World Simulation with Video Foundation Models for Physical AI
Abstract: We introduce [Cosmos-Predict2.5], the latest generation of the Cosmos World Foundation Models for Physical AI. Built on a flow-based architecture, [Cosmos-Predict2.5] unifies Text2World, Image2World, and Video2World generation in a single model and leverages [Cosmos-Reason1], a Physical AI vision-LLM, to provide richer text grounding and finer control of world simulation. Trained on 200M curated video clips and refined with reinforcement learning-based post-training, [Cosmos-Predict2.5] achieves substantial improvements over [Cosmos-Predict1] in video quality and instruction alignment, with models released at 2B and 14B scales. These capabilities enable more reliable synthetic data generation, policy evaluation, and closed-loop simulation for robotics and autonomous systems. We further extend the family with [Cosmos-Transfer2.5], a control-net style framework for Sim2Real and Real2Real world translation. Despite being 3.5$\times$ smaller than [Cosmos-Transfer1], it delivers higher fidelity and robust long-horizon video generation. Together, these advances establish [Cosmos-Predict2.5] and [Cosmos-Transfer2.5] as versatile tools for scaling embodied intelligence. To accelerate research and deployment in Physical AI, we release source code, pretrained checkpoints, and curated benchmarks under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-predict2.5 and https://github.com/nvidia-cosmos/cosmos-transfer2.5. We hope these open resources lower the barrier to adoption and foster innovation in building the next generation of embodied intelligence.



































































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to “imagine” realistic worlds on video so robots and self-driving cars can practice safely before acting in the real world. The authors built a new video world model called Cosmos-Predict2.5 that can create short, high-quality videos from:
- text (Text2World),
- a single image (Image2World), or
- a short video (Video2World).
They also built Cosmos-Transfer2.5, which can “translate” one kind of video into another (for example, turn a rough simulation or a map-like sketch into a photorealistic, multi-camera driving scene). Together, these models help train, test, and improve Physical AI—robots and other systems that sense and act in the real world—more safely and cheaply.
What the paper is trying to find out
In simple terms, the researchers wanted to answer:
- Can we build one powerful video model that takes text, images, or videos and reliably produces realistic, physics-aware video worlds?
- Can we make the model understand instructions better, so what you ask for is exactly what it shows?
- Can this help robots, cars, and other Physical AI systems learn faster and more safely, using synthetic (fake but realistic) videos instead of risky real-world trials?
- Can we keep videos sharp, consistent across many camera views, and stable over longer time spans?
- Can we make the model faster and smaller without losing quality?
How they did it (the approach)
To make the explanation clearer, here’s the approach in everyday language:
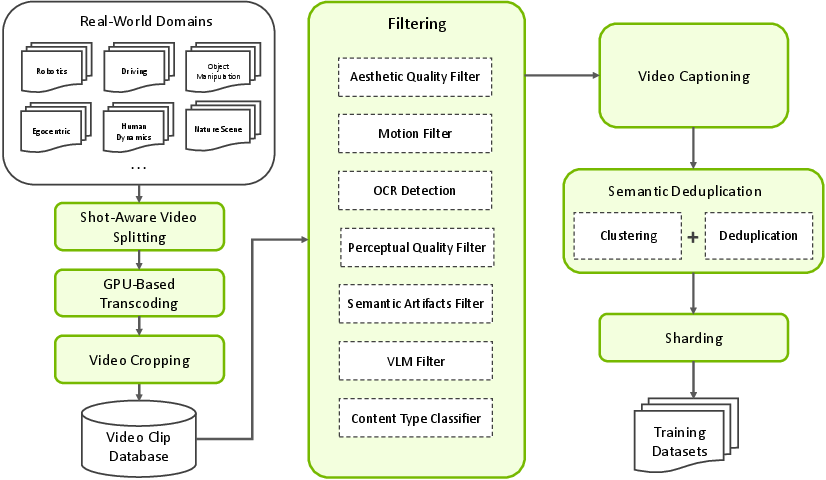
1) Build a massive, clean video library
They processed over 35 million hours of raw video and kept around 200 million high-quality clips (5–60 seconds each). Imagine cleaning your photo library, but at internet-scale:
- They split long videos into meaningful chunks.
- They removed shaky, blurry, overlaid-text, or repeated clips.
- They grouped similar videos and kept the best version.
- They asked a vision-LLM (a smart captioner) to write helpful descriptions at different lengths (short, medium, long).
- They organized everything by type (driving, robots, people, nature, etc.), size, and shape so training would be efficient and balanced.
They also collected special data for key domains like robotics, self-driving, factories/warehouses (smart spaces), human motion, and physics (e.g., collision, flowing water), with customized captions that focus on the details that matter.
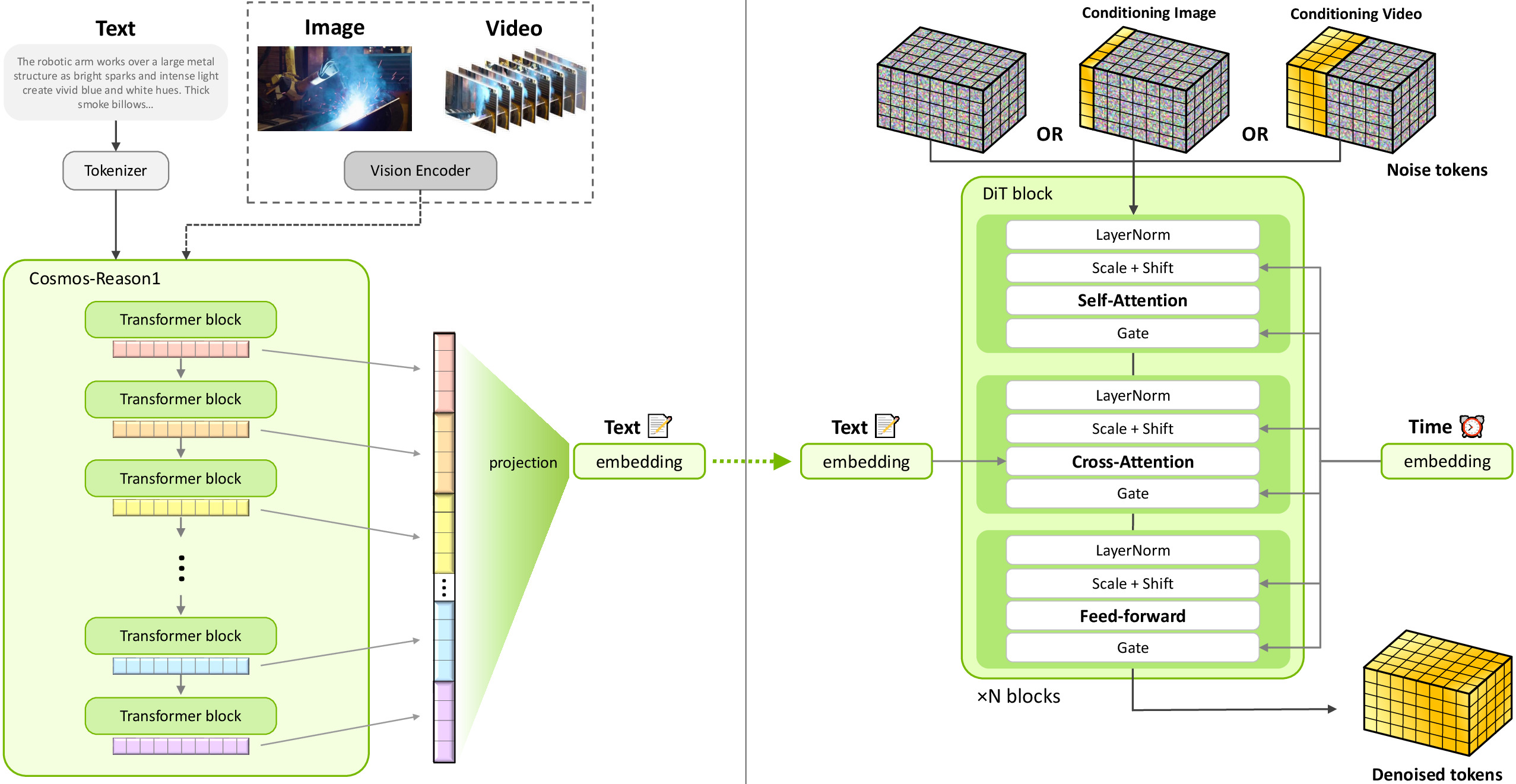
2) Train a “world imagination” model with flow matching
Traditional “diffusion” models learn to turn noise into an image or video step by step. This new model uses a close cousin called flow matching. Think of it like teaching the model not just where to go, but how fast to move from random noise toward a clear picture. This tends to make learning smoother and outputs better.
Key ideas:
- The model learns the “velocity” from noisy frames to clean frames (like learning the direction and speed to un-blur).
- It uses a smart video compressor (a VAE) to work in a compact “latent” space, so it can handle long, high-res videos without running out of memory.
- It uses a strong text-and-vision helper model (Cosmos-Reason1) to better understand instructions and ground the video in what the words mean.
3) Make it work for text, images, or videos in one model
One unified model does:
- Text2World: “A robot stacking red blocks on a table”
- Image2World: “Continue this scene into a moving video”
- Video2World: “Continue or transform this short clip into a longer, coherent video”
For image/video inputs, the model “locks in” the first frames so motion stays consistent and details don’t drift.
4) Improve with fine-tuning, model merging, and reinforcement learning
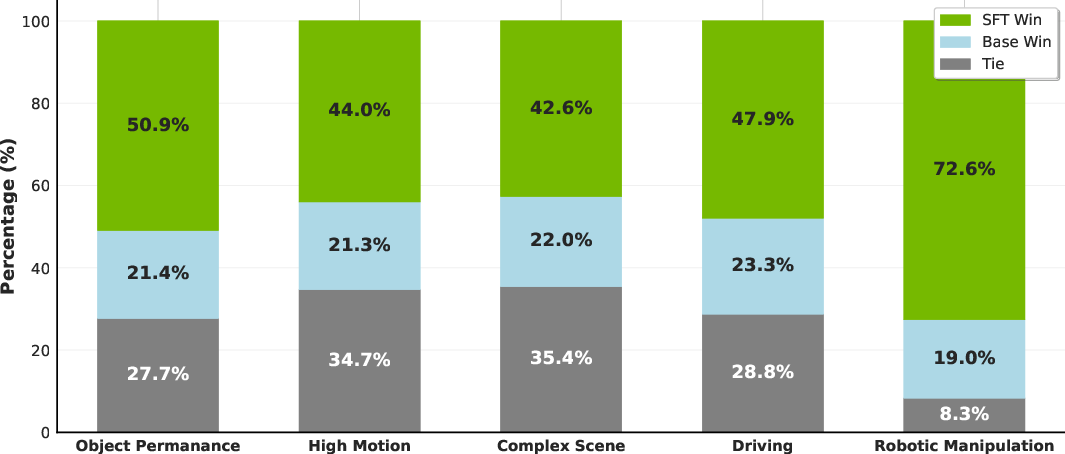
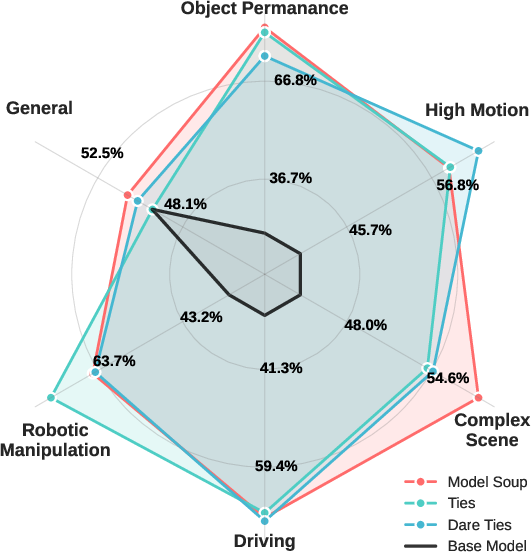
- Supervised fine-tuning: They trained specialized versions for robots, driving, fast motion, complex scenes, and object permanence, then combined (“merged”) them into one model that keeps each specialty’s strengths.
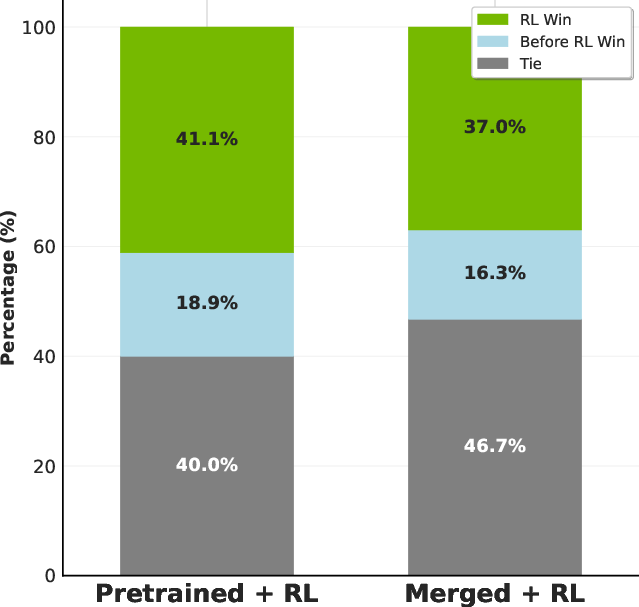
- Reinforcement learning (RL): They used an automated “judge” (VideoAlign) that scores how well a generated video matches the text, has good motion, and looks nice. The model then learns to please this judge—like a coach giving feedback—raising both the judge’s scores and human preference in tests.
- Distillation for speed: They taught a faster “student” model to mimic the slower “teacher,” cutting the number of steps needed to generate a video (as few as 4 steps) while keeping quality similar.
5) Add a “world translator” model family
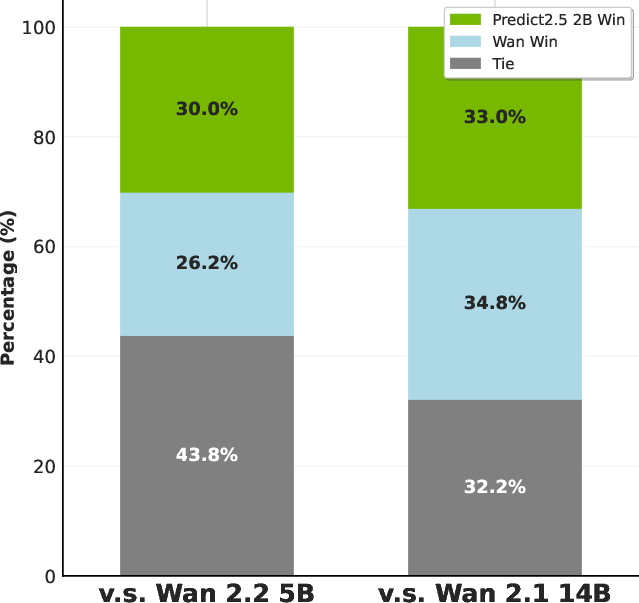
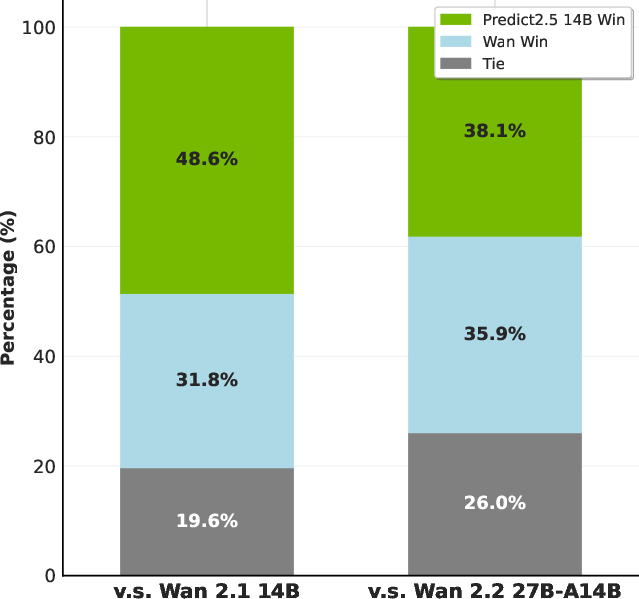
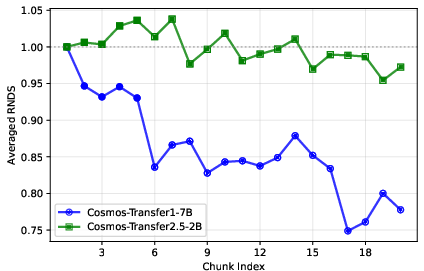
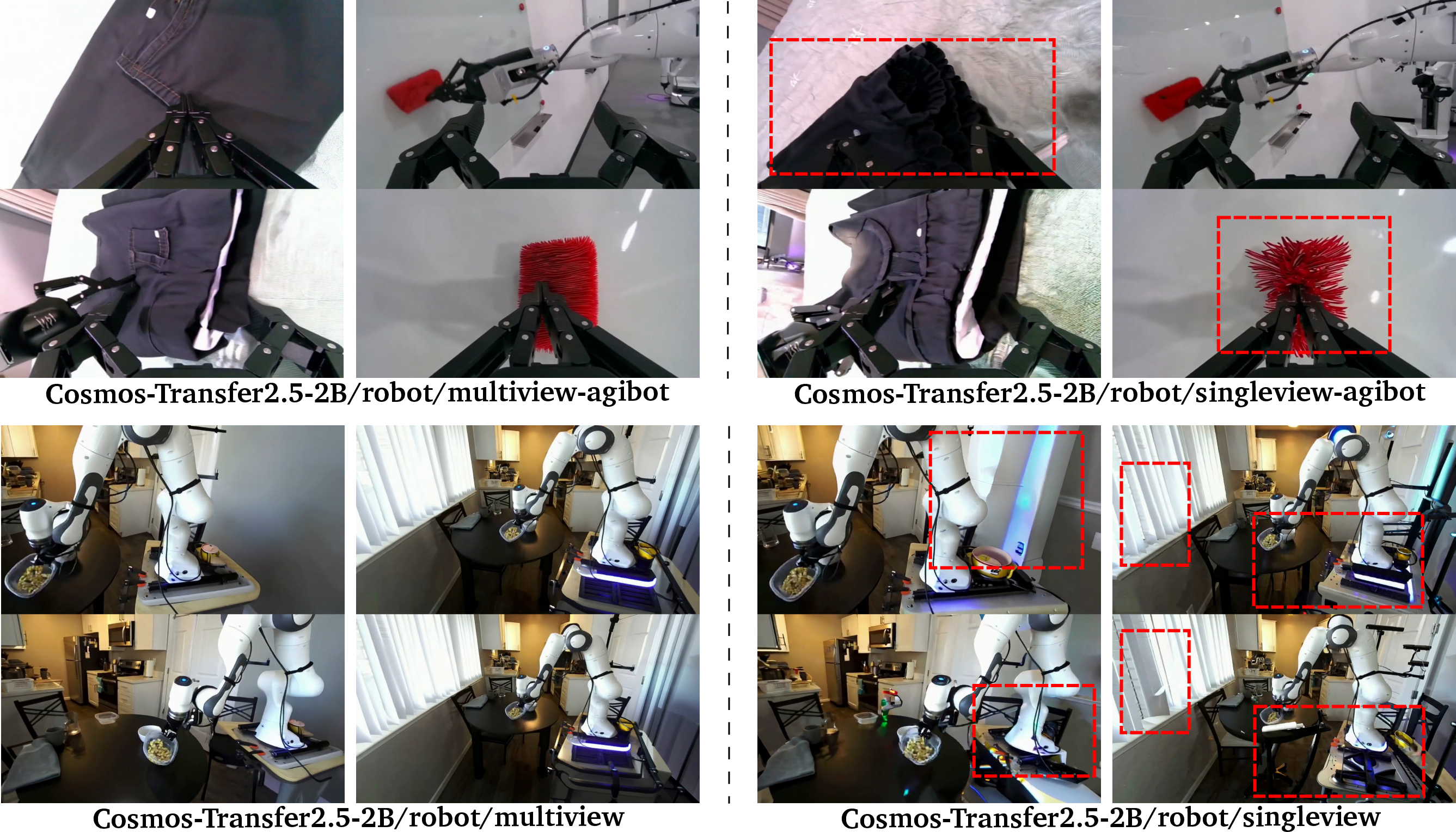
Cosmos-Transfer2.5 can follow controls like edges, depth maps, or semantic layouts (think: a sketch or a map of a driving scene) and produce a realistic, multi-view video. It is 3.5× smaller than the previous version but produces higher-quality, longer videos, and is robust over time.
What they found (main results)
- Better video quality and instruction following: Compared to their earlier version (Cosmos-Predict1), videos look sharper, move more naturally, and follow prompts more accurately.
- One model for many tasks: Text2World, Image2World, and Video2World are unified in a single system, making it easier to use and deploy.
- Strong domain performance: Special fine-tuning for robots, driving, and more led to clear improvements, confirmed by human testers.
- Reinforcement learning helps: After RL, both automated scores and human votes went up. People preferred the RL-tuned videos more often.
- Much faster generation with distillation: The distilled model makes high-quality videos in only a few steps, keeping benchmark scores close to the teacher model.
- Smaller, better translation model: Cosmos-Transfer2.5 is 3.5× smaller than before, yet more realistic and stable over long sequences, supporting closed-loop simulation (where an AI acts, sees the result, and acts again).
Why this matters: These improvements make it far easier to generate realistic, controllable training data and test environments for robots and autonomous systems—without the cost or risk of doing everything in real life.
Why this work matters (impact and future possibilities)
- Safer training: Robots and self-driving systems can practice in a simulator that looks and behaves more like the real world, reducing accidents and damage during learning.
- Faster progress: High-quality synthetic data helps train Vision-Language-Action models and control policies at scale, speeding up research and development.
- Better testing: Action-conditioned and multi-view video generation lets teams test “what-if” scenarios (different roads, weather, crowds) before going on the road or into a factory.
- More accessible tools: The authors are releasing code, model checkpoints, and benchmarks under an open license, lowering the barrier for others to build, customize, and innovate.
- Toward embodied intelligence: Reliable world simulation is a key stepping stone for Physical AI that can see, think, and act safely and skillfully in our world.
In short, Cosmos-Predict2.5 and Cosmos-Transfer2.5 bring us closer to realistic, controllable, and efficient world simulation—helping embodied AI learn better, faster, and more safely.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Physical plausibility evaluation is not quantified: there are no metrics or tests for adherence to physical laws (e.g., gravity, momentum, collision responses, fluid continuity). Develop standardized physics-benchmarks that track objects over time and test conservation, kinematics, and material interactions via 3D trajectory estimation and event detection.
- Long-horizon generation remains unvalidated: training and evaluation are limited to ~5.8s clips (93 frames). Assess stability, semantic drift, identity preservation, and motion coherence for 30–120s and multi-minute sequences; characterize failure modes and memory scaling with context parallelism.
- Multi-view geometric consistency is not measured: the paper lacks tests for cross-view coherence (e.g., epipolar constraints) and correct coupling to ego-motion. Evaluate camera calibration fidelity, multi-view triangulation consistency, and 3D scene reconstruction accuracy from generated surround-view driving and robot videos.
- Action-conditioned interface is under-specified: the “action-conditioned” model lacks details on action representations (continuous vs discrete), timing alignment, and control APIs. Define a standardized action schema, temporal alignment protocol, and evaluate closed-loop rollouts against task success rates and policy stability.
- Sim2Real claims lack quantitative validation: improvements in Transfer2.5 and “closed-loop simulation” are stated but not measured. Report policy performance gains on real robots/vehicles after training in Cosmos worlds, domain gap metrics (e.g., FVD/FID, kNN feature distances), and ablations versus alternative photorealization/translation methods.
- Reward-model dependence and reward hacking mitigation are opaque: VideoAlign is used, but the “fine-grained regularization beyond KL” is not specified or ablated. Release the regularization details, conduct cross-reward validation, human preference sensitivity tests, and demonstrate robustness to reward misspecification/hacking.
- RL post-training is only reported for the 2B model and excludes Video2World: provide RL results for the 14B model and for Video2World conditioning; analyze scaling behavior (quality vs cost), stability, and data efficiency.
- Distillation coverage is narrow: distillation is evaluated only for Text2World and Image2World, not Video2World or action-conditioned generation, nor for long-horizon videos. Benchmark distilled models across all modes and durations; report latency, throughput, and quality-speed trade-offs.
- Caption quality and hallucination risks are unquantified: heavy reliance on VLM-generated captions (Qwen2.5-VL) may introduce errors/biases. Measure caption accuracy/hallucination rates, assess impact on alignment, and compare to human-verified or structured labels; explore confidence-aware training or dual-encoder consistency checks.
- Deduplication may suppress rare or critical scenarios: embedding-based dedup and preference for older/high-res clips can remove edge cases. Audit dedup precision/recall, track rare-event retention, and implement rarity-aware dedup to preserve tail distributions (e.g., uncommon weather, accidents, failures).
- Conditioning via frame replacement lacks ablation: replacing initial frames can cause seams or conditioning leakage. Compare alternative strategies (latent locking, noise-rescaling, per-frame classifier-free guidance, temporal blending) and quantify effects on coherence and fidelity.
- Positional encoding generalization is untested: removing absolute embeddings and using 3D RoPE is motivated but not evaluated across unseen resolutions/sequence lengths. Test resolution/length generalization, spatiotemporal drift, and robustness to camera motion and aspect ratio changes.
- Text encoder substitution is not ablated: switching from T5 to Cosmos-Reason1 with multi-block concatenation is not isolated. Provide controlled experiments quantifying effects on prompt alignment, instruction following, and sample quality; study embedding dimensionality trade-offs.
- Vision conditioning via Cosmos-Reason1 is deferred: the model can accept visual inputs (images/videos) through the VLM, but this is “left for future work.” Integrate and benchmark visual-guided control (style, identity, layout), and compare to ControlNet-style signals and diffusion adapters.
- Safety and ethical considerations are limited: content filters exist, but safety alignment for closed-loop use is not evaluated. Define safety metrics (e.g., unsafe action incidents in simulated rollouts), analyze dataset biases (e.g., Human Dynamics constraints on crowd sizes), and probe downstream bias impacts on embodied decision-making.
- Reproducibility gaps in RL reward service: the elastic reward service and VideoAlign usage are described but not fully open-sourced or reproducible. Release service APIs, models, prompts, and evaluation protocols; provide resource/latency profiles and scaling guides.
- PAI-Bench metric definitions are missing: “Domain Score” and “Quality Score” lack formal definitions, datasets, and statistical reporting. Publish metric formulas, test set composition, annotator protocols, and confidence intervals; ensure public benchmarks for comparability.
- Camera-controllability metrics are absent: claims of “camera-controllable” multi-view generation are not measured. Define controllability tasks and metrics (e.g., viewpoint command tracking error, temporal stability under camera motion commands) and evaluate across domains.
- Real-time suitability is unclear: inference latency, memory footprint, and throughput for closed-loop control are not reported. Benchmark 2B/14B and distilled models under real-time control budgets (e.g., 30–60 Hz decision cycles) and common hardware configurations.
- Scheduler and timestep shift sensitivity is not studied: choices like β progression and 5% sampling from top 2% noise are ad hoc. Perform sensitivity analyses on noise schedules and sampling strategies; generalize recipes across datasets and tasks.
- Robustness to occlusion, motion blur, and extreme conditions is unexamined: no stress tests for adverse weather, lighting, or sensor artifacts. Construct robustness suites and report degradation profiles and recovery strategies (e.g., augmentation, adversarial training).
- Error taxonomy and diagnostics are limited: “abrupt transitions” are noted but broader failure modes are not cataloged. Build automatic detectors (e.g., temporal flicker, identity swaps, geometry inconsistencies) and use them in training and evaluation loops.
- Model merging lacks principled selection: model soup is chosen via grid search on small sets. Explore principled weight-space merging with regularization and multi-objective optimization; report catastrophic forgetting analyses and domain interpolation behavior.
- Transfer2.5 “robust long-horizon translations” are not quantified: no metrics for drift, identity preservation, or style consistency over time. Define temporal translation metrics and evaluate across multi-minute sequences and varied control signals.
- Domain coverage and edge cases remain uncertain: despite curation, coverage of rare but critical events (e.g., near-misses, mechanical failures) is not reported. Publish domain coverage stats and build targeted mining pipelines to enrich tails without compromising dedup or filtering.
Practical Applications
Overview
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations. Each item is linked to relevant sectors, potential tools/products/workflows, and key assumptions or dependencies that may impact feasibility.
Immediate Applications
These can be deployed now with the released code, checkpoints, and models.
- Synthetic data generation for Vision-Language-Action (VLA) model training (robotics, autonomous driving, smart spaces, education)
- What: Use Cosmos-Predict2.5 (Text2World, Image2World, Video2World) to produce large, diverse, physically grounded video datasets for perception and policy learning.
- Tools/Products: Cosmos-Predict2.5-2B/14B; domain-specialized variants (auto/multiview, robot/action-cond, robot/multiview-agibot, GR00T GR1); curated caption prompts.
- Workflow: Prompt library → domain-balanced sharded sampling → batch generation → label/caption reuse → train VLA/BC/RL models → evaluate with PAI-Bench and VideoAlign rewards.
- Assumptions/Dependencies: Synthetic data coverage matches target domain; downstream models can leverage video-only supervision; compute capacity for generation and training; alignment of captions with task semantics.
- Pre-deployment policy evaluation via action-conditioned world generation (robotics, autonomous systems)
- What: Validate control policies by rendering their implied trajectories and scenes using action-conditioned Cosmos-Predict2.5 models.
- Tools/Products: Cosmos-Predict2.5-2B/robot/action-cond; win-rate evaluation vs baselines; RL post-trained checkpoints for better alignment.
- Workflow: Policy rollout → action-conditioned Video2World generation → qualitative and reward-based evaluation (VideoAlign) → human preference studies → iterate policies before real-world trials.
- Assumptions/Dependencies: Generated dynamics sufficiently reflect real-world constraints; consistent temporal coherence across action steps; calibrated evaluation metrics.
- Surround-view autonomous driving simulation for perception and scenario coverage (automotive, ADAS)
- What: Generate synchronized 7-camera driving videos to train/evaluate perception stacks and rare event handling.
- Tools/Products: Cosmos-Predict2.5-2B/auto/multiview; Cosmos-Transfer2.5-2B/auto/multiview (world scenario map → multiview video).
- Workflow: Scenario map authoring → multiview generation → perception training (detection, tracking, segmentation) → performance evaluation on targeted attributes (weather, illumination, road types).
- Assumptions/Dependencies: Camera model and extrinsic/intrinsic alignment; realistic agent interactions and ego motions; integration with existing data ingestion pipelines.
- Photorealistic enhancement of physics simulators (Sim2Real content) and style-consistent augmentation (robotics, industrial vision, gaming/content)
- What: Translate simulator outputs (edges, depth, segmentation) into photorealistic videos to bridge domain gaps and augment training sets.
- Tools/Products: Cosmos-Transfer2.5-2B/general (controlnets for edge/blur/segmentation/depth).
- Workflow: Render sim frames → control-net translation → train detectors/segmenters on photorealistic outputs → measure performance lift on real data.
- Assumptions/Dependencies: Simulator outputs accurately encode scene geometry; translation preserves object identity and motion; monitoring for artifact induction.
- Multi-view robotic manipulation simulation and dataset expansion (robotics)
- What: Generate coherent multi-view manipulation sequences to improve visual grounding, viewpoint robustness, and policy generalization.
- Tools/Products: Cosmos-Predict2.5-2B/robot/multiview-agibot; Cosmos-Predict2.5-14B/robot/gr00t; head-view/third-person variants in Cosmos-Transfer2.5-2B/robot.
- Workflow: Define tasks and camera setup → multi-view generation → VLA/BC training → evaluation across embodiments and camera rigs.
- Assumptions/Dependencies: Accurate handling of contact-rich dynamics and object permanence; consistent camera synchronization; availability of task metadata for prompt grounding.
- Data privacy and compliance via Real2Real augmentation and anonymization (policy/privacy, healthcare, retail)
- What: Translate real videos to privacy-preserving styles while maintaining motion and scene semantics.
- Tools/Products: Cosmos-Transfer2.5 general/multiview variants; style control via semantic inputs.
- Workflow: Ingest videos → apply translation (de-identification, consistent styling) → reuse for model training and audits.
- Assumptions/Dependencies: Regulatory acceptance; identity removal without degrading action semantics; watermarking or provenance tracking.
- Smart spaces digital twin content for CV training and operational analytics (industrial/logistics)
- What: Generate factory/warehouse scenario videos to train detection/tracking/activity recognition for automation and safety monitoring.
- Tools/Products: Smart spaces domain-curated data and prompts; Cosmos-Predict2.5 base; Cosmos-Transfer2.5 for style translation.
- Workflow: Define operational scenarios → generate/translate video sets → train and test CV models → deploy analytics dashboards.
- Assumptions/Dependencies: Coverage of domain-specific machinery and layouts; consistent motion realism; integration with existing analytics pipelines.
- Human-robot interaction safety training using human dynamics (robotics, healthcare)
- What: Simulate varied human motions and interactions to train robots in proximity safety and compliant behavior.
- Tools/Products: Human dynamics dataset; Cosmos-Predict2.5 Text2World/Image2World with human-centric prompts.
- Workflow: Scenario design (poses, speeds, occlusions) → generation → policy training with proximity constraints → in-sim validation.
- Assumptions/Dependencies: Correct representation of human kinematics; robust caption grounding for dynamic states; ethical review for use cases.
- Physics education and media content creation (education, media)
- What: Generate clear, physically plausible clips (e.g., fluid flow, collisions) for teaching and explainer content.
- Tools/Products: Physics domain prompts and curated data; Text2World generation at 720p; distilled 4-step inference for fast turnaround.
- Workflow: Topic prompt → clip generation → instructor vetting → embed in LMS/videos.
- Assumptions/Dependencies: Adequate physical plausibility for instruction; clear disclaimers where generative approximations apply.
- Real-time or near-real-time simulation on resource-constrained devices via distillation (embedded robotics, edge computing)
- What: Use distilled models capable of high-fidelity generation in ~4 steps for on-device augmentation (e.g., sensor dropout handling, scene hypothesis testing).
- Tools/Products: Cosmos-Predict2.5-2B distilled checkpoints; hybrid context/FSDP2 supports.
- Workflow: Integrate distilled generator → low-latency inference loop → test stability and quality metrics → deploy in edge systems.
- Assumptions/Dependencies: Hardware acceleration (GPU/NPUs); acceptable trade-offs between speed and fidelity; robust memory management.
- Scalable video data operations adopting the curation pipeline (software/data engineering)
- What: Implement shot-aware splitting, strict filtering (aesthetic/motion/OCR/perceptual/semantic), captioning, dedup, and sharding.
- Tools/Products: Pipeline components; Delta Lake and Milvus integration; VLM-based captioning.
- Workflow: Ingest corpora → multi-stage filtering → caption segmentation → semantic dedup → taxonomy-based sharding → analytics.
- Assumptions/Dependencies: Access to GPU/CPU clusters; content governance; integration with internal data lakes and vector DBs.
- Academic reproducibility and benchmarking (academia)
- What: Use open models, code, and curated benchmarks to compare training recipes (FM vs EDM), positional encodings, RL alignment, and distillation methods.
- Tools/Products: Released repositories and checkpoints; PAI-Bench; VideoAlign reward service; FSDP2, Ulysses-style context parallelism, SAC policies.
- Workflow: Reproduce training → evaluate on PAI-Bench → test RL post-training → publish ablations.
- Assumptions/Dependencies: Sufficient compute; familiarity with distributed training stacks; stable reward servers.
Long-Term Applications
These require further research, scaling, or development.
- Full closed-loop simulators for end-to-end policy learning with reliable Sim2Real transfer (robotics, autonomous systems)
- What: Train perception-control stacks entirely in generative video worlds and deploy to real systems with minimal domain gap.
- Tools/Products: Combined Cosmos-Predict2.5 + Cosmos-Transfer2.5; integrated RL pipelines; “Physical AI Studio” platform.
- Assumptions/Dependencies: Higher physical fidelity (contacts, deformables, long-horizon stability); accurate sensor modeling; standardized transfer evaluation.
- Regulatory pre-certification pipelines using generative scenario coverage (policy/regulation, automotive, robotics)
- What: Standardized, auditable simulation suites that cover rare safety-critical scenarios before field trials.
- Tools/Products: Scenario authoring tools; PAI benchmarks extended with compliance criteria; third-party verification services.
- Assumptions/Dependencies: Regulator buy-in; objective metrics linking synthetic performance to real-world safety; provenance and bias audits.
- City-scale digital twins for multi-agent traffic simulation (energy/transport, urban planning, automotive)
- What: Coherent, multi-view, multi-agent generative simulations across districts for planning, AV training, and policy testing.
- Tools/Products: “SurroundView-Forge” for large-area generation; traffic scenario maps → multiview pipelines; agent behavior models integrated with generative video.
- Assumptions/Dependencies: Multi-agent consistency; long-horizon temporal coherence; scalable inference serving; data governance with municipalities.
- Household and industrial robot training predominantly in sim with task-complete curricula (robotics, consumer, manufacturing)
- What: Learn complex manipulation and navigation tasks via generative curricula, then deploy with minimal fine-tuning.
- Tools/Products: Task libraries; multi-view rig calibrators; ROS2 connectors; curriculum schedulers.
- Assumptions/Dependencies: Realistic contact dynamics and object permanence; consistent embodiment-to-simulation mapping; standardized evaluation.
- Privacy-preserving synthetic video as a drop-in replacement for real recordings (policy/privacy, healthcare, retail)
- What: Replace many categories of sensitive data collection with validated synthetic equivalents for model development and audits.
- Tools/Products: “Privacy Video Translator” built on Cosmos-Transfer2.5; watermarking/provenance tools; traceability dashboards.
- Assumptions/Dependencies: Legal acceptance; validated equivalence for downstream tasks; robust defenses against inversion or re-identification.
- Physical AI Studio: a unified product ecosystem for world simulation and alignment (software, MLOps)
- What: End-to-end platform for scenario authoring, generation, reward alignment, distillation, and deployment to robotics/autonomy stacks.
- Tools/Products: Prompt libraries; reward services (VideoAlign); deployment templates (FSDP2, Ulysses CP); evaluation harnesses (PAI-Bench).
- Assumptions/Dependencies: Productization and UI; enterprise-grade MLOps; cost models for inference and training.
- Education at scale with verified generative physics and human dynamics (education, public sector)
- What: Curriculum-integrated, interactive video modules explaining physical phenomena and safe human-robot interactions.
- Tools/Products: LMS plugins; instructor verification workflows; adaptive difficulty generation.
- Assumptions/Dependencies: Verified correctness (peer-reviewed content); content moderation; accessibility standards.
- Domain-specific medical simulation for surgical robotics and procedural training (healthcare)
- What: Generate high-fidelity procedural videos for training perception/control in surgical contexts.
- Tools/Products: Medical fine-tuning datasets; specialized reward models; simulation-translation pipelines.
- Assumptions/Dependencies: Clinical validation; ethical and regulatory approvals; collaboration with medical institutions.
- Risk modeling for insurance/finance using synthetic hazard scenarios (finance/insurance, transport)
- What: Stress-test risk models with rare-event simulated videos (collisions, extreme weather) to refine underwriting and pricing.
- Tools/Products: Scenario libraries; statistical coverage tools; cross-domain evaluation methods.
- Assumptions/Dependencies: Causal validity linking synthetic scenarios to real-world loss distributions; governance and transparency frameworks.
- Remote inspection and UAV training in energy and infrastructure (energy, utilities)
- What: Generate inspection scenarios for power lines, pipelines, and turbines to train UAV perception and navigation.
- Tools/Products: Domain prompts, multiview generation; control-net translation for sensor fusion (depth/segmentation).
- Assumptions/Dependencies: Accurate environmental and asset modeling; multi-sensor coherence; integration with UAV autopilots.
- Continuous integration (CI) for video AI systems with generative tests (software engineering)
- What: Automate regression tests using controlled generative scenarios to validate perception models before production pushes.
- Tools/Products: CI plugins; scenario versioning; performance dashboards with PAI-Bench metrics.
- Assumptions/Dependencies: GPU test infrastructure; test coverage design; metrics that correlate with field performance.
Glossary
- 3D RoPE: A three-dimensional rotary positional embedding scheme for encoding spatial-temporal positions in attention. "Positional Embedding & \multicolumn{2}{c}{3D RoPE}"
- Adaptive Layer Normalization (AdaLN): A normalization that modulates activations with learned scale/shift (and often gating) conditioned on context or timestep. "modulated by adaptive layer normalization (scale, shift, gate) for a given time step ."
- All-to-all collectives: Distributed GPU communication primitives that exchange data among all participants efficiently. "leveraging intra-node all-to-all collectives on NVIDIA GPUs."
- Consistency distillation: A training method that encourages a student model to produce outputs consistent with a teacher across continuous timesteps. "integrates continuous-time consistency distillation with distribution matching distillation."
- Context parallelism: Splitting long sequences across devices to fit memory and parallelize attention computation. "we employ context parallelism."
- Control-net: An auxiliary conditioning network/framework that steers generative models using structured controls (e.g., edges, depth, segmentation). "a control-net style framework for Sim2Real and Real2Real world translation."
- Cross-attention: Attention mechanism that conditions generation on external inputs (e.g., text) by attending from latent tokens to context tokens. "these embeddings are integrated into the denoising process via cross-attention layers"
- Curriculum-based training: Progressively sampling or structuring data from easy to hard to stabilize and improve learning. "This structured sharding enables efficient sampling, curriculum-based training, and fine-grained domain balancing."
- DARE-Linear: A model-merging approach using decayed rank-one updates for combining fine-tuned checkpoints linearly. "We experiment with four approaches: model soup, TIES, DARE-Linear, and DARE-TIES."
- DARE-TIES: A hybrid merging technique combining DARE and TIES heuristics to fuse multiple fine-tuned models. "We experiment with four approaches: model soup, TIES, DARE-Linear, and DARE-TIES."
- Ego-vehicle: The vehicle equipped with sensors whose viewpoint defines the dataset’s perspective. "ego-vehicle maneuvers (\eg, slow curves and sharp turns)"
- Elucidated Diffusion Model (EDM): A diffusion framework with specific preconditioning that standardizes inputs/outputs to Gaussians for stable training. "the Elucidated Diffusion Model (EDM)~\citep{karras2022elucidating}, which was used in [Cosmos-Predict1]"
- EMA weight: Exponential moving average of parameters used for more stable inference or release. "We release the EMA weight after reinforcement learning on the merged model"
- Flash attention: A memory- and speed-optimized attention algorithm that fuses kernels to reduce IO and improve throughput. "fused flash attention with Jacobian–vector product (JVP) support"
- Flow matching (FM): A diffusion training objective that predicts the velocity of the diffusion trajectory rather than noise. "We adopt flow matching (FM)~\citep{lipman2022flow} for training diffusion models"
- FSDP2: Fully Sharded Data Parallel v2; shards parameters, gradients, and optimizer states per-parameter for scalable training. "We use FSDP2 as our primary distributed training framework"
- GRPO: A policy optimization method using group-relative advantages within rollouts to stabilize RL fine-tuning. "following GRPO~\citep{guo2025deepseek}"
- Jacobian–vector product (JVP): An efficient way to compute the product of a Jacobian and a vector without forming the Jacobian explicitly. "fused flash attention with Jacobian–vector product (JVP) support"
- KL divergence: A measure of divergence between two probability distributions used as regularization in RL post-training. "beyond the KL divergence to alleviate the reward hacking phenomenon."
- Latent frames: Compressed temporal representations produced by a video tokenizer/autoencoder that correspond to multiple pixel frames. "24 latent frames"
- LoRA (Low-Rank Adaptation): Parameter-efficient fine-tuning that injects low-rank adapters into weight matrices. "AdaLN-LoRA Dimension"
- Logit-normal distribution: A distribution obtained by applying the logistic function to a normal variable, used to sample diffusion timesteps. "a timestep drawn from a logit-normal distribution"
- Long-horizon: Spanning long temporal durations that require maintaining consistency and stability over many frames. "robust long-horizon video generation."
- Model merging: Combining multiple fine-tuned models’ weights to unify strengths without joint training. "we adopt model merging \citep{yang2024model}"
- Model soup: Averaging weights of multiple fine-tuned models to improve generalization without additional training. "We experiment with four approaches: model soup, TIES, DARE-Linear, and DARE-TIES."
- Milvus: An open-source vector database optimized for similarity search over embeddings. "Milvus~\citep{milvus_zilliz_2019}, an open-source vector database for embedding-based search"
- NATTEN sparse attention: Neighborhood Attention Transformers providing sparse, local attention for efficiency on large inputs. "such as NATTEN sparse attention~\citep{hassani2025generalized}"
- Object permanence: The property that objects continue to exist even when not visible; used as a domain for training/evaluation. "object permanence"
- Online deduplication: Incremental deduplication where each new item is compared to retained items to remove semantic duplicates. "we adopt an online deduplication strategy"
- Patchification: Dividing latent/image tensors into fixed-size patches for transformer processing. "we apply the same patchification strategy"
- Perceptual quality filter: An automated filter that removes technically distorted or artifact-laden clips based on perceptual metrics. "a perceptual quality filter (akin to DOVER~\citep{dover})"
- Preconditioning coefficients: Scaling factors in diffusion parameterizations that standardize inputs/outputs to stabilize training. "In EDM, the preconditioning coefficients are chosen so that both the inputs and outputs of the denoising network are approximately standardized Gaussians"
- Relative positional embeddings: Position encodings defined by relative offsets rather than absolute indices to generalize across lengths/resolutions. "the removal of the absolute positional embeddings and only keeping the relative positional embeddings."
- Reinforcement learning (RL): Post-training procedure that optimizes generation using reward signals aligned with human or model preferences. "we further enhance generation quality by applying a reinforcement learning (RL) algorithm"
- Reward hacking: The phenomenon where a model exploits reward function loopholes rather than improving real quality. "to alleviate the reward hacking phenomenon."
- Ring attention: A sharded attention strategy that arranges devices in a ring for communication during attention. "Compared with the ring-attention strategy used in the diffusion world model of [Cosmos-Predict1]"
- rCM: A hybrid forward–reverse joint distillation framework for accelerating diffusion inference. "we adopt a hybrid forward-reverse joint distillation framework, rCM~\citep{zheng2025large}"
- Selective Activation Checkpointing (SAC): Checkpointing policy that saves memory by recomputing selected activations during backprop. "we apply torch Selective Activation Checkpointing (SAC) using a fine-grained policy."
- Semantic deduplication: Removing near-duplicate content by comparing embeddings for semantic similarity. "In the semantic deduplication stage, we first assign video clips to clusters using embedding-based similarity."
- Sharding: Partitioning a dataset or model along defined axes to enable scalable storage and training. "The dataset is then sharded along multiple axes: content type, resolution, aspect ratio, and length."
- Shifted logit-normal distribution: A reweighted logit-normal that biases sampling toward higher noise levels in diffusion training. "we adopt the shifted logit-normal distribution~\citep{esser2024scaling}."
- Sim2Real: Transferring policies or generative outputs learned in simulation to the real world. "a control-net style framework for Sim2Real and Real2Real world translation."
- Surround-view: Multi-camera setup providing 360-degree coverage around a vehicle. "surround-view video clips collected using NVIDIA’s internal driving platform."
- TIES: Task-Integrated EditS or a specific parameter-merging method for combining fine-tuned models. "We experiment with four approaches: model soup, TIES, DARE-Linear, and DARE-TIES."
- Timestep distillation: Speedup technique that distills a many-step diffusion sampler into a few-step student. "The inference of diffusion-based world generation can be substantially accelerated through timestep distillation."
- Ulysses-style parallelism: A context-parallel attention partitioning strategy that uses efficient all-to-all communication. "we adopt the Ulysses-style parallelism approach"
- Variational autoencoder (VAE): A probabilistic encoder–decoder that compresses data into a learned latent space. "WAN2.1 VAE~\citep{wan2025}, a causal variational autoencoder that compresses video sequences"
- Velocity-based formulation: Diffusion parameterization where the model predicts the velocity between noisy and clean states. "This velocity-based formulation not only provides a more direct training target"
- VideoAlign: A VLM-based reward model that scores text alignment, motion, and visual quality for RL post-training. "we adopt VideoAlign~\citep{liu2025improving}, a VLM-based reward model that evaluates text alignment, motion quality, and visual quality"
- Vision-Language-Action (VLA): Models that map from multimodal perception and instructions to actions. "synthetic data generation for Vision-Language-Action (VLA) model training"
- Vision-LLM (VLM): Models that jointly process visual and textual inputs for understanding or generation. "we use a vision LLM (VLM)~\citep{qwen2p5vl} to further remove clips"
- Visual tokenizer: A model (often a VAE) that converts images/videos into compressed latent tokens for transformer-based generators. "For the visual tokenizer, we use WAN2.1 VAE"
Collections
Sign up for free to add this paper to one or more collections.

