Toward Ultra-Long-Horizon Agentic Science: Cognitive Accumulation for Machine Learning Engineering
Abstract: The advancement of artificial intelligence toward agentic science is currently bottlenecked by the challenge of ultra-long-horizon autonomy, the ability to sustain strategic coherence and iterative correction over experimental cycles spanning days or weeks. While LLMs have demonstrated prowess in short-horizon reasoning, they are easily overwhelmed by execution details in the high-dimensional, delayed-feedback environments of real-world research, failing to consolidate sparse feedback into coherent long-term guidance. Here, we present ML-Master 2.0, an autonomous agent that masters ultra-long-horizon machine learning engineering (MLE) which is a representative microcosm of scientific discovery. By reframing context management as a process of cognitive accumulation, our approach introduces Hierarchical Cognitive Caching (HCC), a multi-tiered architecture inspired by computer systems that enables the structural differentiation of experience over time. By dynamically distilling transient execution traces into stable knowledge and cross-task wisdom, HCC allows agents to decouple immediate execution from long-term experimental strategy, effectively overcoming the scaling limits of static context windows. In evaluations on OpenAI's MLE-Bench under 24-hour budgets, ML-Master 2.0 achieves a state-of-the-art medal rate of 56.44%. Our findings demonstrate that ultra-long-horizon autonomy provides a scalable blueprint for AI capable of autonomous exploration beyond human-precedent complexities.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ML-Master 2.0, an AI “research assistant” designed to work on long, complicated projects without losing track. The focus is on machine learning engineering (like Kaggle competitions), where success takes many hours of trial and error. The big problem: today’s LLMs are good at short tasks but get overwhelmed by details in long projects. ML-Master 2.0 tackles this by organizing its “memory” like a computer cache—keeping what’s needed right now close by, saving important lessons for later, and turning the best ideas into reusable wisdom.
What questions did the researchers ask?
They mainly asked:
- How can an AI stay focused and make steady progress on projects that take many hours or even days?
- How can it remember what really matters (the lessons) without carrying around every tiny detail (the noise)?
- Can we turn messy trial-and-error into stable knowledge that helps in future projects?
How did they try to solve it?
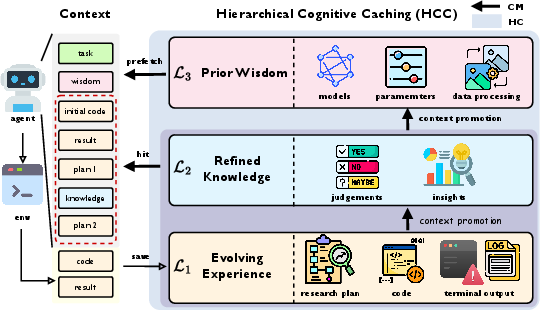
The authors built a system called Hierarchical Cognitive Caching (HCC). Think of it like three notebooks the AI uses during a long project:
- Layer L1: Evolving Experience (a “scratchpad”)
- This is the working memory. It stores the current plan, code changes, error messages, and recent results—the stuff you need right now to debug or make the next move.
- Layer L2: Refined Knowledge (a “summary notebook”)
- When a chunk of work is done, the AI writes a short summary of what actually mattered: which ideas worked, which failed, and why. It throws away the unnecessary details but keeps the reasons behind decisions.
- Layer L3: Prior Wisdom (a “playbook”)
- After finishing a whole task, the AI distills big, reusable lessons (like reliable model templates or how to avoid common pitfalls). These lessons are stored so they can be looked up for future tasks that look similar.
To make these notebooks useful, the AI also has rules for moving information between them:
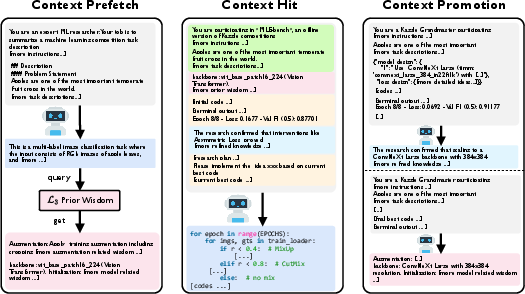
- Prefetching (getting a head start): Before starting a new task, it looks up similar past tasks in its playbook (L3) and loads the most relevant tips to begin smarter.
- Context hits (smart recall): While working, it first uses fresh details from the scratchpad (L1). If older details are needed, it pulls the short summaries from the summary notebook (L2) instead of re-loading long logs.
- Promotion (tidying up): After finishing a phase, it compresses the messy logs from L1 into a neat summary in L2. After finishing the whole task, it turns L1 + L2 + the final solution into “wisdom” and stores it in L3 for next time.
An everyday analogy: imagine you’re doing a big science fair project.
- Your desk has sticky notes and current sketches (L1).
- Your notebook has clean summaries of what you tried and learned (L2).
- Your binder has timeless tips and best practices you’ve collected from past projects (L3). You don’t keep every sticky note forever—you promote only the important ideas to your notebook, and only the best lessons go into your binder.
They tested ML-Master 2.0 on MLE-Bench, a set of 75 real machine learning tasks (inspired by Kaggle), giving the agent 24 hours per task to try ideas, run code, and submit results.
What did they find?
Here are the key results:
- Strong overall performance: ML-Master 2.0 earned a medal on 56.44% of tasks, the best reported result in their comparisons.
- Works across difficulties: It did well on easy, medium, and hard tasks (75.8%, 50.9%, and 42.2% medal rates, respectively), showing it can handle both simple and complex problems.
- Each memory layer matters: In ablation tests (where they remove parts to see what breaks), removing any of the three layers hurt performance. Together, the layers work best.
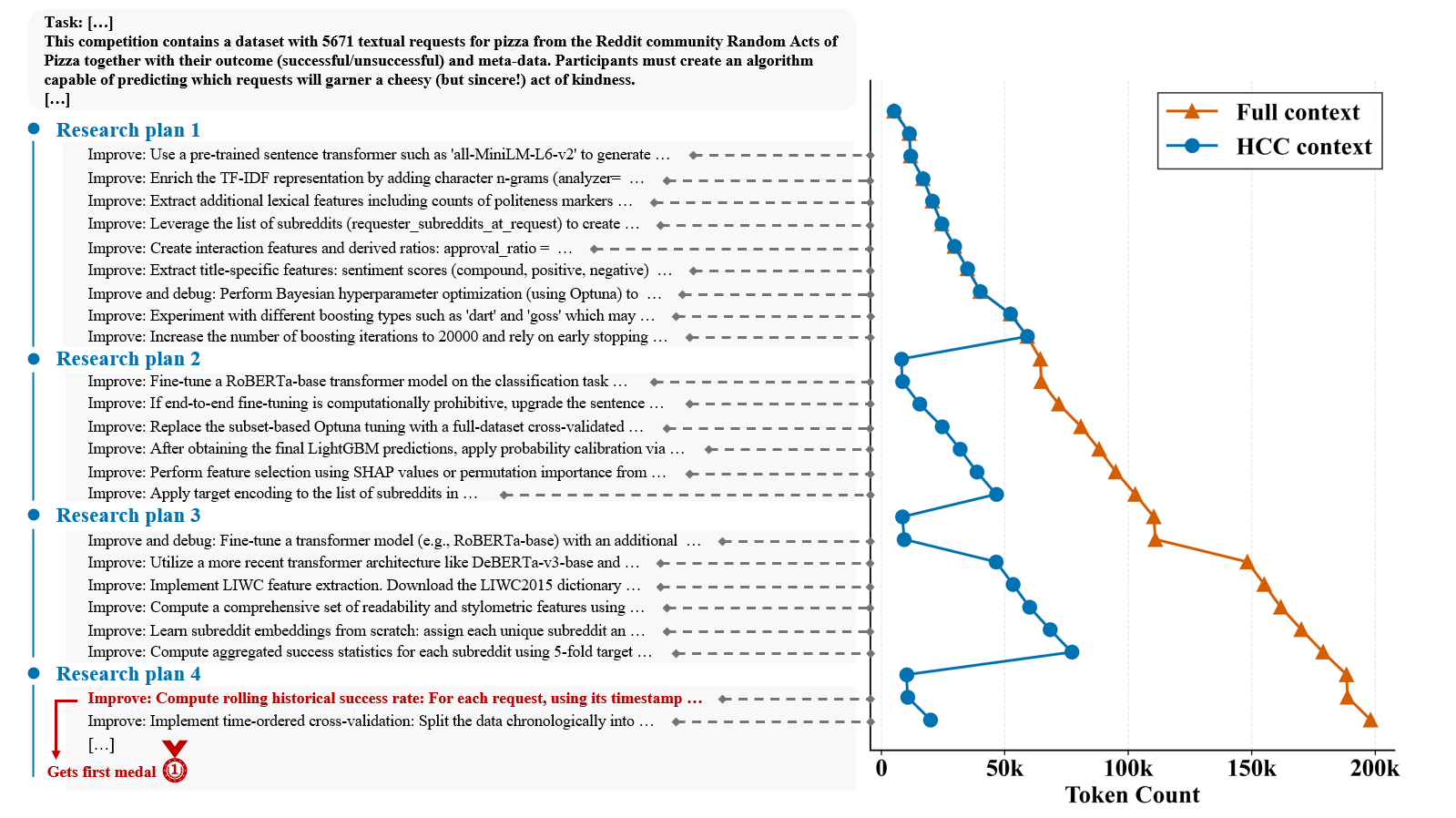
- Keeps context under control: Without HCC, the AI’s “to-read” context could balloon past 200,000 tokens (too big and slow). With HCC, it stayed around 70,000 while still keeping the important lessons—big savings that help it think clearly over many hours.
- Improves over time: As the hours pass, the AI’s solutions keep getting better, showing it learns from its own experiments during the day.
Why this is important: It shows that careful “thinking with memory”—turning raw experience into knowledge, then into wisdom—helps AI handle long, messy projects better than just stuffing more text into a bigger window.
What does this mean going forward?
This work is a step toward “agentic science,” where AI can run long research workflows with many experiments, setbacks, and course corrections—just like real scientists do. The key idea is simple but powerful: don’t try to remember everything. Instead, organize memory by time and importance—work now with details (L1), carry forward clean insights (L2), and build a reusable playbook (L3).
If this approach continues to scale, it could:
- Make AI better at week-long projects, not just one-off answers.
- Speed up machine learning engineering by reusing proven strategies.
- Transfer to other fields with long feedback loops (like robotics, biology, or materials science), helping AI run and refine experiments over days or weeks.
In short, ML-Master 2.0 shows that smart memory—what to keep, what to compress, and what to reuse—can unlock long-horizon, self-improving AI research.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored, highlighting concrete directions future researchers could pursue:
- External validity beyond MLE-Bench: The approach is only demonstrated on Kaggle-style machine learning competitions under 24-hour horizons; it is unclear how HCC performs in domains with non-code interactions, expensive/delayed physical feedback (e.g., wet-lab experiments, robotics), or multi-week cycles.
- Dependence on large compute budgets: Results are reported with 36 vCPUs, 2×RTX 4090 GPUs, and 24-hour runs; there is no sensitivity analysis to time/compute budgets, energy cost, or efficiency (e.g., medal rate per dollar or per kWh), nor a fairness-normalized comparison against baselines under matched resources.
- LLM backbone sensitivity: The system relies on DeepSeek variants (including “with thinking” for promotion). It lacks model-agnostic evaluation and ablations across multiple LLMs to quantify how HCC’s benefits transfer across architectures and context-window sizes.
- Missing formalization of cognitive accumulation: The paper introduces “experience → knowledge → wisdom,” but provides no quantitative criteria, formal definitions, or theoretical guarantees (e.g., stability, convergence, or error bounds) for when and how promotion should occur.
- Promotion fidelity and validation: LLM-based summarization is used to distill traces into knowledge/wisdom without automated validation. There are no mechanisms to check for hallucinations, incorrect generalizations, or lost critical details, nor metrics to quantify promotion quality.
- Negative transfer risks from prior wisdom (L3): Prior wisdom is retrieved via cosine similarity on task descriptors, but there are no safeguards against misleading priors, domain shift, or spurious similarity. No experiments examine how often L3 hurts performance, or strategies for gating, reweighting, or revoking harmful wisdom.
- Retrieval design and hyperparameters: The embedding model for E(·), similarity threshold δ, and descriptor generation prompts are unspecified and untested. There is no sensitivity analysis for δ, the number of retrieved items, or embedding choice, nor comparisons of alternative retrieval schemes (e.g., structured indices, hybrid symbolic–vector retrieval).
- Lifecycle management and capacity control of caches: L2/L3 growth over many tasks is not addressed. There are no eviction, aging, deduplication, or provenance policies; no strategy for concept drift or freshness; and no mechanisms to update or deprecate outdated wisdom.
- Recovery of raw traces: After phase-level promotion, raw trajectories are removed from L1. There is no mechanism to rehydrate raw evidence if summaries prove insufficient or incorrect, nor policies for selective retention of high-value raw context.
- Metrics for “long-horizon autonomy”: Beyond medal rates, the paper lacks domain-agnostic metrics for strategic coherence, iterative correction quality, reuse efficiency, or accumulation yield (e.g., proportion of decisions supported by promoted knowledge, cross-task transfer gains).
- Phase planning design: The hierarchical research plan parameters (number of directions m, suggestions per direction q) and scheduling/allocation policies are not specified or ablated. It is unclear how these are tuned, adapt to task difficulty, or interact with compute constraints.
- Parallel execution coordination: The agent executes multiple suggestions in parallel, but there is no analysis of conflict resolution, synchronization, or cross-branch knowledge sharing beyond summarization, nor a comparison to search/evolutionary strategies under similar conditions.
- Token budget robustness: While one case shows reducing peak context from >200k to ~70k tokens, there is no systematic evaluation across tasks, window sizes, and models, nor policies for dynamic truncation, prioritization, and compression under tight token limits.
- Comprehensive failure analysis: The paper does not characterize failure modes (e.g., tasks where the agent underperforms or where gold medal rates lag behind some baselines), nor provide a taxonomy of errors (planning vs. retrieval vs. promotion failures) to guide targeted improvements.
- Baseline comparability and reproducibility: Many baselines are closed-source with environment differences; results are partly borrowed from MLE-Bench reports. There is no matched-run comparison, detailed seeds/configurations, code/prompt release, or reproducible pipelines for the reported SOTA.
- Cold-start performance: The agent benefits from an L3 warm-start built from 407 Kaggle competitions. The paper does not quantify performance without prior wisdom, nor provide a principled bootstrapping protocol for new domains with scarce historical tasks.
- Wisdom granularity and structure: L3 stores “text wisdom” keyed by task descriptors. There is no exploration of structured artifacts (e.g., executable templates, validated pipelines, param priors with uncertainty) or modularization to enable composable reuse and safer transfer.
- Governance of promotion frequency: The paper does not specify when promotions (P1/P2) are triggered, how often, or with what acceptance criteria. No ablation studies investigate promotion timing, batch size, or adaptive policies based on observed stability/variance.
- Provenance and auditability: Promoted knowledge/wisdom lacks explicit provenance links to source traces and decisions. There is no mechanism to trace back a recommendation to its evidence, which hampers debugging, trust, and compliance.
- Security, licensing, and compliance: Persisting cross-task wisdom from Kaggle competitions raises potential IP/licensing concerns. The paper does not discuss data governance, redaction of sensitive content, or safeguards for external data incorporation.
- Extension to multi-day/weekly horizons: Despite claiming ultra-long-horizon autonomy, experiments are capped at 24 hours. It remains open how HCC behaves over truly extended periods (days/weeks), including memory drift, resource fatigue, and long-term coherence.
- Interaction with human oversight: The agent operates fully autonomously. The paper does not explore human-in-the-loop intervention points (e.g., approving promotions, reviewing wisdom, adjusting plans) or protocols to combine human judgment with HCC.
- Standardized benchmarks for agentic science: Evaluation remains tied to Kaggle/MLE-Bench. There is no proposal or use of a benchmark suite that captures delayed feedback, cross-experiment reuse, and multi-phase planning typical of scientific workflows.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s methods, results, and implementation patterns. Each bullet highlights the sector, potential tools or workflows that might emerge, and key assumptions or dependencies.
- [Software, Data Science] Agentic AutoML for tabular and structured ML tasks
- Tools/Workflows: “Agentic AutoML” platform built on ML-Master 2.0; integrates hierarchical research plans, parallel exploration directions, and phase-level summaries; warm-start via prior wisdom retrieval.
- Assumptions/Dependencies: Access to capable coding LLMs, compute similar to the paper’s setup (e.g., multi-GPU), high-quality prior wisdom corpus, and experiment tracking.
- [Software Engineering] Long-horizon coding assistants for repository refactoring and iterative debugging
- Tools/Workflows: IDE extensions (VSCode/JetBrains) implementing HCC (L1/L2/L3 caches), “plan-phase loop” orchestrator, and “phase-level promotion” microservice to condense logs into actionable insights.
- Assumptions/Dependencies: Reliable LLM code generation, robust CI/test suites, disciplined version control, and privacy-safe cache storage.
- [MLOps] AI experiment governance and token-budget control
- Tools/Workflows: HCC-based memory manager coupled with MLflow/Weights & Biases; cache-aware prompting module to reduce peak context length; automated CV leakage detection + rationale summaries in refined knowledge.
- Assumptions/Dependencies: Integration with existing MLOps stack, secured artifacts/log access, and calibrated migration policies to avoid loss of critical detail.
- [Analytics, BI, Finance] Iterative model development concierge for forecasting, scoring, and risk modeling
- Tools/Workflows: Agent-driven “research plan scheduler” for experiments over days; distilled knowledge for model rationale and auditability; prior wisdom for warm-start on similar datasets.
- Assumptions/Dependencies: Clean data pipelines, human oversight for acceptance criteria, governance for model risk, and clear evaluation metrics.
- [Academia] Reproducible long-horizon ML research workflows
- Tools/Workflows: Phase boundary definitions, refined knowledge artifacts for method sections, and prior wisdom catalogs that accelerate replication across courses and labs.
- Assumptions/Dependencies: Consistent dataset access, experiment logs preserved for promotion, and alignment with institutional IRB/data governance.
- [Education] Project-based learning assistants for semester-long data projects
- Tools/Workflows: Tutor agents that maintain evolving experience per student team, distill phase outcomes into reusable knowledge and guidance across similar assignments.
- Assumptions/Dependencies: LMS integration, guardrails to prevent academic dishonesty, and domain-adapted prior wisdom.
- [Enterprise Knowledge Management] Cognitive memory fabric for AI agents
- Tools/Workflows: Organization-wide “Prior Wisdom KB” (L3) populated via embeddings and task descriptors; threshold-based prefetching for similar projects; lifecycle policies for knowledge retention.
- Assumptions/Dependencies: Strong semantic embedding models, standardized task descriptors, data privacy agreements, and memory governance policies.
- [Agent Frameworks] Drop-in HCC middleware for LangChain/OpenHands-style agents
- Tools/Workflows: HCC SDK implementing context hit/promotion policies, cache APIs, and prompt templates for phase/task-level promotion; migration rules configurable per domain.
- Assumptions/Dependencies: Compatibility with agent runtimes, reliable summarization prompts, and evaluators for cache correctness.
- [Cost Optimization] Token and compute cost reduction for LLM agents
- Tools/Workflows: HCC-based prompt construction reducing peak tokens (e.g., from 200k to ~70k as demonstrated), thus lowering inference costs while preserving strategy continuity.
- Assumptions/Dependencies: Accurate phase summaries, appropriate fallback to raw traces when detailed debugging is needed, and token accounting tools.
- [Policy and Benchmarking] Standardized evaluation for long-horizon agent autonomy
- Tools/Workflows: Adoption of MLE-Bench (and Lite) as procurement/evaluation criteria for agentic systems; reporting medal rates, valid submission rates, and context-length profiles.
- Assumptions/Dependencies: Public benchmark access, cross-lab comparability, and reporting guidelines for compute/use of external wisdom.
Long-Term Applications
These applications require further research, scaling, domain adaptation, safety/regulatory work, or infrastructure. They are aligned with the paper’s long-horizon autonomy blueprint and HCC architecture.
- [Scientific Discovery, Agentic Science] AI co-scientist across lab domains (biology, chemistry, materials)
- Tools/Workflows: HCC-driven agents that distill multi-week experimental cycles into reusable paradigms; integrate robotics + instruments for delayed feedback loops; task-level wisdom spanning lab families.
- Assumptions/Dependencies: Real-world lab integration, reliable instrument APIs, safety and compliance, and robust validation beyond purely computational tasks.
- [Energy, Materials] Mission-scale AutoR&D for computational and hybrid (sim + lab) discovery
- Tools/Workflows: DOE-scale AutoR&D OS that orchestrates hierarchical planning, cross-branch exploration, and wisdom promotion across programs; aligns with initiatives like the Genesis mission.
- Assumptions/Dependencies: Large shared compute, standardized experiment logs, cross-site data governance, and domain priors beyond Kaggle-style ML.
- [Healthcare] Compliance-aware HCC for clinical ML (EHR modeling, triage, trial design)
- Tools/Workflows: Refined knowledge for audit trails, task-level wisdom for generalizable clinical pipelines, privacy-preserving caches, and regulator-aligned memory lifecycle policies.
- Assumptions/Dependencies: HIPAA/GDPR compliance, clinical validation and bias assessments, secure multi-tenant caches, and human-in-the-loop oversight.
- [Finance] Autonomous quant research loops with explainable knowledge promotion
- Tools/Workflows: HCC-enhanced backtesting over prolonged horizons; distilled strategy rationales; cross-strategy prior wisdom for transfer; risk/audit integrations.
- Assumptions/Dependencies: Strict risk controls, market data licensing, robust simulation environments, and board-level governance for agent autonomy.
- [Robotics] Long-horizon mission planning and iterative field testing
- Tools/Workflows: Agents that separate evolving logs from consolidated insights across deployments; plan-level caching for multi-day missions; transferable wisdom across environments.
- Assumptions/Dependencies: Reliable sensor/telemetry ingestion, safety envelopes, sim-to-real transfer, and explainability.
- [Education at Scale] Course-memory and cohort-level wisdom for adaptive curricula
- Tools/Workflows: Institutional “Course Memory” that crystallizes cross-cohort insights; adaptive assignment generation; agents that manage semester-long projects with transferable templates.
- Assumptions/Dependencies: Privacy preserving student data policies, careful pedagogy, and content drift management.
- [Enterprise] Organization-wide cognitive fabric and memory governance standards
- Tools/Workflows: “Wisdom Registry” across business units; HCC policies standardized for promotion/eviction; cross-project transfer with embedding-based matching; audit trails for AI decisions.
- Assumptions/Dependencies: Executive buy-in, data classification frameworks, IP protections, and cross-team tooling adoption.
- [Multi-Agent Systems] Shared wisdom and negotiation across agents
- Tools/Workflows: L3 wisdom pooling and versioning; agents negotiate promotion criteria; cross-branch evolution strategies informed by task-level wisdom; conflict resolution protocols.
- Assumptions/Dependencies: Inter-agent communication standards, trust/reputation mechanisms, and governance of shared memory.
- [Standards and Policy] Cognitive cache protocols and lifecycle regulations
- Tools/Workflows: Industry standards for L1/L2/L3 semantics, promotion triggers, retention, and auditability; regulatory frameworks defining explainability and accountability for memory operations.
- Assumptions/Dependencies: Multi-stakeholder efforts, alignment with international privacy/security regimes, and certification processes.
- [Benchmarking and Methods] New long-horizon benchmarks and evaluators beyond MLE-Bench
- Tools/Workflows: Domain-specific long-horizon suites (healthcare, robotics, energy) with delayed feedback; evaluators for sustained strategic coherence and phase-level quality; standardized cost profiles.
- Assumptions/Dependencies: Community datasets, reference agents, open metrics, and reproducibility tooling.
- [Self-Improving AI4AI] Continual curriculum and meta-wisdom refinement
- Tools/Workflows: Systems that automatically expand the prior wisdom cache using solved tasks; selective consolidation; active curriculum generation to improve transfer and robustness.
- Assumptions/Dependencies: Reliable success detection, avoidance of compounding biases, steady-state compute budgets, and monitoring for catastrophic forgetting.
Glossary
- AI-for-AI (AI4AI): A paradigm where AI systems autonomously improve or develop other AI systems. "we situate our research within the paradigm of AI-for-AI (AI4AI), where AI systems autonomously drive the advancement of AI itself."
- Agentic science: A vision of AI systems acting as autonomous scientific agents that plan, execute, and iterate over research processes. "The advancement of artificial intelligence toward agentic science is currently bottlenecked by the challenge of ultra-long-horizon autonomy,"
- cache-like hit policy: A retrieval strategy that prioritizes recent raw information and falls back to summaries when needed, analogous to CPU cache hits. "The context constructor manages historical indices via a cache-like hit policy:"
- cognitive accumulation: The process of distilling transient experiences into stable knowledge and reusable wisdom over time. "By reframing context management as a process of cognitive accumulation, our approach introduces Hierarchical Cognitive Caching (HCC),"
- context constructor: The function that builds the model’s input by selecting and assembling relevant parts of the interaction history. "The context constructor manages historical indices via a cache-like hit policy:"
- context migration: Policies for promoting, consolidating, or discarding information across memory tiers as exploration proceeds. "Context migration, which dictates the governance protocol for how information is dynamically promoted, consolidated, or discarded across these tiers as exploration unfolds."
- context prefetching: Retrieving relevant prior knowledge before execution begins to initialize the agent with strong priors. "The functionality of context prefetching is to let the agent construct a strong initial prior wisdom before exploration begins."
- context promotion: Retrospective abstraction that compresses execution traces into concise knowledge or transferable wisdom. "The context promotion operator performs LLM-based retrospective abstraction that compresses execution traces into concise knowledge or transferable wisdom."
- context saturation: The state where accumulated details exceed the context window, harming strategic coherence. "Naively setting to “concatenate the most recent events” causes context saturation, degrading strategic coherence and preventing accumulation of reusable expertise over tens of hours."
- cross-task transfer: Applying distilled strategies or knowledge from past tasks to new tasks. "enables warm-starting and cross-task transfer."
- delayed-feedback environments: Settings where actions yield outcomes after a significant delay, complicating learning and planning. "high-dimensional, delayed-feedback environments of real-world research,"
- embedding-value pairs: Stored items where a semantic vector (embedding) serves as a key for retrieving associated wisdom text. "We store prior wisdom as a set of embedding-value pairs:"
- external memory paging: Moving information in and out of active context from external storage, akin to OS paging. "hierarchical context buffering and external memory paging."
- Evolving Experience: The high-fidelity, short-term execution traces kept for immediate reasoning and debugging. "Evolving Experience keeps high-fidelity execution traces required for immediate reasoning,"
- graph-based retrieval: Methods that organize and fetch knowledge using graph structures to capture relationships. "graph-based retrieval frameworks such as HippoRAG,"
- Hierarchical Cognitive Caching (HCC): A multi-tiered context architecture that separates transient experience, refined knowledge, and prior wisdom. "Hierarchical Cognitive Caching (HCC), a multi-tiered architecture inspired by computer systems"
- hierarchical context buffering: Layered storage of contextual information to manage limited context windows. "hierarchical context buffering and external memory paging."
- hierarchical memory systems: Multi-level memory designs for agents that organize information by abstraction or stability. "Subsequent hierarchical memory systems, including HiAgent,"
- hierarchical research plan: A structured plan decomposed into directions and concrete implementation suggestions guiding exploration phases. "the agent periodically proposes a hierarchical research plan,"
- interaction trajectory: The ordered sequence of events produced by executing a specific suggestion or plan branch. "Each suggestion induces an interaction trajectory:"
- island-based evolution: A search strategy where multiple solution populations evolve separately with occasional knowledge sharing. "island-based evolution."
- MCTS (Monte Carlo Tree Search): A search algorithm using randomized simulations for decision-making under uncertainty. "which optimizes exploration through rule-based MCTS,"
- multi-tiered architecture: A system design with multiple layers, each tailored to different stability and reuse needs. "a multi-tiered architecture inspired by computer systems"
- operating-system-inspired design: An architecture that borrows OS concepts (e.g., paging, memory separation) for managing agent context. "adopt an operating-system-inspired design that separates active context from external memory,"
- phase boundary: The time step marking the end of one exploration phase and the start of the next. "the agent reaches a phase boundary ,"
- phase-level promotion: Summarizing the completed phase’s raw trajectories into compact knowledge units. "Phase-level promotion. Upon completion of each exploration phase, the phase-level promotion operator compresses the raw parallel exploration trajectories into a refined knowledge unit."
- Prior Wisdom: Task-agnostic, transferable strategies distilled from completed tasks and stored for retrieval. "Prior Wisdom stores task-agnostic, transferable strategies distilled from previously solved machine learning tasks,"
- Refined Knowledge: Mid-term, stabilized summaries capturing validated insights and decisions from prior phases. "Refined knowledge stores intermediate stabilized cognition distilled from completed exploration phases,"
- retrieval key: The embedding or identifier used to fetch the associated wisdom from memory. "serves as the retrieval key,"
- semantic embedding function: A function that maps text to vectors encoding semantic meaning for similarity search. "let be a semantic embedding function."
- self-evolving memory mechanisms: Memory systems that adapt their contents over time based on experience. "and self-evolving memory mechanisms (Evo-Memory)"
- static context windows: Fixed-size input limits of LLMs that constrain how much context can be processed. "effectively overcoming the scaling limits of static context windows."
- task-level promotion: Distilling a completed task’s history into reusable, transferable wisdom. "Task-level promotion. The task-level promotion operator distills transferable wisdom from the structured task history."
- threshold-based prefetching operator: A retrieval rule that includes prior wisdom if similarity exceeds a set threshold. "via a threshold-based prefetching operator "
- ultra-long-horizon autonomy: The capacity to maintain coherent strategy and iterative correction over very extended timescales. "ultra-long-horizon autonomy, the ability to sustain strategic coherence and iterative correction over experimental cycles spanning days or weeks."
- warm-starting: Initializing a new task with relevant prior knowledge to accelerate convergence. "enables warm-starting and cross-task transfer."
- working memory: The near-term storage of detailed traces needed for immediate reasoning and debugging. "This layer acts as the agent's working memory,"
Collections
Sign up for free to add this paper to one or more collections.