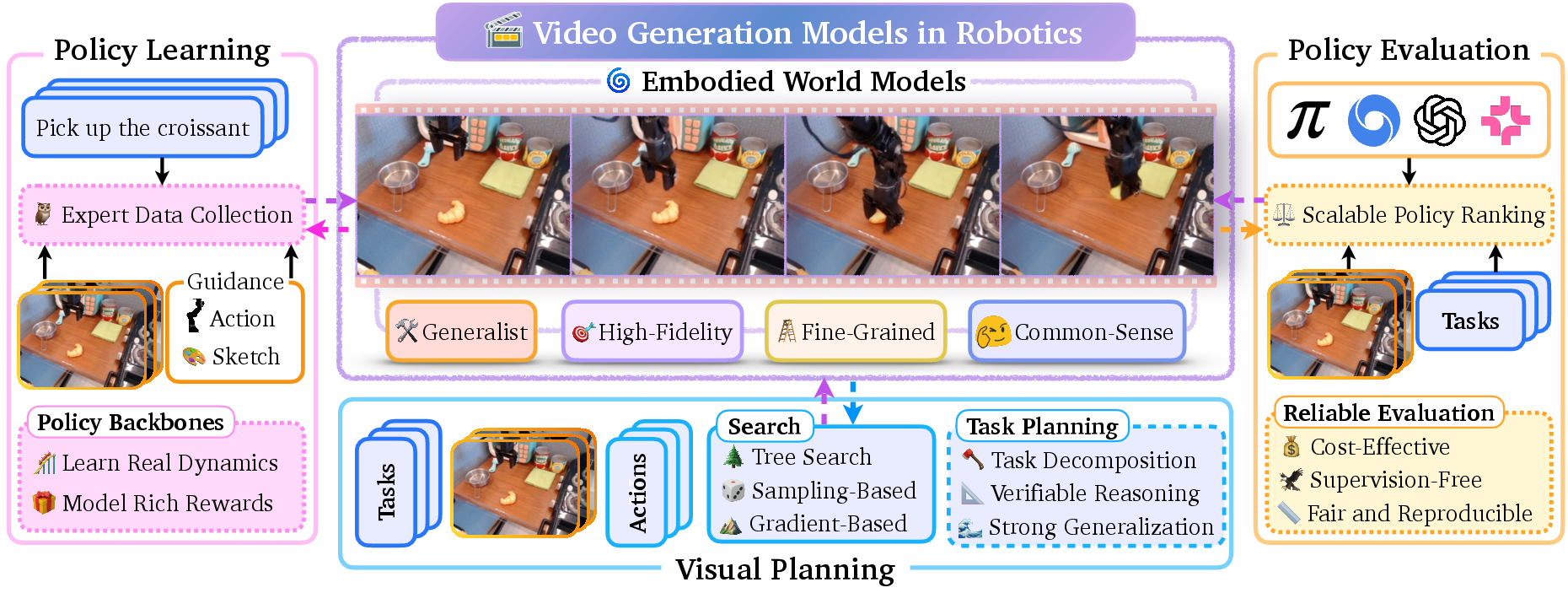
Video Generation Models in Robotics -- Applications, Research Challenges, Future Directions
Abstract: Video generation models have emerged as high-fidelity models of the physical world, capable of synthesizing high-quality videos capturing fine-grained interactions between agents and their environments conditioned on multi-modal user inputs. Their impressive capabilities address many of the long-standing challenges faced by physics-based simulators, driving broad adoption in many problem domains, e.g., robotics. For example, video models enable photorealistic, physically consistent deformable-body simulation without making prohibitive simplifying assumptions, which is a major bottleneck in physics-based simulation. Moreover, video models can serve as foundation world models that capture the dynamics of the world in a fine-grained and expressive way. They thus overcome the limited expressiveness of language-only abstractions in describing intricate physical interactions. In this survey, we provide a review of video models and their applications as embodied world models in robotics, encompassing cost-effective data generation and action prediction in imitation learning, dynamics and rewards modeling in reinforcement learning, visual planning, and policy evaluation. Further, we highlight important challenges hindering the trustworthy integration of video models in robotics, which include poor instruction following, hallucinations such as violations of physics, and unsafe content generation, in addition to fundamental limitations such as significant data curation, training, and inference costs. We present potential future directions to address these open research challenges to motivate research and ultimately facilitate broader applications, especially in safety-critical settings.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is a friendly “tour guide” to a new kind of AI tool for robots: video generation models. These models can create realistic, short videos that look like the real world and show how things move and interact. The paper explains what these models are, how they work, how robots can use them, what problems still exist, and where the field is headed.
Think of these models as super-realistic daydreams a robot can run in its head. Instead of only using math-based simulators that can struggle with messy real-world details (like floppy cloth or squishy food), video models can imagine what will happen next in a scene with lifelike visuals and motion.
What questions does the paper ask?
The paper focuses on simple but important questions:
- What are video generation models, and how do they differ from older robot simulators?
- How can robots use these models to learn and plan actions?
- What do these models do really well, and where do they fail?
- What needs to improve so robots can safely and reliably use them in the real world?
How do the researchers approach it?
This is a survey paper, which means the authors review and explain many recent research papers rather than running one big experiment. They:
- Describe two big families of world models: older “state-based” models and newer “video-based” models.
- Explain popular video model techniques (especially “diffusion” and “flow-matching,” the current best methods for making high-quality videos).
- Show how these models are being used in robotics: making training data, predicting future outcomes, planning actions, and testing robot programs.
- Summarize common problems and suggest future directions.
What is a “world model”?
A world model is like the robot’s internal mental model of how the world works:
- State-based world models: These predict what happens next using compact, hidden numbers (latents) instead of full images. They’re efficient but can miss fine details.
- Video world models: These predict the next frames of a video directly, capturing appearance and motion. They’re more expressive and can show tricky interactions (like folding a towel), but they’re heavier to run.
How do diffusion video models work (in plain terms)?
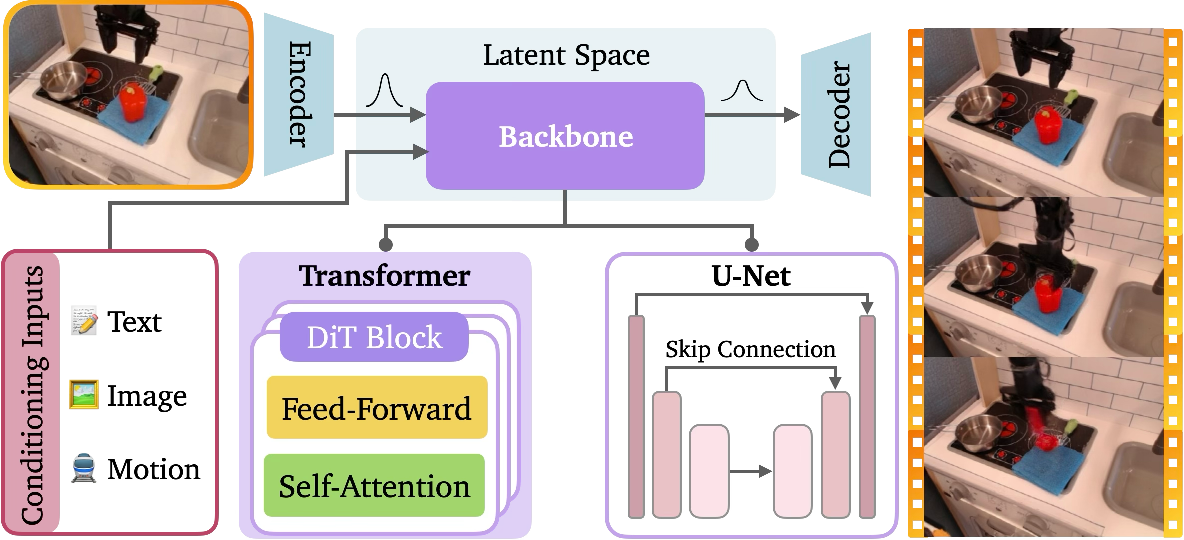
Imagine you add “static” noise to a picture over and over until it’s pure noise. A diffusion model learns the reverse: starting from noise, it removes the static step by step to rebuild a realistic image or video. By guiding this process with instructions (like a text prompt or a starting image), the model can generate a video that matches what you asked for.
- Why this helps: Step-by-step denoising is stable and surprisingly good at creating sharp, consistent visuals over time.
- How models take instructions: They can be guided by text, images, robot actions, motion paths, or other signals so the output video follows your goal.
What did they find, and why is it important?
The authors highlight four major ways video models help robots:
- Cost-effective training data (Imitation Learning)
- Robots need lots of examples to learn. Filming and labeling real demos is expensive.
- Video models can generate many realistic “how to” examples, including both successes and failures, which helps robots learn what to do and what to avoid.
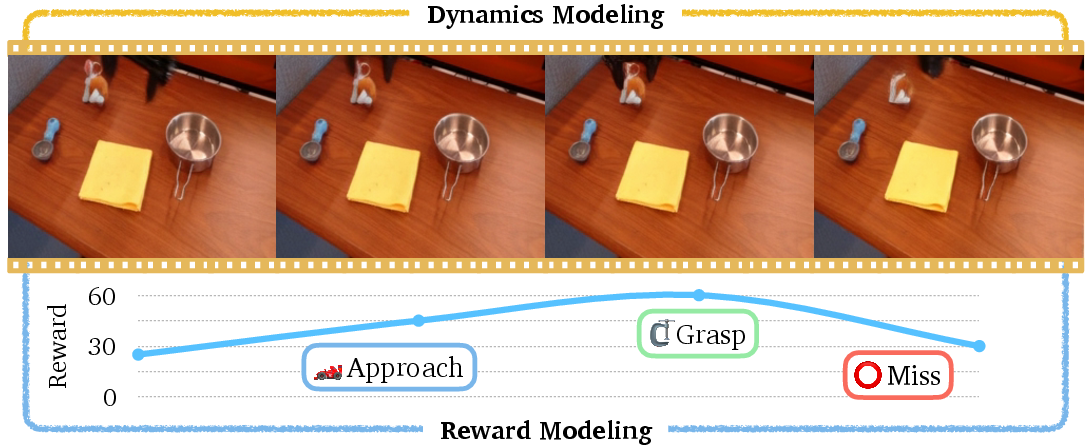
- Better learning of cause and effect (Reinforcement Learning)
- Robots need to predict “If I do this, what happens next?” Video models can forecast future frames and estimate rewards, helping robots learn by imagining instead of constantly testing in the real world.
- Safer, cheaper testing (Policy Evaluation)
- Instead of testing a new robot skill on a real robot (which can be risky and costly), you can first “play it out” in a high-fidelity generated video world to catch problems early.
- Visual planning
- Robots can “see” different possible futures as short videos and pick the one that looks best for the task (for example, planning a path that avoids spills or collisions).
Why this matters:
- Video models can handle complex, real-world visuals (like reflections, soft objects, and clutter) better than many physics simulators.
- They can reduce the “simulation-to-reality gap,” making it more likely that strategies learned in simulation work in the real world.
- They enable “generalist” robot skills that work across many tasks using one unified approach.
What are the main challenges?
Even though video models are powerful, there are important issues to fix:
- Hallucinations and physics mistakes
- Sometimes objects appear, disappear, pass through each other, or move in impossible ways. That’s dangerous if a robot trusts these videos.
- Weak instruction following, especially in long videos
- Over long sequences, the model may drift off task, ignore steps, or forget constraints.
- Uncertainty and trust
- Models rarely say “I’m not sure,” which makes it hard to know when not to trust them.
- Safety and content concerns
- Guardrails to prevent harmful or inappropriate content are still developing, and robots need strong safety checks to avoid risky actions.
- High costs
- Curating training data, training huge models, and running them quickly enough can be expensive and energy-hungry.
- Evaluation is hard
- It’s tricky to score how “good” a generated video is, and even harder to judge whether it’s useful for robot learning and safe deployment.
What does this mean for the future?
If these challenges are addressed, video world models could become a core tool for robotics:
- More reliable and safe robots
- By combining better physics understanding, strong safety filters, and uncertainty estimates, robots can make safer choices.
- Faster, cheaper development
- Generate training data at scale and test policies virtually before touching a real robot arm.
- Smarter planning and generalist skills
- Visual planning and better world understanding could help one robot handle many tasks, adapt to new settings, and follow complex, multi-step instructions.
The authors encourage research on:
- Physics-aware training and checks to prevent impossible motions
- Stronger instruction-following over long time spans
- Uncertainty quantification (so models can say “I don’t know”)
- Safer content generation and safe robot behavior filters
- Better benchmarks and metrics that reflect real-world robot needs
- More efficient training and faster inference to cut costs
In short: video generation models let robots “imagine” the future in rich detail. With better reliability and safety, they could make robot learning faster, cheaper, and more capable in the real world.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of concrete gaps the paper leaves unresolved, framed to be directly actionable for future research:
- Standardized physics-consistency criteria: Define quantitative, automated metrics (e.g., conservation laws, contact realism, object permanence) to detect and score physics violations in generated videos, and validate their correlation with downstream robot failures.
- Training-time physics enforcement: Develop methods that embed differentiable physics, hard constraints, or conservation priors into diffusion/flow-matching training without degrading visual fidelity; characterize the trade-offs and failure modes.
- Instruction-following at long horizons: Create benchmarks and protocols for temporally extended, compositional, multi-step instructions in robotics contexts, including metrics for adherence over minutes-long sequences and recovery from partial deviations.
- Calibrated uncertainty for decision-making: Design video-model UQ that is well-calibrated at the level of pixels, objects, and action-conditioned rollouts; demonstrate how to integrate these uncertainties into POMDP/RL planners and quantify safety benefits.
- External validity of policy evaluation: Establish statistical studies linking performance in video-generated “worlds” to real-world robot success, including calibration curves, confidence intervals, and conditions under which evaluation is trustworthy.
- Reward extraction from video: Create robust, transferable methods to infer reward signals directly from generated or real videos (including preference-based approaches), and quantify susceptibility to reward hacking or mis-specification.
- Action estimation and cross-embodiment retargeting: Develop general algorithms to infer continuous control commands from generated video trajectories and retarget them safely across robot morphologies, with guarantees on feasibility and constraint satisfaction.
- Bridging visual planning to feasible control: Formalize pipelines that convert planned visual trajectories into executable, dynamically feasible robot motions under kinematic, collision, and safety constraints; prove feasibility or provide certificates.
- Long-duration video memory and identity tracking: Architectures and training regimes that maintain object identity, causal consistency, and scene memory across long sequences; evaluate object permanence and causal coherence at scale.
- Robotics-specific datasets: Curate open, high-quality robotics video datasets with action labels, contact events, deformable-object interactions, safety incidents, and physics annotations; include clear licensing, provenance, and metadata standards.
- Cost–fidelity–latency trade-offs: Systematically characterize how model size, compression/distillation, token sparsification, and streaming inference affect fidelity, physics consistency, and real-time performance on edge robot hardware.
- Safety guardrails tailored to robotics: Build and evaluate content-safety policies that block or reshape unsafe generations (and unsafe prompts) with measurable false positive/negative rates; integrate guardrails into closed-loop policy learning.
- Benchmarks tied to downstream utility: Develop robotics-specific metrics that predict task success (not just FVD/CLIP scores), including instruction adherence, physics plausibility, and UQ calibration, and standardize cross-lab evaluation protocols.
- Robustness under distribution shift: Evaluate and harden video models against adversarial prompts, occlusions, fast camera motion, lighting changes, rare objects, and domain shifts; quantify robustness and propose mitigation strategies.
- Multimodal world modeling beyond vision: Integrate tactile, force, proprioception, and audio with video generation; study alignment across modalities and how multimodal signals improve control, physics fidelity, and safety.
- Causal fidelity and intervention testing: Create tests and training objectives that enforce causal relationships (e.g., interventions/counterfactuals), and measure whether generated rollouts respect causal structure relevant to robot control.
- Multi-agent and human–robot interaction modeling: Extend video models to social settings with humans and other agents, including norms, affordances, and safety constraints; provide tasks, datasets, and evaluation protocols.
- Real-time closed-loop use in control: Demonstrate video-model use in MPC/planning with strict latency budgets; design asynchronous/streaming rollouts and quantify how prediction delays affect safety and performance.
- Interpretability and failure prediction: Develop tools for per-frame risk scoring, hallucination detection, and feature-level explanations to debug video models before deployment; tie interpretability signals to actionable safeguards.
- Governance and legal aspects of synthetic data: Establish guidelines for provenance, copyright, consent, and responsible use when training robot policies on generated videos; assess legal risks and propose auditing frameworks.
Practical Applications
Immediate Applications
The following applications can be deployed with current video generation models, given standard integration effort and prudent safeguards.
- Synthetic robot demonstrations for imitation learning (manufacturing, logistics, service robotics)
- Tools/products/workflows: Text-/video-conditioned generators (e.g., DreamGen- or Genie-style pipelines) produce task demonstrations; motion retargeting maps video motions to robot kinematics; human-in-the-loop vetting for quality control.
- Assumptions/dependencies: Sufficient visual fidelity and task correctness; reliable motion retargeting/calibration; domain-specific fine-tuning; content safety filtering to avoid unsafe sequences and biases.
- Action-prediction backbones in vision-language-action policies (software, robotics)
- Tools/products/workflows: Use video models as embodied world backbones inside VLA architectures to improve temporal/spatial grounding; integrate with existing training stacks that scale on internet/video datasets.
- Assumptions/dependencies: High-quality, diverse training data; compute budgets for training/finetuning; compatibility with downstream control heads.
- Policy evaluation via video world models (robotics QA, operations)
- Tools/products/workflows: Offline A/B testing of policies in “WorldGym”-like environments; use CTRL-style evaluation to probe edge cases; generate varied scenarios (lighting, clutter, object types) at low cost.
- Assumptions/dependencies: Measurable alignment between video-model predictions and real-world outcomes; calibrated uncertainty estimates; benchmark-driven acceptance criteria.
- Failure trajectory synthesis for robustness (robotics QA/safety)
- Tools/products/workflows: Generate “near-miss” and failure videos to augment training, teaching corrective behaviors and recovery strategies; create failure libraries for stress testing.
- Assumptions/dependencies: Accurate failure labeling; safeguards to prevent learning undesirable shortcuts; balance of success/failure samples to avoid bias.
- Visual planning for short-horizon manipulation with rigid objects (industrial automation, warehouses)
- Tools/products/workflows: FLIP and Video-Language Planning pipelines compute pixel-space trajectories from prompts and partial observations; operator uses plan previews before execution.
- Assumptions/dependencies: Strong instruction following at short horizons; limited deformable-body complexity; integration with low-level controllers.
- Model-based RL training with video dynamics/reward predictors (warehousing, drones in controlled spaces)
- Tools/products/workflows: Replace or augment physics engines with video dynamics models for sample-efficient RL; combine reward prediction with data augmentation to reduce real-world trials.
- Assumptions/dependencies: Reward prediction accuracy; domain finetuning; manageable training/inference costs; monitoring for physics violations/hallucinations.
- Teleoperation rehearsal and preview (field robotics, inspection)
- Tools/products/workflows: Operators preview predicted video rollouts under candidate actions; adjust plans to reduce risk and time-on-task; archive rollouts for training and documentation.
- Assumptions/dependencies: Low-latency inference; robust action-conditioning; operator training to interpret model uncertainty.
- Education and workforce training content (education, enterprise training)
- Tools/products/workflows: Generate step-by-step videos that visualize tasks, safety procedures, and best practices; embed into LMS platforms.
- Assumptions/dependencies: Content safety policies; clear separation between illustrative content and operational ground truth.
- Benchmarking and internal standards adoption (industry, academia, policy)
- Tools/products/workflows: Use VBench, EvalCrafter, WorldModelBench, WorldSimBench for capability and safety evaluations; define procurement KPIs and “pass thresholds” for deployment.
- Assumptions/dependencies: Metrics reflect target domain requirements; periodic re-validation; transparent reporting of failure cases.
- Safety guardrails in data and training pipelines (compliance, risk management)
- Tools/products/workflows: Integrate safety filters (e.g., SafeWatch-/T2V-SafetyBench-inspired checks) to screen generated videos; add latent safety filters for interaction constraints.
- Assumptions/dependencies: Clear safety taxonomies; organization-wide thresholds; incident response processes for detected violations.
Long-Term Applications
These applications require advances in instruction following, long-horizon coherence, physics fidelity, uncertainty calibration, and/or scaling efficiency.
- Generalist robot policies from video foundation world models (consumer/home/service robotics)
- Tools/products/workflows: Unified, instruction-conditioned policies that leverage video world modeling for multi-task execution; multimodal planning and memory across long durations.
- Assumptions/dependencies: Reliable long video generation; robust instruction following; on-device/edge inference; comprehensive household/task coverage datasets.
- Photorealistic deformable-body simulation for training and planning (healthcare, textiles/retail, laundry automation)
- Tools/products/workflows: Use video models as deformable simulators (cloth, soft tissue) to train manipulation and surgical policies; integrate with motion retargeting and UQ for safety.
- Assumptions/dependencies: Physics-aware generation with few violations; calibrated uncertainty and fail-safes; domain-specific annotation and regulatory acceptance (e.g., surgical).
- Autonomous driving planning and validation via video world models (transportation, regulation)
- Tools/products/workflows: Scenario generation for rare events; pre-certification testing suites for policy evaluation at scale; regulator dashboards tracking benchmark performance.
- Assumptions/dependencies: Public acceptance and standards; rigorous coverage and corner-case modeling; transparent error auditing and explainability.
- World-model-native simulators and digital twins (manufacturing, energy)
- Tools/products/workflows: Replace or fuse physics engines with video-world simulators; build factory/plant “twins” for continuous training, scheduling, and maintenance planning.
- Assumptions/dependencies: Training/inference cost reductions; scalable data curation; hybrid simulators that enforce critical physical constraints; MLOps integration.
- Risk-aware autonomy with calibrated uncertainty in control loops (safety-critical robotics)
- Tools/products/workflows: Latent safety filters and uncertainty-aware planners that modulate aggressiveness; runtime fail-safe triggers; certification artifacts for safety audits.
- Assumptions/dependencies: Reliable UQ and calibration; provable guarantees for critical tasks; performance under distribution shift.
- Instruction-following visual planners for multi-step workflows and long horizons (hospital logistics, household task orchestration)
- Tools/products/workflows: Trajectory- and memory-conditioned planners that decompose tasks and monitor progress; operator-in-the-loop correction tools.
- Assumptions/dependencies: Long-horizon generation stability; robust task decomposition; safe recovery behaviors.
- Synthetic data marketplaces and governance (software platforms, policy)
- Tools/products/workflows: Curated repositories of synthetic demonstrations/failures; licensing, provenance tracking, and auditing; third-party certification of safety and quality.
- Assumptions/dependencies: Clear IP frameworks for synthetic content; cross-industry safety standards; incentives for high-quality curation.
- Human–robot collaborative programming via text→video→action (enterprise automation)
- Tools/products/workflows: Interactive co-pilots that visualize candidate behavior and translate approved sequences into executable plans; versioning of visual “programs.”
- Assumptions/dependencies: Strong alignment across modalities; fine-grained control interfaces; operator training; rollback mechanisms.
- Real-time, on-edge video world modeling (mobile robotics, AR/XR)
- Tools/products/workflows: Distilled/accelerated models on specialized hardware; continuous foresight for navigation/manipulation; AR overlays of predicted outcomes.
- Assumptions/dependencies: Hardware acceleration; energy efficiency; robust performance under streaming inputs and occlusions.
- Safety and interaction governance frameworks (policy/regulators)
- Tools/products/workflows: Sector-specific standards mandating benchmark passes, UQ reports, and red-team testing; incident disclosures; periodic re-certification.
- Assumptions/dependencies: Multi-stakeholder consensus; traceable evaluation pipelines; international harmonization of requirements.
Glossary
- AdaLN: Adaptive layer normalization technique that modulates normalization parameters using conditioning signals. "adaptive normalization methods such as AdaLN or FiLM \cite{perez2017filmvisualreasoninggeneral, xu2019understandingimprovinglayernormalization} modulate the scale and shift parameters of normalization layers using a global conditioning vector"
- Adaptive normalization: Methods that adjust normalization layers (e.g., scale and shift) based on conditioning inputs. "adaptive normalization methods such as AdaLN or FiLM \cite{perez2017filmvisualreasoninggeneral, xu2019understandingimprovinglayernormalization} modulate the scale and shift parameters of normalization layers using a global conditioning vector"
- Autoregressive transformer: A transformer that predicts sequential tokens step-by-step to generate videos. "autoregressive transformers \cite{wu2024ivideogpt, yan2021videogptvideogenerationusing} for higher-fidelity video generation"
- Channel concatenation: Conditioning method that appends input channels to features, enforcing spatial alignment with outputs. "Channel concatenation augments the inputs or latent representations along the channel dimension, which is most effective when the conditioning signal is spatially aligned with the target output, such as in image-to-video generation, depth guidance, or pose conditioning"
- Classifier-based guidance: Conditioning approach that uses a separate classifier on noisy samples to steer diffusion outputs. "Classifier-based guidance~\cite{dhariwal2021diffusion} trains an external classifier that learns to predict an attribute (label) from a noisy sample "
- Classifier-free guidance: Conditioning approach that blends conditional and unconditional model outputs to control generation strength. "Classifier-free guidance~\citep{ho2022classifier} addresses these challenges by training a joint conditional and unconditional model"
- Codebook: A discrete set of latent codes used by VQ-VAEs to represent compressed features. "Vector-quantized variational autoencoders (VQ-VAEs) \cite{van2017neural} address this issue by quantizing the latent representations into discrete codes in a codebook"
- Cross-attention: Mechanism that aligns query features with conditioning keys/values to inject semantic control. "cross-attention captures interactions between intermediate video features (queries) and the conditioning signal (keys and values)~\citep{liu2024understandingcrossselfattentionstable}"
- Deformable-body simulation: Modeling and predicting the behavior of non-rigid objects in physical interactions. "photorealistic, physically consistent deformable-body simulation without making prohibitive simplifying assumptions"
- DINO features: Self-supervised visual features used as alternative latent representations. "Other alternative latent representations can also be used, e.g., DINO features~\citep{baldassarre2025back}"
- Diffusion models: Generative models that synthesize data via iterative denoising from noise. "Diffusion models \cite{ho2020denoising} have gained prominence as a powerful formulation for generative models that synthesize data by modeling an iterative denoising process"
- Diffusion Transformer (DiT): Transformer backbone specialized for diffusion, operating on tokenized patches with attention. "diffusion transformers (DiTs) or U-Nets to learn important interpendencies across space and time within a compact latent space"
- FiLM: Feature-wise linear modulation method that conditions normalization layers via learned scale and shift. "adaptive normalization methods such as AdaLN or FiLM \cite{perez2017filmvisualreasoninggeneral, xu2019understandingimprovinglayernormalization} modulate the scale and shift parameters of normalization layers using a global conditioning vector"
- Flow-matching: Generative modeling framework that learns continuous flows to map noise to data. "flow-matching~\citep{lipman2023flowmatchinggenerativemodeling}"
- Gaussian Splatting: Scene reconstruction technique that represents geometry with Gaussian primitives. "scene reconstruction models, e.g., Gaussian Splatting"
- GroupNorm: Normalization layer that normalizes over groups of channels; often replaced for temporal caching. "VQ-VAEs replace GroupNorm operations with RMSNorm operations for temporal feature caching \cite{wan2025wan, agarwal2025cosmos}"
- Hallucinations: Model outputs that are unrealistic or violate physical laws. "Like LLMs, video models tend to hallucinate, generating videos that are physically unrealistic, e.g., with objects appearing/disappearing or deforming in ways that violate physics~\citep{motamed2025generative, bansal2024videophy, meng2024towards, mei2025confident}"
- Kullback-Leibler (KL) divergence: A measure of distributional difference used as a training loss. "using the mean-squared error (MSE) loss function~\cite{zhou2024dino, alonso2024diffusion} or the Kullback-Leibler (KL) divergence loss~\cite{hafner2023mastering}"
- Latent action model: A control module that operates in latent space to drive frame-by-frame video generation. "Genie~\citep{bruce2024genie} trains a controllable video model using a VQ-VAE and a latent action model for frame-by-frame control"
- Latent collapse: Failure mode where the model ignores or underuses latent variables. "introduce the challenge of latent collapse, where the learned model fails to efficiently use the latent space"
- Latent diffusion: Strategy that performs diffusion in a compressed latent space rather than pixel space. "recent approaches adopt a latent diffusion paradigm, where observations are first compressed into a lower-dimensional latent space using a variational autoencoder (VAE)~\citep{rombach2022high, blattmann2023stable, kong2024hunyuanvideo, wan2025wan, agarwal2025cosmos} prior to the diffusion process"
- Markovian state-based world models: Models assuming the next state depends only on current state and action. "Markovian state-based world models assume that the future evolution of the agent's environment only depends on the agent's state at the current time step and its action "
- Mean-squared error (MSE): Common regression loss used to train predictive models. "using the mean-squared error (MSE) loss function~\cite{zhou2024dino, alonso2024diffusion}"
- Motion retargeting: Transferring motion patterns from generated trajectories to robot actuators. "directly applied to a robot through motion retargeting~\citep{ajay2023compositional, xu2025vilp, ko2023learning}"
- Noise schedule: The sequence of noise magnitudes applied during the forward diffusion process. "under some noise schedule "
- Positional encodings: Token embeddings carrying spatial position information in transformers. "embedded as tokens with positional encodings to preserve spatial relationships"
- Posterior: The conditional distribution in the reverse diffusion step that is approximated by the model. "approximates the true posterior "
- Proprioception: Internal sensing of a robot’s state (e.g., joint angles, velocities). "which could include its RGB observations, proprioception, or latent embeddings"
- Recurrent state-space models (RSSMs): Recurrent architectures modeling latent dynamics over time. "recurrent state-space models (RSSMs)"
- RMSNorm: Root-mean-square normalization layer used for stable temporal feature caching. "VQ-VAEs replace GroupNorm operations with RMSNorm operations for temporal feature caching \cite{wan2025wan, agarwal2025cosmos}"
- Sim-to-real gap: Performance difference between simulation and the real world due to modeling approximations. "these approximations often contribute to the sim-to-real gap in robotics, impeding successful transfer of simulation-trained robot policies to the real-world"
- Temporal compression: Reducing temporal token counts to make video diffusion more efficient. "perform temporal compression, substantially reducing token counts and thereby improving overall generation efficiency"
- Temporal causality: Ensuring that generated frames respect causal ordering over time. "To enforce temporal causality, VQ-VAEs replace GroupNorm operations with RMSNorm operations for temporal feature caching"
- U-Net architecture: Encoder–decoder convolutional backbone with skip connections used in diffusion. "The U-Net architecture \cite{ronneberger2015u, cciccek20163d} has become a foundational backbone for a wide range of vision tasks, including diffusion modeling"
- Variational autoencoder (VAE): Generative model that learns a latent distribution for reconstruction and sampling. "using a variational autoencoder (VAE)~\citep{rombach2022high, blattmann2023stable, kong2024hunyuanvideo, wan2025wan, agarwal2025cosmos}"
- Vector-quantized variational autoencoders (VQ-VAEs): VAEs with discrete latent codebooks to prevent collapse and enable compression. "Vector-quantized variational autoencoders (VQ-VAEs) \cite{van2017neural} address this issue by quantizing the latent representations into discrete codes in a codebook"
- Velocity-based parameterization: Training formulation that predicts velocity instead of noise for stability and speed. "Alternatively, the loss function can be expressed using a velocity-based parameterization~\citep{salimans2022progressivedistillationfastsampling} for better numerical stability and faster convergence"
- Vision-LLMs (VLMs): Multimodal models that process visual and textual inputs to enable reasoning and control. "The advent of large vision-LLMs (VLMs/LLMs)~\citep{guo2025deepseek, OpenAI_GPT5_2025, Hassabis_Kavukcuoglu_Gemini3} has significantly transformed the state of the art in many problem domains"
Collections
Sign up for free to add this paper to one or more collections.

