- The paper introduces BrainDistill, a novel pipeline combining a custom lightweight transformer-based neural decoder with task-specific knowledge distillation for implantable BCI motor decoding.
- It employs a supervised projection method to compress teacher embeddings into a task-relevant space, yielding superior performance over traditional distillation techniques.
- Quantization-aware training enables 8-bit inference, ensuring low power consumption while maintaining high decoding accuracy in implantable devices.
Task-Specific Knowledge Distillation for Implantable Motor Decoding
Introduction
The paper "BrainDistill: Implantable Motor Decoding with Task-Specific Knowledge Distillation" (2601.17625) introduces BrainDistill, an integrated pipeline targeting efficient, high-performance brain-computer interface (BCI) motor decoding deployable under the power, memory, and computational constraints of implantable devices. BrainDistill couples a lightweight implantable neural decoder (IND) with a Task-Specific Knowledge Distillation (TSKD) method. This approach addresses the widely recognized challenge that state-of-the-art transformer-based neural decoders, although highly accurate for neural signal decoding, are intractable for on-chip deployment due to their size and energy requirements. The architecture is also augmented with an integer-only quantization-aware training scheme to further facilitate clinical translation and silicon implementation.
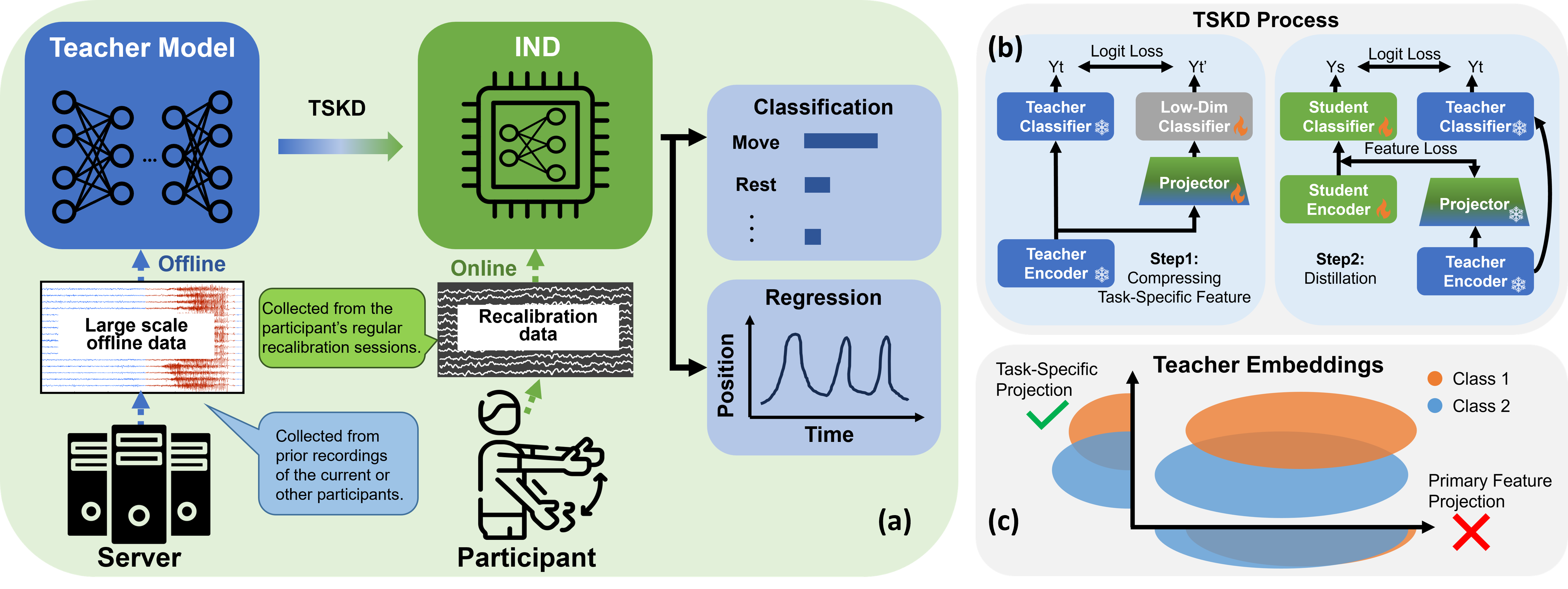
Figure 1: The BrainDistill pipeline, integrating a compact neural decoder with task-specific knowledge distillation via supervised projection and efficient online motor decoding.
BrainDistill Pipeline
The BrainDistill system is composed of two principal components: (1) a custom lightweight transformer-based neural decoder (IND) and (2) a distillation strategy (TSKD) optimized for BCI applications.
The IND architecture operates by transforming raw neural data into task-relevant embeddings. Features are tokenized using continuous wavelet transforms (CWT), and subsequently processed with linear attention layers specifically crafted for quantization compatibility and low memory usage.
The TSKD protocol proceeds in two stages:
- Supervised Projection: Teacher embeddings—learned from a large, pre-trained neural model—are compressed into a lower-dimensional, task-specific space using a supervised projector, targeting only those features with highest importance for decoding.
- Student Alignment: The IND (student) aligns its representations to the projected teacher space, explicitly minimizing a task-centric distillation loss.
This design addresses the core limitation of standard feature- or logit-matching distillation protocols, which degrade when severe model capacity disparities exist and calibration data are scarce. TSKD intentionally ignores extraneous teacher information not relevant to decoding, yielding superior distillation efficacy and stability.
Quantitative and Qualitative Evaluation
BrainDistill is extensively benchmarked on ECoG data from both human (Human-D, Human-C) and non-human primate (Monkey-R) datasets, as well as cross-modal EEG (BCIC-2A, BCIC-2B) and spike (FALCON-M1) datasets. Two paradigms are evaluated: direct training ("Scratch") and distillation from foundation models ("Distillation").
Key results include:
- The compact IND (≈30K parameters) achieves higher intra- and inter-session classification performance than significantly larger neural decoders and outperforms large transformer foundation models when equipped with TSKD in few-shot scenarios.
- TSKD outperforms logit-based, feature-based, and prior task-oriented KD methods (e.g., KD, SimKD, VkD, RdimKD, TOFD, TED), achieving top F1 and average recall on Human-C inter-session splits.
- When tested on regression tasks (Monkey-R trajectory decoding), IND exhibits superior R2 relative to both classical and neural network baselines across 7 longitudinal sessions.
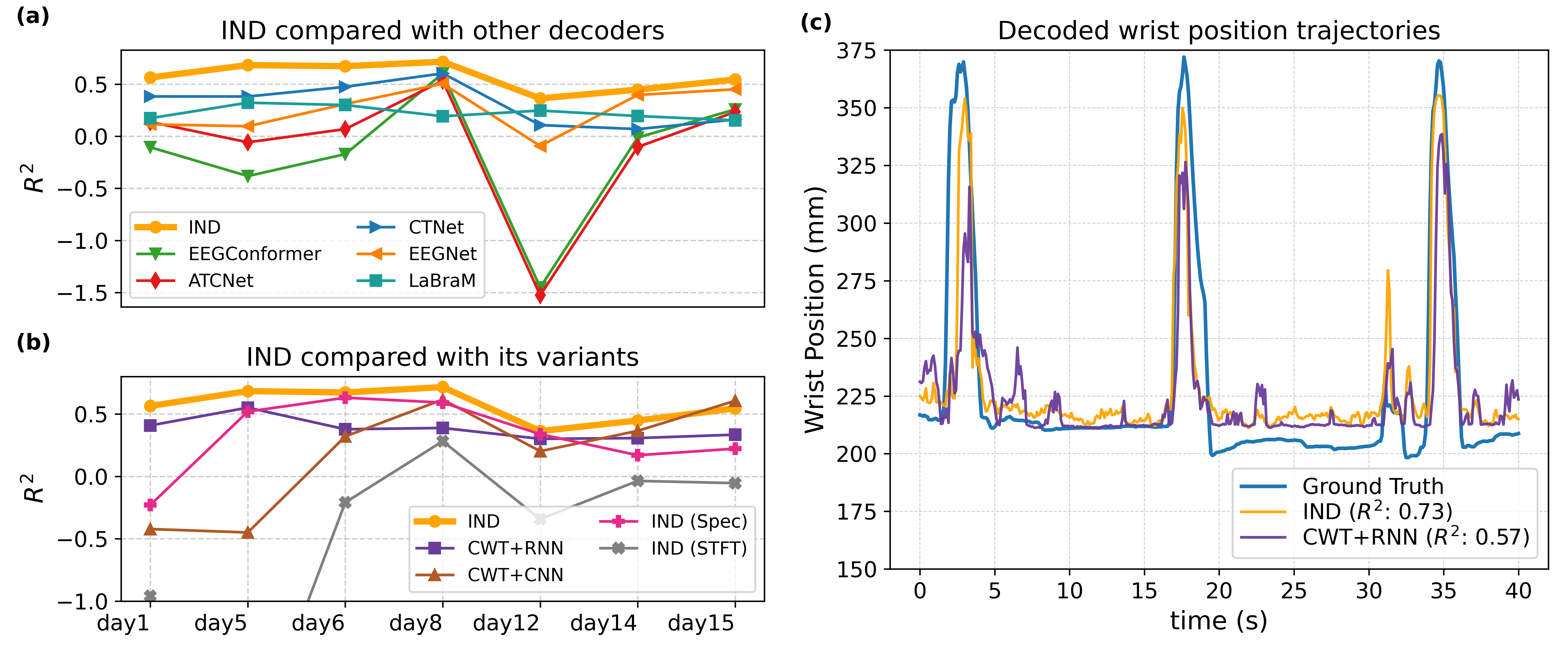
Figure 2: R2 values for IND and baselines on Monkey-R, with ablation on input features and model components.
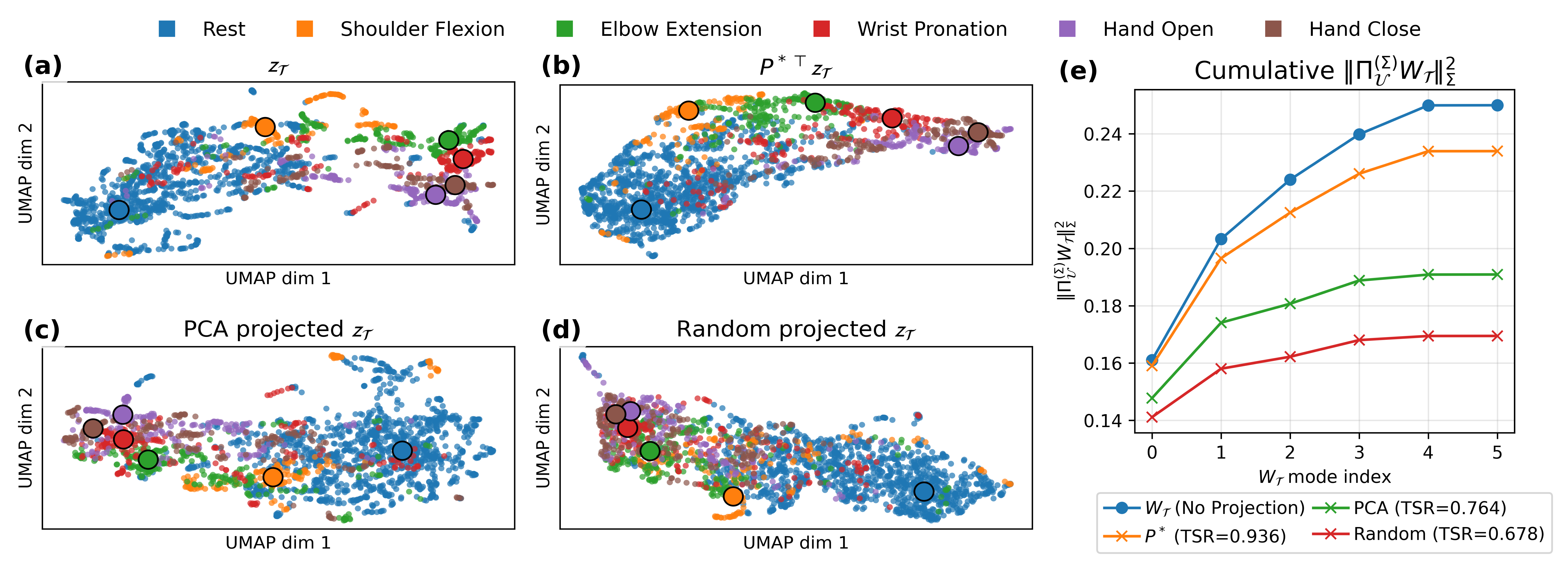
Figure 3: UMAP visualization of teacher and projected embeddings on Human-C, comparing TSKD to PCA and random projections in terms of class structure preservation and task-relevant separability.
Task-Specific Projection (TSP) within TSKD is validated both visually and quantitatively: the supervised projector yields substantially more separable class structures as compared to unsupervised (PCA, random) projections, and cumulative task-specific energy retention aligns with higher decoding accuracy.
Task-Specific Ratio (TSR): Evaluation Metric
To systematically evaluate projection methods driving distillation efficacy, the Task-Specific Ratio (TSR) is introduced. This metric quantifies the fraction of task-relevant information preserved after projector application, formalized as the proportion of teacher classifier energy captured in the projected student space—directly influencing lower bounds of distillation performance. Empirical results show a >0.9 Pearson correlation between TSR and downstream accuracy, outperforming alternative metrics (mutual information, reconstruction error) which do not predict task performance.
Quantization-Aware and On-Chip Feasibility
The IND architecture is tailored for integer-only inference through quantization-aware training (QAT), with learnable activation clipping inspired by advances such as PACT. All activations and weights are quantized to 8 bits, simulating 10 bits for input signal. The QAT procedure co-optimizes parameters and clipping ranges using a straight-through estimator for gradient computation. Compared to I-ViT, the quantized IND achieves power draws under 6 mW (versus 23 mW floating point), well below clinical implant safety thresholds, with <3% reduction in performance.
Modal and Model Generality
TSKD generalizes effectively across modalities (ECoG, EEG, spikes) and model backbones. It consistently yields accuracy increases in few-shot distillation settings across BCIC-2A, BCIC-2B, FALCON-M1, and when used with alternative transformer decoders (ATCNet, CTNet, EEGConformer). In all ablation and modality generalization studies, TSKD outperforms or matches non-task-specific distillation methods.
Implications and Future Developments
Practically, BrainDistill demonstrates the feasibility of deploying high-performing transformer-based neural decoders within the stringent constraints of implantable BCI devices, closing a significant translational gap. The explicit concentration on task-specific knowledge transfer provides a robust paradigm for future neural decoding, reducing calibration duration and facilitating rapid adaptation to non-stationarities and inter-subject variability.
Theoretically, the introduction of the TSR as a projection quality criterion and the formulation of TSKD suggest broader utility in settings requiring capacity-bridged, objective-driven knowledge transfer. These methodologies could be further adapted for other sensorimotor, cognitive, or clinical neural decoding applications and ported to the optimization of closed-loop neural prostheses.
Anticipated future AI developments include direct adaptation of this knowledge distillation pipeline for unsupervised or semi-supervised transfer, auto-selection of task-relevant embedding subspaces via neural architecture search, and integration with neuromorphic substrates for ultra-low-power on-device learning and inference.
Conclusion
BrainDistill advances the state of implantable motor decoding through the integration of a lightweight, transformer-based neural decoder and a rigorously task-specific knowledge distillation protocol. With its quantization-aware design, hardware-awareness, and robust empirical superiority over a broad spectrum of neural decoding benchmarks and KD methods, BrainDistill substantiates a practical and theoretically sound path toward next-generation BCI deployment.