The Path Ahead for Agentic AI: Challenges and Opportunities
Abstract: The evolution of LLMs from passive text generators to autonomous, goal-driven systems represents a fundamental shift in artificial intelligence. This chapter examines the emergence of agentic AI systems that integrate planning, memory, tool use, and iterative reasoning to operate autonomously in complex environments. We trace the architectural progression from statistical models to transformer-based systems, identifying capabilities that enable agentic behavior: long-range reasoning, contextual awareness, and adaptive decision-making. The chapter provides three contributions: (1) a synthesis of how LLM capabilities extend toward agency through reasoning-action-reflection loops; (2) an integrative framework describing core components perception, memory, planning, and tool execution that bridge LLMs with autonomous behavior; (3) a critical assessment of applications and persistent challenges in safety, alignment, reliability, and sustainability. Unlike existing surveys, we focus on the architectural transition from language understanding to autonomous action, emphasizing the technical gaps that must be resolved before deployment. We identify critical research priorities, including verifiable planning, scalable multi-agent coordination, persistent memory architectures, and governance frameworks. Responsible advancement requires simultaneous progress in technical robustness, interpretability, and ethical safeguards to realize potential while mitigating risks of misalignment and unintended consequences.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explains a big shift in artificial intelligence: moving from chatbots that only write text when asked, to “agentic AI” — systems that can plan, take actions, use tools (like web search or a calculator), remember past steps, and learn from their own results. Think of the change from a smart “autocomplete” to a helpful digital assistant that can plan a task, do parts of it, check its work, and keep going until the goal is met.
What questions did the authors ask?
The authors focus on simple but important questions:
- How did LLMs like GPT grow from text-makers into systems that can act on their own?
- What parts (like memory, planning, and tools) are needed to turn an LLM into an agent that can work step by step?
- Where can agentic AI be useful, and what are the biggest risks and challenges (like safety, reliability, and energy use)?
- What research is still needed before we can safely use agentic AI in the real world?
How did they study it?
This is a review and roadmap paper. That means the authors:
- Look back at the history of LLMs (from simple statistics, to neural networks, to transformers and modern LLMs).
- Gather and organize current ideas about agentic AI into a clear framework (the pieces that make an AI agent work).
- Explain how agents operate using easy patterns like “Reason → Act → Reflect” (think → do → check).
- Show examples (a single agent solving a problem and a team of agents working together).
- Summarize challenges (safety, alignment, memory, costs) and suggest research priorities.
If you imagine building a robot helper: the authors don’t build a new robot here; instead, they study lots of existing robots and plans, then draw a simple blueprint and list what still needs to be fixed before it’s safe to deploy.
What did they find, and why does it matter?
From chatbots to agents: what’s new
Older LLMs mostly answered questions once and stopped. Agentic AI goes further: it plans steps, calls tools, checks results, and tries again if needed. This turns a passive model into an active problem-solver.
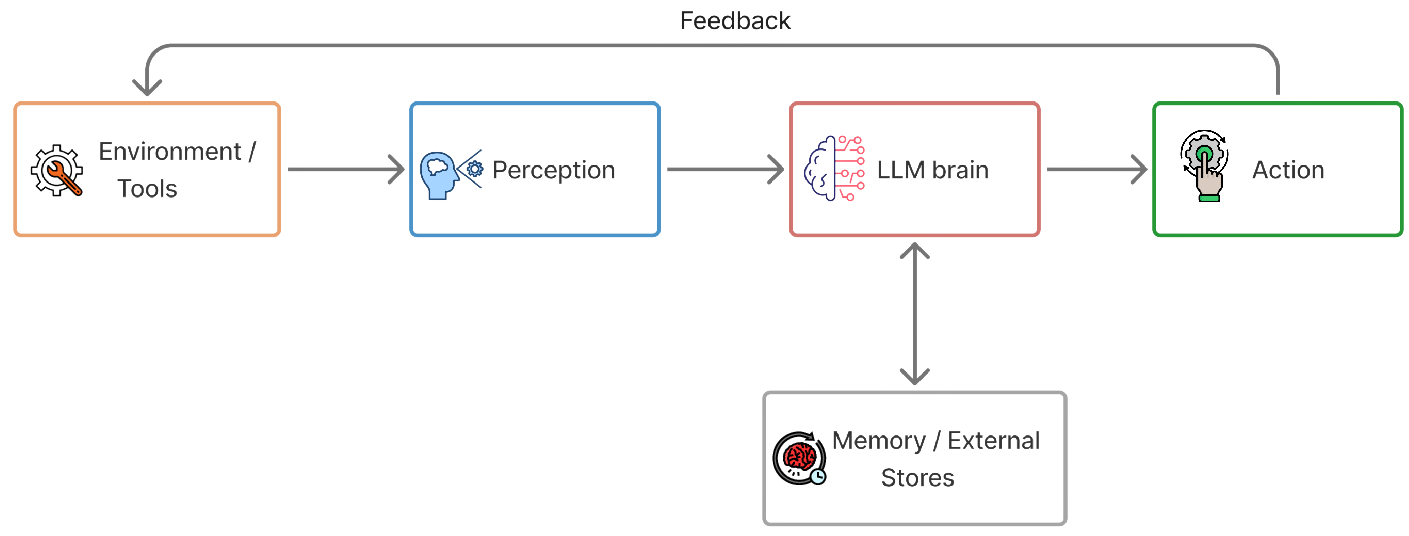
The core parts of an AI agent
To make an agent, you combine an LLM “brain” with four key parts:
- Perception: turning raw inputs (search results, sensor data) into something the model can read — like an AI’s “eyes and ears.”
- Memory: a notebook to store helpful facts, past steps, and lessons learned so the agent stays consistent over time.
- Planning: breaking big goals into smaller to-dos and choosing the next best action.
- Tools/Action: using calculators, web search, databases, software, or even robots — like a toolbox the agent can pick from and operate.
Together, these parts form a loop: see → think → do → remember → repeat.
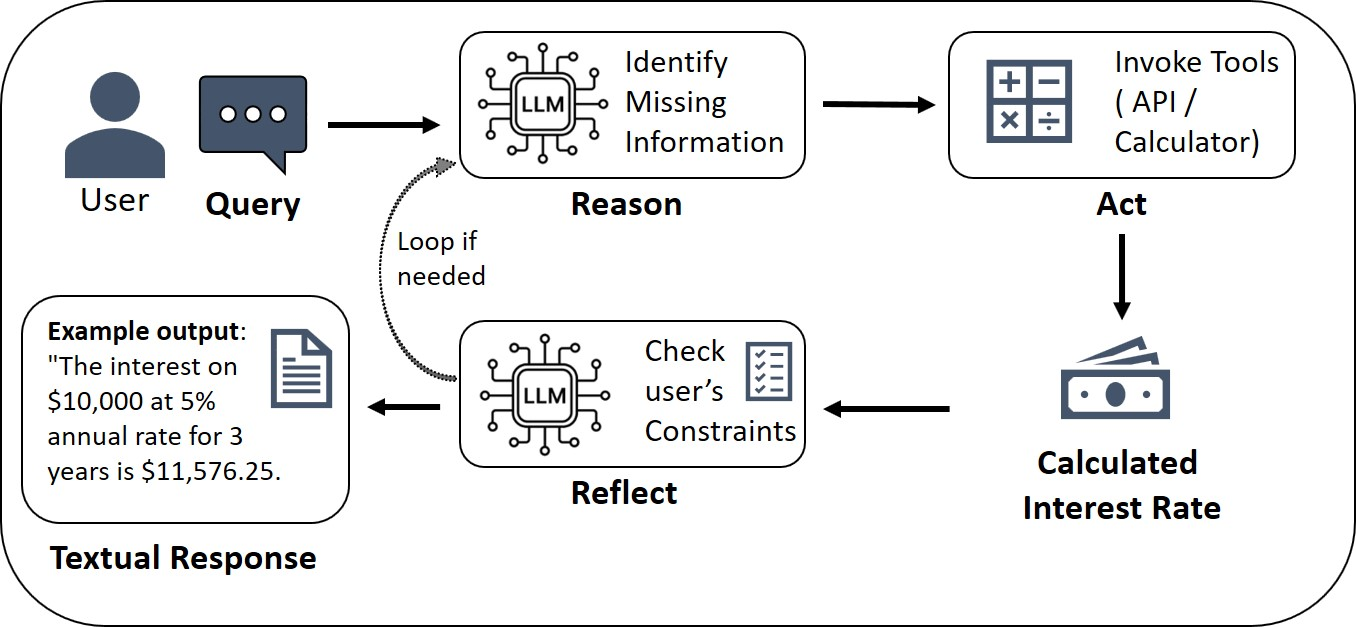
The Reason–Act–Reflect loop (think → do → check)
Agents often follow a simple cycle:
- Reason: Decide what to do next.
- Act: Use a tool or take a step.
- Reflect: Check if it worked; fix mistakes; update the plan and memory.
This step-by-step loop makes the agent’s process more transparent and easier to audit than a one-shot answer.
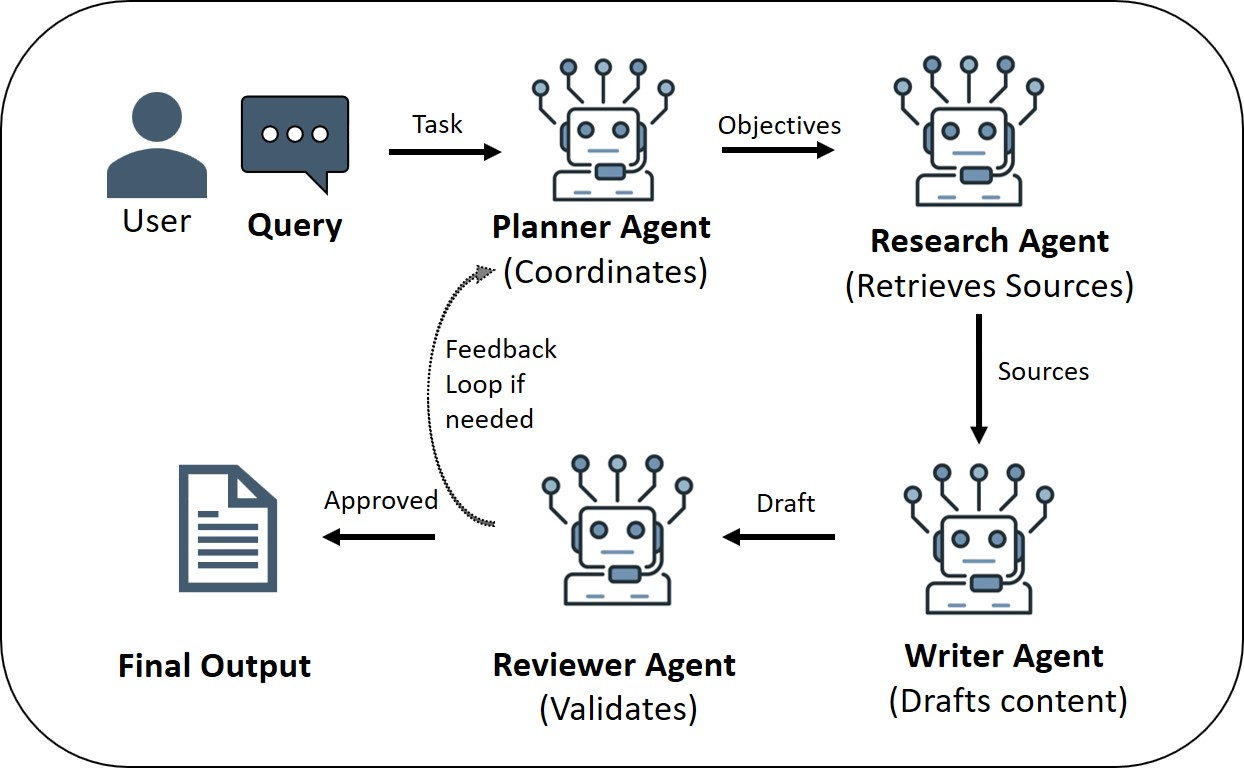
One agent vs. a team of agents
- Single agent: one “all-in-one” helper that plans, acts, and checks by itself.
- Multi-agent team: a group with roles (Planner, Researcher, Writer, Reviewer) that talk to each other. This can be more powerful and robust for big tasks, like a project team in school.
Where can this be used?
Agentic AI can help with:
- Research assistance (searching, summarizing, drafting, reviewing)
- Coding and software tasks (planning fixes, testing, reviewing code)
- Education (personalized tutoring with step-by-step guidance)
- Robotics (turning language into safe, concrete actions)
- Business operations (workflows, customer support, data analysis)
The biggest challenges
Because agents can act in the world, problems matter more. Key issues include:
- Safety and alignment: making sure agents follow human rules and don’t cause harm.
- Reliability: long, multi-step plans can magnify small mistakes; results can vary run-to-run.
- Memory risks: stored info can drift, become biased, leak private data, or cause “made-up” recalls.
- Accountability and ethics: if an agent makes a harmful decision, who is responsible?
- Cost and sustainability: long loops and tool calls use a lot of computing power and energy.
What research is most urgent?
The paper highlights priorities:
- Verifiable planning and tool use (prove steps are safe and correct; recover from errors)
- Better interpretability (clear action traces and explanations in real time)
- Strong, structured memory (stay consistent for weeks or months without drifting)
- Multi-agent coordination (rules for communication, roles, and conflict resolution)
- Efficient, greener systems (use less compute and energy)
- Governance and auditing (permissions, guardrails, and standard safety tests)
What does this mean for the future?
If done responsibly, agentic AI could become a reliable partner: planning projects, using tools, and learning across time — not just answering one question. It could help researchers, teachers, engineers, and even robots act more safely and effectively.
But getting there requires careful work. We need:
- Strong safety guardrails and human oversight for important actions
- Clear explanations of what agents did and why
- Better memory systems to avoid mistakes and protect privacy
- Rules and standards so organizations can be accountable
In short, agentic AI is promising because it turns LLMs into helpful doers, not just talkers. To make that promise real — and safe — we must improve reliability, transparency, and sustainability, and set smart rules. If we balance innovation with responsibility, these agents can become trustworthy teammates that amplify human skills without causing unintended harm.
Knowledge Gaps
Unresolved Knowledge Gaps and Open Questions
The chapter outlines concepts and challenges for agentic AI but leaves several concrete issues unaddressed. Future work can target the following gaps:
- Formal, testable definition of “agentic behavior” distinct from advanced prompting and single-turn LLM inference; establish an operational taxonomy with measurable criteria and boundary cases.
- Standardized benchmarks for agentic tasks (long-horizon planning, verifiable tool execution, reflection efficacy, multi-agent coordination), including task suites, ground-truth checkers, and metrics for auditability, robustness, and sample efficiency.
- Reproducible evaluation harnesses comparing frameworks (ReAct, Toolformer, LangChain, AutoGen, Crew, etc.) under controlled conditions with fixed seeds, deterministic tool backends/mocks, and versioned configurations.
- Methods for formal verification of plans and actions (e.g., pre/postconditions, contracts, type systems, temporal logic, runtime monitors) integrated with LLM-generated code and workflows.
- Quantitative analysis of stochastic decoding and routing effects on reliability (temperature, top‑p, logit bias, MoE routing decisions) across multi-step loops and long action chains.
- Tool-use reliability and safety: standardized tool schemas, authentication, sandboxing, rollback mechanisms, and datasets of tool/API failure modes to measure propagation and recovery.
- Security posture for agent-tool interactions: adversarial testing suites for prompt injection, data exfiltration, jailbreaking via tool outputs, and cross-site scripting in web agents, plus validated defense strategies.
- Memory architecture design trade-offs (working/episodic/long-term) with empirical studies on interference, drift, hallucinated recall, retention/decay policies, and memory-contingent privacy risks over weeks-long tasks.
- Consistency and concurrency in shared memory for multi-agent systems (CRDTs, locking models, provenance tracking), and their impact on correctness, latency, and coordination overhead.
- Uncertainty calibration for agent decisions and tool outcomes, including confidence estimates, abstention/deferral policies, and gating thresholds that prevent unsafe actions.
- Multi-agent coordination protocols with formal guarantees (negotiation, role assignment, conflict resolution, deadlock/livelock avoidance) and scalability evaluations under varying team sizes and heterogeneity.
- Cross-lingual and culturally grounded agent benchmarks beyond English, with explicit metrics for linguistic accuracy, cultural alignment, fairness, and reliability (including Arabic and low-resource settings).
- Explainability and auditability standards: minimal actionable logging schema for reasoning, tool calls, and state transitions; assessments of audit log utility vs privacy/compliance constraints.
- Human-in-the-loop design patterns: controlled trials to determine when agents should solicit approvals, UI/UX that balances operator burden with risk reduction, and measurable impacts on safety-critical outcomes.
- Governance and permissions models: machine-readable policies, capability scoping, time-bounded roles, and attestation mechanisms; empirical tests of policy enforcement under adversarial conditions.
- Sustainability quantification: energy per perception–reason–act–reflect loop, carbon accounting across architectures and tool chains, and effectiveness of energy-aware scheduling, caching, and model compression.
- Grounding and safety in embodied/robotic agents: standardized sim-to-real benchmarks, physical risk mitigation protocols, and robust perception pipelines resistant to sensor noise and adversarial perturbations.
- Robustness in non-stationary, open-ended environments: protocols for safe adaptation/lifelong learning that avoid catastrophic behavior, with drift detection and rollback strategies.
- Privacy-preserving memory: differential privacy, encryption-at-rest/in-use, access controls, and sanitization pipelines; measurable privacy leakage rates and remediation efficacy.
- Comparative studies of hybrid symbolic–neural systems: when symbolic planning yields verifiable gains, formal guarantees achievable, and cost–benefit analyses for real deployments.
- Failure taxonomy and incident reporting standards for agentic AI, including a public repository of failure cases and structured root-cause analyses to inform design guidelines.
- Trustworthiness metrics (reliability, safety, ethical compliance) aggregated into deployment risk grades; validation protocols tying metrics to operational decisions in regulated domains.
- End-to-end reproducibility standards: environment pinning, containerized agents, recorded tool/API responses via deterministic mocks, and shareable experiment manifests for independent replication.
- Multi-modal agentic AI gaps: fusion strategies across text, vision, audio, 3D; robustness to cross-modal adversaries; benchmarks for perception-to-action consistency.
- Legal and economic impact analyses: liability allocation for autonomous actions, insurance and compliance models, and practical conformance tests for sector-specific regulations.
- Chain-of-thought logging trade-offs: empirical assessment of privacy/IP risks vs transparency benefits, and alternatives (structured rationales, policy graphs) that retain auditability without sensitive content exposure.
- Benchmarks for verifiable planning and self-correction: tasks with automatically checkable outputs, embedded unit tests/contracts, and measures of recovery from tool or reasoning errors.
- Lifecycle management of agents: update policies, memory migration, drift monitoring, decommissioning procedures, and their effects on safety and continuity.
- Interaction effects between alignment techniques (RLHF, instruction tuning) and agentic behaviors (tool use, reflection, planning), including failure cases where alignment reduces task performance or reliability.
- Cost-aware orchestration strategies: dynamic model/tool selection, partial execution, caching, and subgoal pruning to minimize compute while maintaining performance and safety.
- Standard interfaces and schemas (APIs, tool ontologies, memory records) to enable interoperability across agent frameworks and facilitate auditing, portability, and compliance.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed today by combining the paper’s reason–act–reflect loops, memory-augmented retrieval, tool calling, and single-/multi-agent orchestration with human-in-the-loop guardrails and monitoring.
- Bold sector co-pilots for enterprise knowledge work (software, legal, consulting, healthcare administration)
- What it does: Uses RAG with vector databases, a ReAct loop, and tool invocation to answer domain questions, assemble briefs, and triage information across internal document stores.
- Tools/workflows: LangChain (single-agent orchestration), ReAct-style tool calls, vector DBs for memory, policy guardrails for permissions, retrieval re-ranking and chunking strategies (as emphasized by the paper).
- Dependencies/assumptions: Clean document indexing; role-based access to data; audit logging; human approval for high-impact actions; sufficient retrieval quality.
- Multi-agent literature review and report generation (academia, pharma R&D, competitive intelligence)
- What it does: Planner–Researcher–Writer–Reviewer agents coordinate to collect sources, summarize evidence, synthesize drafts, and iteratively revise output.
- Tools/workflows: AutoGen (multi-agent), ReAct within each agent, API access to scholarly search, memory for citation tracking.
- Dependencies/assumptions: Access to paywalled content or institutional proxies; rubric-based evaluation; human editorial review for claims and citations.
- Communicative agents for software engineering and DevOps (software, platform teams)
- What it does: Plan tasks, propose code changes, run tests, open PRs, and draft release notes with multi-agent handoffs (planner, coder, tester, reviewer).
- Tools/workflows: AutoGen multi-agent conversations; CI/CD integration; repository and issue-tracker APIs; unit/integration test tool calls.
- Dependencies/assumptions: Repository permissioning and branch protections; mandatory code review gates; test coverage; rollback procedures.
- Customer support triage and reversible action agents (SaaS, telecom, finance)
- What it does: Classifies tickets, retrieves KB answers, drafts responses, and executes reversible low-risk actions (e.g., credit reissuance) under guardrails.
- Tools/workflows: ReAct loop with CRM and ticketing APIs; long-context memory for prior customer interactions; policy enforcement layers and “two-person” approvals for refunds.
- Dependencies/assumptions: Clear authorization scopes; audit logs; escalation to humans for edge cases; culturally and linguistically aligned prompts.
- Financial analysis copilots with explicit tool use (finance, FP&A, fintech)
- What it does: Performs what-if analyses, computes rates or interest, validates constraints, and explains assumptions, following Reason–Act–Reflect.
- Tools/workflows: ReAct with calculator/data APIs; memory of scenarios; risk disclaimers templating.
- Dependencies/assumptions: Reliable market/data feeds; regulatory-compliant disclosures; human sign-off for recommendations.
- Natural-language-to-robot command bridges in constrained settings (robotics in warehousing, labs)
- What it does: Translates operator intent into structured robot commands and sequences in controlled environments (e.g., pick/place, routine inspection).
- Tools/workflows: ROSGPT-style language-to-ROS pipelines; simulation-in-the-loop validation; “dry run” mode before live execution.
- Dependencies/assumptions: Safety fences and geofencing; conservative action sets; human oversight; standardized affordances for tasks.
- Personalized tutoring and content generation with memory (education, corporate L&D)
- What it does: Generates quizzes, stepwise explanations, and adaptive learning paths by retrieving curriculum-aligned materials and reflecting on learner performance.
- Tools/workflows: RAG for curriculum content; episodic memory to track learner progress; ReAct for task decomposition.
- Dependencies/assumptions: Alignment with standards/curricula; content filtering; privacy controls for learner data.
- Compliance-aware agent guardrails and auditability layers (regulated industries)
- What it does: Enforces reversible actions, permission scopes, and policy checks around agent tool calls; logs all reasoning and actions for audit.
- Tools/workflows: Execution sandboxes; policy engines; action justification and rollback; human checkpoints for sensitive operations.
- Dependencies/assumptions: Machine-readable policies; IAM integration; storage for secure logs; regulator-ready audit trails.
- Memory/RAG optimization as a productized capability (cross-sector)
- What it does: Improves retrieval fidelity and cost via chunking, re-ranking, and vector store tuning to stabilize long-horizon agent reasoning.
- Tools/workflows: Vector DB configuration pipelines; retrieval evaluation harnesses; domain-specific knowledge bases.
- Dependencies/assumptions: High-quality domain corpora; continuous evaluation; data governance for sensitive content.
- Agent observability and reliability monitoring (enterprise ML/AI Ops)
- What it does: Tracks multi-step plans, tool-call success rates, latency/cost, and error cascades; supports reproducible runs and incident response.
- Tools/workflows: Telemetry for reason–act–reflect cycles; action trace visualization; sandbox/replay; SLA dashboards.
- Dependencies/assumptions: Privacy-respecting logging (e.g., redaction); organizational norms for monitoring; non-determinism-aware playbooks.
- Cost- and energy-aware agent routing (sustainability in software/IT)
- What it does: Dynamically selects model size and tool pathways based on task complexity, budget, and latency targets to reduce environmental footprint.
- Tools/workflows: Adaptive inference policies; tool orchestration cost models; caching and retrieval-first strategies.
- Dependencies/assumptions: Performance/cost telemetry; acceptance of variable fidelity modes; fallback to human handling for ambiguous cases.
Long-Term Applications
These opportunities rely on advances the paper identifies as research priorities: verifiable planning, scalable multi-agent coordination, persistent memory, and governance frameworks.
- Verifiable planning and execution with hybrid symbolic–neural agents (healthcare, aviation, finance)
- What it could deliver: Formal guarantees on plans, bounded behavior, and interpretable decision traces for safety-critical workflows.
- Tools/workflows: Symbolic planners + LLM reasoning; correctness certificates; runtime verification.
- Dependencies/assumptions: Scalable formal methods; standardized task ontologies; regulator acceptance.
- Enterprise-scale autonomous multi-agent organizations (supply chain, operations, logistics)
- What it could deliver: Teams of specialized agents negotiating tasks (procurement, scheduling, pricing) with conflict resolution and dynamic role assignment.
- Tools/workflows: Multi-agent protocols (AutoGen-like), shared memory/KBs, market-style coordination or contract nets.
- Dependencies/assumptions: Incentive alignment, cross-team governance, robust coordination under uncertainty.
- Lifelong, privacy-preserving agent memory (personal assistants, CRM)
- What it could deliver: Stable identity, long-horizon goals, and consistent preferences across months/years without privacy leakage or drift.
- Tools/workflows: Hierarchical memory (working/episodic/long-term), controlled forgetting, confidence thresholds, selective retention.
- Dependencies/assumptions: Consent/granular data rights; privacy-preserving storage; safeguards against hallucinated recall.
- Autonomously orchestrated scientific discovery and lab automation (pharma, materials)
- What it could deliver: Hypothesis generation, experiment design, robotic execution, analysis, and iterative refinement with minimal supervision.
- Tools/workflows: Multi-agent planners + lab robots; literature synthesis; active learning loops.
- Dependencies/assumptions: Reliable tool use; lab safety interlocks; reproducibility; ethical oversight.
- Embodied service robots with natural-language autonomy (healthcare, hospitality, smart factories)
- What it could deliver: Robust language-grounded manipulation and navigation in dynamic human environments.
- Tools/workflows: Language-to-affordance grounding; simulation-to-reality transfer; safety certification toolchains.
- Dependencies/assumptions: Improvements in perception and control; certification standards; fail-safe behaviors.
- Regulatory sandboxes and certification schemes for agentic AI (public policy, compliance)
- What it could deliver: Tiered permissioning, standardized safety tests, and pathway-to-approval for autonomous actions.
- Tools/workflows: Alignment benchmarks; conformance tests; audit and override protocols; permission frameworks.
- Dependencies/assumptions: Multi-stakeholder consensus on metrics; legal clarity on accountability and liability.
- Cross-lingual and culturally grounded evaluation suites (global deployments)
- What it could deliver: Reliable measurement of reasoning accuracy and cultural alignment across languages and regions.
- Tools/workflows: Localized datasets and tasks; human-in-the-loop evaluation; continual benchmarks.
- Dependencies/assumptions: Community data partnerships; quality assurance; bias mitigation and inclusivity.
- Energy-aware agentic stacks and hardware–software co-design (cloud, edge)
- What it could deliver: Large-scale agent orchestration with carbon-aware scheduling, sparse attention, and model specialization.
- Tools/workflows: Adaptive compute schedulers; retrieval-augmented context management; on-device inference when feasible.
- Dependencies/assumptions: Hardware support; reliable routing policies; standardized telemetry for energy metrics.
- Marketplaces of tools, skills, and policies for agent orchestration (software platforms)
- What it could deliver: Plug-and-play tool ecosystems with standard contracts, identity, and permissioning for agent tool calls.
- Tools/workflows: Tool schemas; capability registries; policy-as-code modules; revenue-sharing models.
- Dependencies/assumptions: Interoperability standards; robust authentication; governance for safety and IP.
- Constrained-autonomy financial agents with provable risk controls (finance)
- What it could deliver: Agents managing hedging, liquidity, and compliance checks under strict guardrails and formal risk bounds.
- Tools/workflows: Verifiable planning; kill-switches; continuous risk monitoring.
- Dependencies/assumptions: Regulator-approved control frameworks; high-fidelity data; human oversight for exceptions.
- Long-horizon educational co-instructors (education)
- What it could deliver: Multi-month curricula planning, formative assessment, and adaptive interventions grounded in persistent learner models.
- Tools/workflows: Hierarchical memory; reflective tutoring loops; standards-aligned content generation.
- Dependencies/assumptions: Long-term memory reliability; fairness and accessibility; district-level approvals.
- Clinically validated decision-support agents (healthcare)
- What it could deliver: Agents that plan diagnostics, retrieve guidelines, coordinate tools, and justify recommendations with audit-ready traces.
- Tools/workflows: Hybrid symbolic–LLM reasoning; EHR tool integration; explanation requirements.
- Dependencies/assumptions: Clinical trials; bias audits; FDA/CE approvals; strict PHI handling.
- Government operations assistants (public sector)
- What it could deliver: Case management triage, benefits eligibility pre-screening, procurement planning with transparent, reversible actions.
- Tools/workflows: Policy guardrails; transparent logs; human checkpoints; explainability.
- Dependencies/assumptions: Legal frameworks for autonomy levels; accessibility and language coverage; data-sharing agreements.
Glossary
- Agentic AI: AI systems that can autonomously plan, decide, use tools, and adapt to achieve goals. "Agentic AI refers to systems capable of autonomous decision-making, tool use, planning, and adaptive behavior to achieve specific goals"
- Auditability: The ability to trace and review an agent’s reasoning and actions for oversight and rollback. "Auditability: enabling traceability through mandatory chain-of-thought logs, action justification, and rollback capabilities."
- AutoGen: An open-source framework for multi-agent LLM applications that enables coordinated conversations and collaboration among agents. "Recent frameworks such as LangChain and AutoGen operationalize these ideas."
- Belief–Desire–Intention (BDI): A classical symbolic agent architecture that models an agent’s beliefs, goals (desires), and plans (intentions) for deterministic reasoning. "Examples include BeliefâDesireâIntention (BDI) models and senseâplanâact (SPA) pipelines"
- Chain-of-thought: A prompting/decoding technique where models generate intermediate reasoning steps to improve problem solving. "such as chain-of-thought, reflective refinement, and tool-calling strategies"
- Closed-loop control architecture: A system design where perception, reasoning, action, and feedback iteratively inform each other for continuous adaptation. "Together, these elements form a closed-loop control architecture in which the LLM does not merely generate text but continuously plans, acts, and adapts based on feedback"
- Controllable autonomy: Constraining an agent’s permissions or scope to maintain safety and oversight during autonomous operation. "Controllable autonomy: restricting agent permissions through role-based, time-bounded, and context-aware execution constraints."
- Emergent reasoning: Reasoning capabilities that arise in large models without being explicitly programmed, often appearing at scale. "to achieve strong few-shot generalization and emergent reasoning."
- Episodic memory: Memory of specific interactions or events that persists across steps or sessions to support long-horizon tasks. "episodic or long-term memory enables persistence across steps or sessions."
- Episodic recall mechanisms: Methods for retrieving contextually relevant past interactions or memories to maintain consistency and reduce hallucination. "Episodic recall mechanisms: retrieving memories based on context and particular tasks, interactions, or time-frames rather than relying on mixed long-term memory maintains contextual accuracy, consistency and reduces hallucination."
- Few-shot generalization: A model’s ability to perform new tasks from a small number of examples or prompts. "to achieve strong few-shot generalization and emergent reasoning."
- Governance frameworks: Policies and structures for oversight, compliance, and accountability of autonomous AI systems. "We identify critical research priorities, including verifiable planning, scalable multi-agent coordination, persistent memory architectures, and governance frameworks."
- Guardrails: Safety and policy layers that constrain LLM/agent behavior and monitor workflows. "guardrails for safe execution and workflow monitoring."
- Hierarchical memory architectures: Memory designs separating short-term, episodic, and long-term knowledge to reduce interference and drift. "Hierarchical memory architectures: separating short-term working memory, episodic memory, and long-term knowledge stores, can reduce interference across extended interactions."
- Human-in-the-loop: Involving human supervision or intervention points within an autonomous agent’s decision process. "agentic AI frameworks that integrate structured planning, tool use, modular decision pipelines, and human-in-the-loop control"
- Hybrid symbolic–neural systems: Approaches that combine symbolic reasoning/planning with neural LLMs to improve verifiability and adaptability. "Research on verifiable reasoning, uncertainty calibration, and hybrid symbolicâneural systems aims to mitigate these challenges"
- Instruction tuning: Fine-tuning LLMs on instruction-following datasets to align outputs with user intent and safe behavior. "Reinforcement Learning from Human Feedback (RLHF) \cite{lambert2025reinforcementlearninghumanfeedback} and instruction tuning enabled goal-directed behavior and safer interaction"
- LangChain: A framework that supports single-agent control, tool integration, and memory for building LLM applications. "Recent frameworks such as LangChain and AutoGen operationalize these ideas."
- Long Short-Term Memory (LSTM): A recurrent neural network architecture designed to capture longer-range dependencies via gated memory cells. "Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) models \cite{mikolov2010rnn} enhanced the effective context length through learned internal memory"
- Mixture-of-Experts (MoE) routing: A sparse modeling technique that routes tokens to specialized expert networks to improve efficiency and capacity. "Mixture-of-Experts (MoE) routing \cite{mu2025comprehensivesurveymixtureofexpertsalgorithms}"
- Multi-agent coordination: Protocols and mechanisms for communication, role assignment, and conflict resolution among multiple agents. "We identify critical research priorities, including verifiable planning, scalable multi-agent coordination, persistent memory architectures, and governance frameworks."
- Multi-agent system: An architecture where multiple specialized agents collaborate through communication and role specialization. "Agentic AI may involve a single autonomous agent or a coordinated multi-agent system"
- Multi-head attention: A transformer mechanism that uses multiple attention “heads” to capture diverse relationships in parallel. "Innovations such as positional encodings, multi-head attention, and early forms of sparse attention"
- Ontology-based interpretation: Using structured vocabularies/ontologies to map natural language to formal representations for reliable action. "through prompt engineering and ontology-based interpretation"
- Policy-enforcement tools: Software mechanisms that enforce policies and constraints on agent actions to prevent unsafe behavior. "Structured guardrails: integrating policy-enforecement tools, safety layers and reversible actions to prevent unsafe behavior."
- Positional encodings: Injecting sequence order information into transformer inputs to enable attention over ordered tokens. "Innovations such as positional encodings, multi-head attention, and early forms of sparse attention"
- ReAct: A framework that interleaves reasoning traces with tool calls to implement reason–act–reflect loops in LLM agents. "Frameworks like ReAct \cite{yao2023react} and Toolformer \cite{Schick2023} implement this loop by explicitly interleaving reasoning traces with tool calls."
- Re-ranking mechanisms: Techniques that reorder retrieved documents or results to improve relevance before generation or action. "hyperparameter optimization in vector stores, chunking strategies, and re-ranking mechanisms"
- Recurrent Neural Network (RNN): A neural architecture that processes sequences by maintaining a hidden state across time steps. "Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) models \cite{mikolov2010rnn} enhanced the effective context length"
- Reinforcement Learning from Human Feedback (RLHF): Fine-tuning with human preference signals to align model outputs with desired behavior. "Reinforcement Learning from Human Feedback (RLHF) \cite{lambert2025reinforcementlearninghumanfeedback} and instruction tuning enabled goal-directed behavior and safer interaction"
- Retrieval-Augmented Generation (RAG): Augmenting LLMs with retrieved external knowledge to improve accuracy and grounding. "Recent work on Retrieval-Augmented Generation (RAG) demonstrates that hyperparameter optimization in vector stores, chunking strategies, and re-ranking mechanisms significantly impacts both retrieval quality and system efficiency"
- Scaling laws: Empirical relationships showing how model performance scales with compute, data, and parameters. "The 2020s marked a shift toward large-scale models guided by scaling laws, extensive training pipelines, and advanced alignment techniques."
- Self-attention: The transformer operation that relates positions within a sequence to each other to compute context-aware representations. "The transformer architecture \cite{vaswani2017attention} replaced recurrence with self-attention, enabling parallel computation, global context integration, and scalable depth."
- Sense–plan–act (SPA) pipeline: A classical AI pipeline that senses the environment, plans using a world model, and executes actions deterministically. "Examples include BeliefâDesireâIntention (BDI) models and senseâplanâact (SPA) pipelines"
- Sparse attention: Attention mechanisms that limit computation to a subset of tokens to handle longer contexts more efficiently. "Innovations such as positional encodings, multi-head attention, and early forms of sparse attention"
- Tool-calling strategies: Patterns that enable LLMs to decide when and how to invoke external tools/APIs during reasoning. "such as chain-of-thought, reflective refinement, and tool-calling strategies"
- Toolformer: A method where LLMs learn to use external tools via self-supervised signals during training. "Frameworks like ReAct and Toolformer implement this loop by explicitly interleaving reasoning traces with tool calls."
- Uncertainty calibration: Techniques to align a model’s confidence with the actual likelihood of correctness to improve reliability. "Research on verifiable reasoning, uncertainty calibration, and hybrid symbolicâneural systems aims to mitigate these challenges"
- Vector database: A storage system for vector embeddings enabling similarity search and memory retrieval in agents. "Examples include vector databases, scratchpads, and domain-specific knowledge bases."
- Word2Vec: An algorithm that learns distributed word embeddings capturing semantic similarity from large text corpora. "while Word2Vec \cite{mikolov2013word2vec} produced scalable and reusable embeddings."
Collections
Sign up for free to add this paper to one or more collections.