- The paper presents a modality-aware Mixture of Experts (MAMoE) that assigns modality-specific expert groups for speech and text to reduce representational interference.
- It employs a two-stage training pipeline with cross-modal post-training and mixed instruction fine-tuning to robustly integrate speech and text modalities.
- Quantitative results demonstrate significant improvements, including up to 21.8% enhancement on spoken QA and lower WER in ASR and TTS benchmarks.
Authoritative Technical Summary: MoST—Mixing Speech and Text with Modality-Aware Mixture of Experts
Architectural Innovations
MoST introduces a unified multimodal LLM architecture specifically optimized for speech-text integration through a Modality-Aware Mixture of Experts (MAMoE) framework. Building on pretrained MoE LLMs, MoST integrates three critical components: modality-specific expert groups dedicated to speech or text, cross-modal shared experts facilitating information interchange, and a modality-aware router. Unlike previous approaches that homogenize multimodal data processing (e.g., [spiritlm], [moshi]), MoST enforces architectural specialization, directly addressing representational interference caused by processing audio and text through identical parameters.
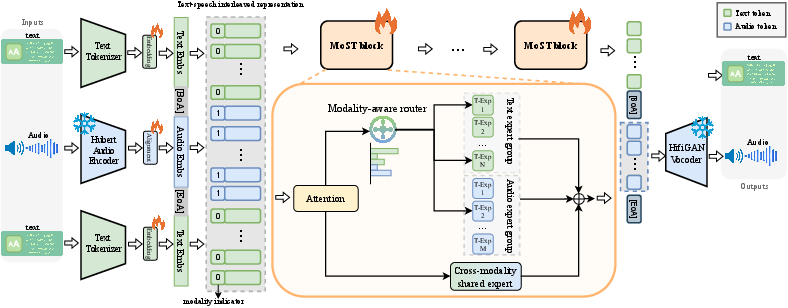
Figure 1: MoST overall architecture facilitating interleaved speech and text input with modality-specific expert routing and shared cross-modal pathways.
Key technical highlights include direct waveform processing via a frozen HuBERT encoder rather than discrete quantization, preserving rich acoustic structure. The routing algorithm utilizes modality indicators to direct tokens to modality-appropriate expert groups, as formalized in Algorithm 1 of the source. Shared experts support robust cross-modal knowledge transfer—a principal contributor to improved generalization and catastrophic forgetting mitigation.
MoST employs an efficient two-stage pipeline converting a pretrained MoE LLM into a speech-text model:
- Cross-Modal Post-Training: Strategic adaptation on ASR/TTS datasets to specialize experts.
- Mixed Instruction Fine-Tuning: Instruction-following using a curated multimodal dataset incorporating synthesized interruptions and text-to-speech converted instructions, with continual exposure to ASR/TTS to maintain foundational speech skills.
All training is conducted with exclusively open-source datasets, a deliberate divergence from practices in models such as SpiritLM and Moshi.
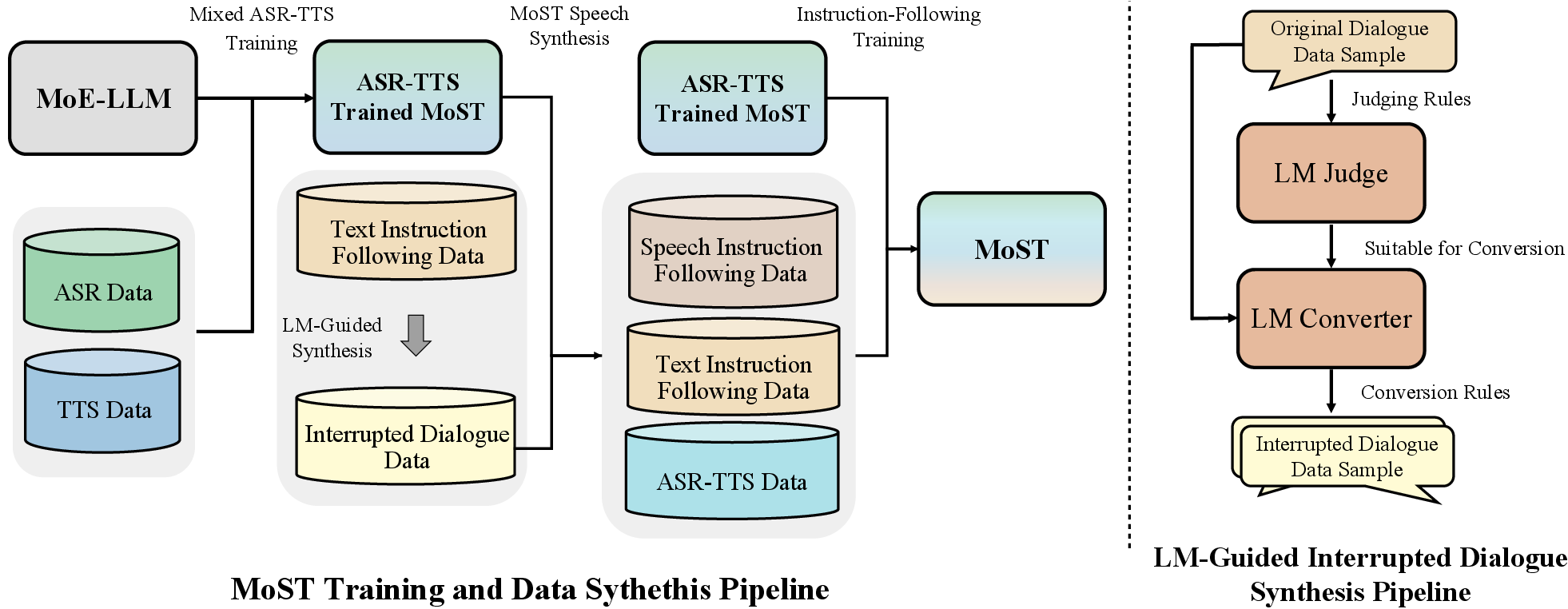
Figure 2: Systematic transformation pipeline and interrupted dialogue synthesis for multimodal instruction dataset enrichment.
Quantitative Results: ASR, TTS, Language Modeling, and SQA
MoST delivers strong empirical outputs across ASR, TTS, audio language modeling, and spoken QA, matching or exceeding state-of-the-art baselines with comparable parameter counts.
ASR performance is marked by consistent improvements over SpeechGPT, AudioLM, and Moshi, achieving 2.0% WER on LibriSpeech clean and 8.4% on Common Voice 15-en. For TTS, MoST establishes a new performance reference at 6.0% WER on LS-Clean and 11.5% CER on Common Voice—exceeding MinMo and LLaMA-Omni2.
Audio language modeling accuracy on sWUGGY, sTopic-StoryCloze, and sStoryCloze is superior or competitive with the strongest baselines (average 71.94), demonstrating fluent speech-text representation alignment. Spoken QA results on Llama Q, Trivial QA, and WebQ show best-in-class scores, particularly in speech-to-speech settings previously challenging for end-to-end models.
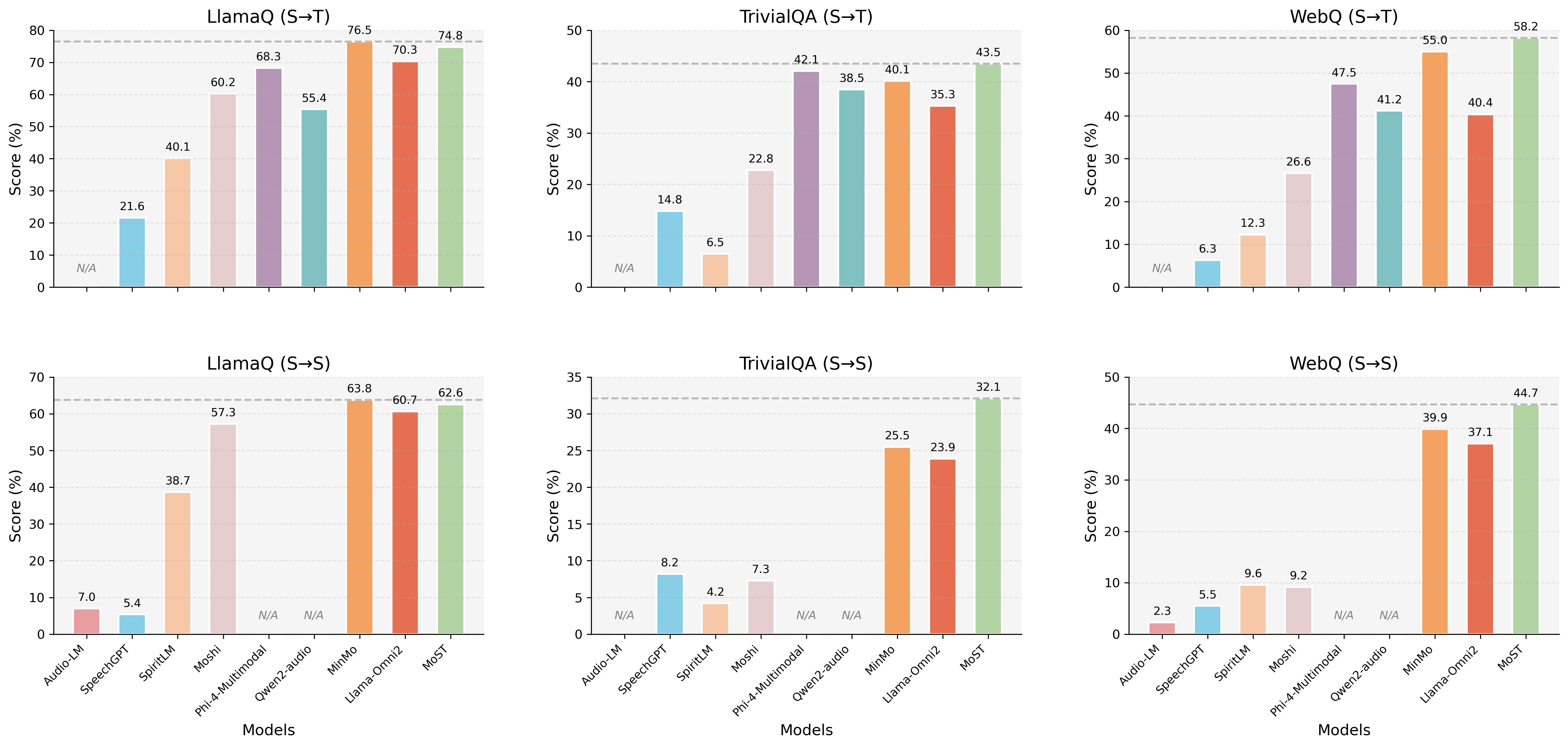
Figure 3: Comparative performance on Spoken Question Answering benchmarks; MoST consistently attains or surpasses leading baselines.
Ablation and Routing Analyses
Controlled initialization and ablation studies rigorously isolate MAMoE’s effect, benchmarking against dense and modality-agnostic MoE variants. When initialized from identical LLM checkpoints, MoST-style upcycling yields clear architectural gains over traditional MoE, with up to 21.8% improvement on SQA—a direct endorsement of modality-aware routing efficacy. Systematic component ablations further confirm shared experts to be essential for retaining cross-modal and text capabilities; exclusion results in generalization degradation across tasks.
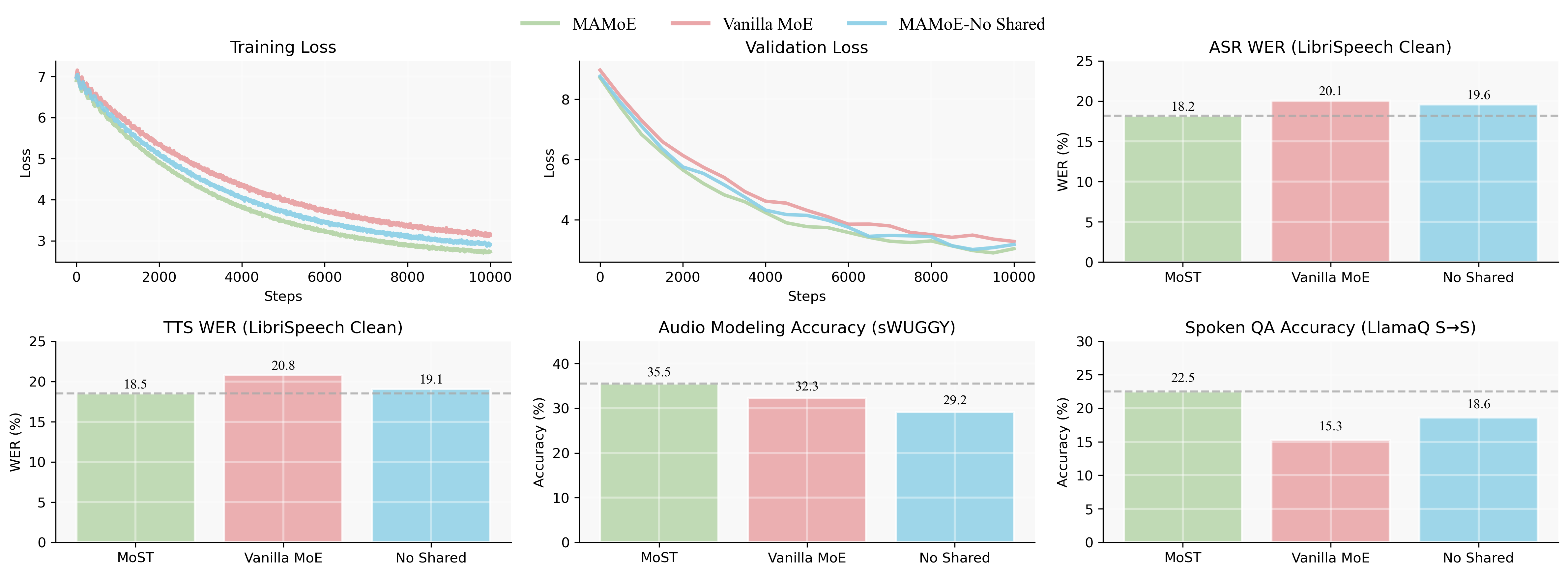
Figure 4: MAMoE design variants analysis; full MAMoE demonstrates consistent superiority over ablated forms in convergence and downstream metrics.
Expert routing examinations reinforce the specialization hypothesis: MAMoE achieves lower routing entropy and Gini coefficient, ensuring balanced expert utilization and distinct modality specialization, critical for avoiding catastrophic interference and capacity dilution.
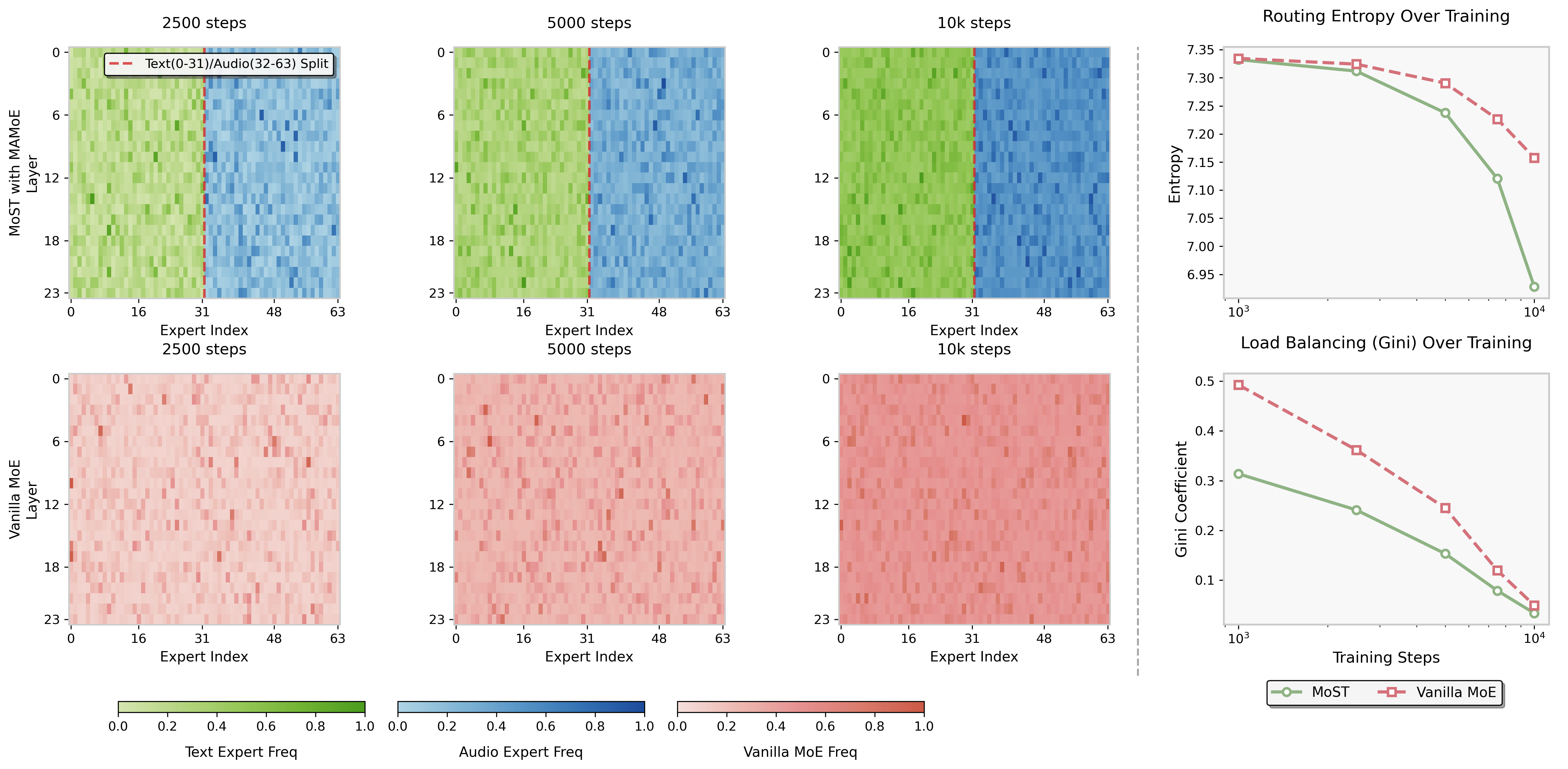
Figure 5: Routing frequency and quantitative specialization/load balancing metrics substantiate MAMoE’s superior expert allocation.
Implications and Future Directions
MoST’s demonstration of modality-specific expert partitioning and cross-modal shared experts carries both theoretical and practical implications. Architecturally, strict expert group assignment outperforms uniform MoE and dense transformer alternatives for speech-text multimodality. Practically, MoST establishes an open-source reference pipeline, lowering barriers for research and application development in speech-oriented LLMs.
The index-based expert partition scheme, effective as evidenced by current results, leaves room for methodological enhancement. Future modalities may benefit from activation-based clustering, adaptive expert allocation, or knowledge-preserving partitioning. The core MAMoE concept generalizes well to additional modalities (e.g., vision), promoting future work towards truly universal multimodal foundational models.
Conclusion
MoST exemplifies the impact of incorporating modality-aware sparsity into large-scale multimodal LLMs. The combination of modality-partitioned experts, shared cross-modal capacities, and rigorous routing delivers robust performance and strong generalization across speech-text tasks, confirmed by both numerical results and component analyses. The released model, codebase, and dataset enable reproducibility and provide a resource for further advances in modality-specialized sparse architectures (2601.10272).

