implementation of the shared LDNS-style autoencoder with session-specific read-in/out layers; multi-kernel MMD alignment per task condition; downstream LSTM or equivalent kinematic decoder; coordinated dropout for robustness.
- Assumptions/dependencies: Requires explicit task-condition labels (e.g., center-out movement/gaze directions); sufficient source-session data; similar task structure across sessions; compatible electrode arrays; offline training resources.
- Day-to-day stability for cursor/gaze control in research BCIs — robotics, software, assistive tech
- What: Improve cross-session consistency for cursor movement and eye-gaze tracking tasks in lab BCIs by aligning latent manifolds per movement direction.
- Tools/workflows: Integrate TCLA into existing decoder training pipelines (AutoLFADS, LFADS-Torch, RNN/LSTM decoders) as a preprocessing step producing session-aligned firing rates.
- Assumptions/dependencies: Stable task paradigms across sessions; Poisson-like spiking assumptions for reconstruction; limited but representative target data.
- Multi-session neural data harmonization in labs — academia, software
- What: Use TCLA to create a unified latent space across days for the same subject and task, enabling better pooling of trials and longitudinal analyses.
- Tools/workflows: Session-specific encoders with a shared latent backbone; visualization dashboards (e.g., t-SNE/UMAP of latents by session/condition); drift monitoring (MMD/latent distance metrics).
- Assumptions/dependencies: Same task taxonomy across sessions; aligned timing/behavioral annotations; consistent preprocessing (binning, smoothing).
- Low-data decoding benchmarking and protocol design — academia, industry R&D
- What: Benchmark how many target-session trials are needed to reach performance thresholds with TCLA vs baselines; design efficient calibration protocols that prioritize underperforming coordinates/conditions.
- Tools/workflows: Bootstrapped R² evaluation across sessions; per-condition alignment quality reports; calibration schedulers suggesting trial allocation by direction.
- Assumptions/dependencies: Access to multi-session datasets; ability to hold out large test splits; reproducible validation splits.
- QA metrics for electrode stability and session drift — medical device industry, quality assurance
- What: Monitor cross-session drift using latent-space MMD and cluster overlap as engineering QA metrics for array stability and recording consistency.
- Tools/workflows: Automated “drift report” pipeline (latent alignment scorecards, cluster compactness/separation); session-comparison dashboards for manufacturing and clinical follow-ups.
- Assumptions/dependencies: Repeated measures under comparable task conditions; stable acquisition parameters.
- Preclinical animal training efficiency — academia
- What: Reduce the number of trials required from non-human primates in center-out tasks by leveraging source sessions to improve decoding in subsequent sessions.
- Tools/workflows: TCLA training schedule that reuses prior sessions; trial budgeting focused on weak directions/coordinates; ethics/compliance reporting of reduced trial burdens.
- Assumptions/dependencies: Comparable animal behavior across days; sufficient source-session quality; ethical oversight approvals.
- Data integration in shared repositories and multi-lab studies — academia, software
- What: Standardize cross-session alignment within shared center-out datasets to enable fair, apples-to-apples comparisons across methods and labs.
- Tools/workflows: Reference TCLA “alignment pack” (configurable read-in/out layers per session; hyperparameter presets for β1–β3, MMD bandwidths); reproducible containerized pipelines (Docker).
- Assumptions/dependencies: Common labeling conventions; shared data formats; agreed preprocessing standards.
- Assistive interface tuning for gaze-based communication — healthcare, accessibility
- What: Apply TCLA to oculomotor tasks (like OCULOCO) to enhance decoding of eye-movement-related variables in gaze-typing/selection systems, particularly on lower-performing axes.
- Tools/workflows: Integration with gaze-based UI decoders; per-direction alignment to stabilize target latents; incremental recalibration using small labeled blocks.
- Assumptions/dependencies: Clear task labels; consistent mapping between neural signals and UI actions; human translation requires feasibility checks.
Long-Term Applications
These applications will likely require further research, scaling, clinical validation, and/or new engineering before routine deployment.
- Real-time, on-device cross-session alignment in closed-loop BCIs — healthcare, robotics, embedded/edge AI
- What: Streamlined, online TCLA alignment to stabilize decoding without retraining the behavioral decoder for each new session (i.e., “fixed decoder” vision from the paper’s future work).
- Tools/products: Firmware integrating lightweight Conv1d read-in/out and fast MMD approximations; streaming inference graph; telemetry for drift alerts; edge-optimized models (quantization, pruning).
- Assumptions/dependencies: Low-latency compute on implant/external processors; reliable task-condition tagging in real-time; robust alignment under distribution shifts; regulatory approval.
- Cross-participant transfer to minimize per-user calibration — healthcare, consumer neurotech
- What: Align target-session latents from new users to a shared source manifold learned across participants for similar tasks, reducing onboarding time.
- Tools/products: Population-level latent “banks”; meta-learning for session-specific read-in/out initialization; federated training across users/sites.
- Assumptions/dependencies: Partial manifold similarity across individuals; privacy-preserving aggregation; broader validation across humans.
- Label-free/semi-supervised alignment for naturalistic tasks — academia, software, healthcare
- What: Remove dependence on explicit task-condition labels by using unsupervised domain adaptation (e.g., clustering, contrastive learning) to create pseudo-conditions for alignment.
- Tools/workflows: Self-supervised latent grouping; temporal-structure priors; cross-session adversarial alignment modules.
- Assumptions/dependencies: Discoverable condition structure; robustness to mislabeled or missing trial annotations; additional model complexity.
- Extension to complex behaviors (speech, locomotion, multi-effector control) — healthcare, robotics
- What: Generalize TCLA to tasks with overlapping/continuous conditions, compositional actions, and high-dimensional kinematics.
- Tools/workflows: Hierarchical or conditional latent models; multi-label or continuous-condition alignment (kernel choices beyond Gaussian); hybrid decoders (transformers, Kalman-RNN hybrids).
- Assumptions/dependencies: Adequate source data for diverse conditions; careful kernel/bandwidth selection; evaluation on richer datasets.
- Synthetic trial generation for low-data sessions via integration with generative latents — academia, industry R&D
- What: Combine TCLA’s aligned latents with generative modules (e.g., LDNS diffusion) to augment limited target-session data, improving decoder training.
- Tools/workflows: Conditional generative pipelines; synthetic-to-real validation; data augmentation benchmarks.
- Assumptions/dependencies: High-fidelity generative models capturing task-conditioned dynamics; safeguards against overfitting to synthetic distributions.
- Clinical workflow standardization and regulatory guidance — policy, healthcare
- What: Establish standards for reporting cross-session generalization, calibration time, and drift metrics in BCI trials; define acceptance tests for decoder stability under limited calibration.
- Tools/products: Consensus metrics (R² across axes, MMD drift scores, label coverage); documentation templates; compliance checklists.
- Assumptions/dependencies: Multi-stakeholder agreement (clinicians, regulators, manufacturers); longitudinal human studies.
- Personalized neurorehabilitation and neuromodulation tuning — healthcare
- What: Track patient-specific latent manifolds across visits to adjust therapy parameters (e.g., adaptive DBS, cortical stimulation) using stable, task-conditioned neural features.
- Tools/workflows: Visit-to-visit alignment dashboards; closed-loop parameter search guided by latent drift; integration with clinical decision support.
- Assumptions/dependencies: Demonstrated clinically relevant correlates in human datasets; safe integration with therapeutic devices.
- Robust prosthetic limb control over months — robotics, healthcare
- What: Maintain reliable decoding for motor BCIs controlling robotic limbs with minimal retraining using aligned latents and condition-aware adaptation.
- Tools/products: Prosthetic control software embedding TCLA; auto-calibration routines triggered by drift thresholds; user feedback loops.
- Assumptions/dependencies: Long-term implant stability; coverage of relevant movement conditions; human subject trials.
- MLOps/SDKs for multi-session neural decoding — software, industry
- What: Commercial toolkits that package session-specific adapters, shared latent encoders, per-condition alignment, and evaluation suites for BCI developers.
- Tools/products: TCLA SDKs (APIs for read-in/out layer generation, MMD alignment, drift monitoring), CI/CD pipelines with unit/integration tests for neural decoding.
- Assumptions/dependencies: Market demand; ongoing maintenance and support; compatibility with heterogeneous datasets and hardware.
- Interoperability and data-sharing policy for BCI research — policy, academia
- What: Promote common task label taxonomies, timing conventions, and preprocessing schemas to facilitate cross-session alignment across labs and datasets.
- Tools/workflows: Open standards; dataset validators; reference benchmarks for center-out and beyond.
- Assumptions/dependencies: Community adoption; funding for standards bodies; incentives for compliance.
- Human-centered UX improvements for assistive BCIs — daily life, healthcare
- What: Less frequent and shorter recalibration sessions, more predictable performance across days, and adaptive UI behaviors responding to drift alerts.
- Tools/products: End-user calibration wizards; notification systems for performance dips; personalized alignment profiles.
- Assumptions/dependencies: Human validation; accessible interfaces; data privacy protections.
Notes on Cross-Cutting Assumptions and Dependencies
- Task-conditioned alignment requires clear, accurate condition labels; ambiguity or label absence limits immediate applicability.
- Source-target similarity (same task structure, comparable recording sites/hardware) is critical; large domain shifts may reduce transfer benefits.
- Sufficient source-session data is needed to learn a robust latent manifold; extremely small source datasets may underfit.
- Current evidence is from non-human primate datasets; human clinical validation and real-time performance need further study.
- Compute considerations (training and, eventually, on-device inference) constrain real-time deployment; model compression and efficient kernels may be necessary.
- Ethical, privacy, and regulatory issues (especially in clinical applications) will shape feasibility and timelines.
Collections
Sign up for free to add this paper to one or more collections.