One Layer Is Enough: Adapting Pretrained Visual Encoders for Image Generation
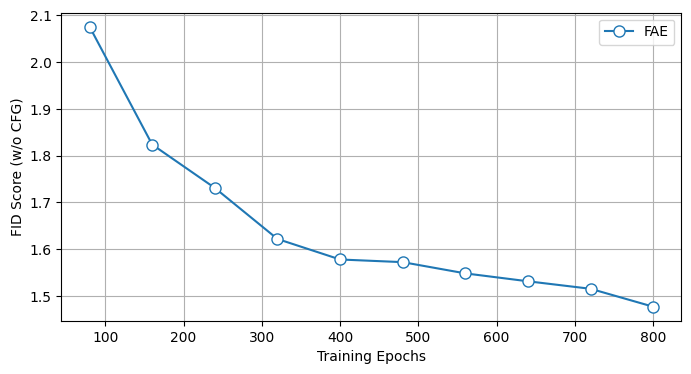
Abstract: Visual generative models (e.g., diffusion models) typically operate in compressed latent spaces to balance training efficiency and sample quality. In parallel, there has been growing interest in leveraging high-quality pre-trained visual representations, either by aligning them inside VAEs or directly within the generative model. However, adapting such representations remains challenging due to fundamental mismatches between understanding-oriented features and generation-friendly latent spaces. Representation encoders benefit from high-dimensional latents that capture diverse hypotheses for masked regions, whereas generative models favor low-dimensional latents that must faithfully preserve injected noise. This discrepancy has led prior work to rely on complex objectives and architectures. In this work, we propose FAE (Feature Auto-Encoder), a simple yet effective framework that adapts pre-trained visual representations into low-dimensional latents suitable for generation using as little as a single attention layer, while retaining sufficient information for both reconstruction and understanding. The key is to couple two separate deep decoders: one trained to reconstruct the original feature space, and a second that takes the reconstructed features as input for image generation. FAE is generic; it can be instantiated with a variety of self-supervised encoders (e.g., DINO, SigLIP) and plugged into two distinct generative families: diffusion models and normalizing flows. Across class-conditional and text-to-image benchmarks, FAE achieves strong performance. For example, on ImageNet 256x256, our diffusion model with CFG attains a near state-of-the-art FID of 1.29 (800 epochs) and 1.70 (80 epochs). Without CFG, FAE reaches the state-of-the-art FID of 1.48 (800 epochs) and 2.08 (80 epochs), demonstrating both high quality and fast learning.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making computer models that create images (like drawings or photos) work better and faster by reusing knowledge from powerful “vision” models that already understand images well. The authors show that you only need a very small change—just one attention layer—to adapt those understanding models into a compact form that is great for image generation.
What is the paper trying to find out?
The authors ask a simple question: Can we turn the features (knowledge) from big, pre-trained image understanding models into a small, efficient “code” that image generators like diffusion models can use—without building complicated systems?
They focus on solving this mismatch:
- Image understanding models like DINO or SigLIP use big, high-dimensional features (lots of numbers) to capture detailed meanings.
- Image generators (like diffusion models) work better with small, low-dimensional codes (fewer numbers), especially when they add and remove noise step-by-step.
The goal is to keep the important meaning from the big models, but convert it into a smaller form that generators can use smoothly.
How did they do it? (Methods explained simply)
Think of an image as being split into many small patches (like tiles). A pre-trained model looks at these tiles and creates rich “features” that say what’s in the image—like textures, shapes, and objects.
The authors propose three main ideas:
- A single attention layer as the encoder:
- Attention is a mechanism that helps the model “look around” and decide which parts of the image are important and how they relate.
- They use just one attention layer plus a simple linear projection to compress the big features into a smaller code (called a latent). This is like summarizing a long paragraph into a few sentences—but without losing key meaning.
- A “double decoder” setup:
- Feature decoder: First, they use a small Transformer (a type of neural network) to reconstruct the original rich features from the small code. This ensures the small code still contains the understanding and structure of the pre-trained model.
- Pixel decoder: Then, they turn those reconstructed features into actual images (RGB pixels). Think of it like first translating a summary back into the original “language,” and then turning that language into a picture.
- Plug into popular generators:
- They train common image generators (diffusion models and normalizing flows) to work directly on this small code. Because the code is compact, training is faster and more stable.
- No fancy tricks or big changes are needed—just swap in the new compact code.
Simple analogies:
- Latent space: Imagine a short note that captures the essence of a long article—small but meaningful.
- Diffusion model: Picture starting with a very noisy image and cleaning it up step by step until it looks real.
- Normalizing flow: Think of a smooth function that transforms random noise directly into a realistic image.
What did they find, and why does it matter?
Here are the main results and their importance:
- Strong image quality at low cost:
- On ImageNet (256×256), their diffusion model reaches very low FID scores (a measure of how close generated images are to real ones, lower is better):
- Without extra guidance (CFG): FID 2.08 after 80 epochs and 1.48 after 800 epochs—state-of-the-art for unguided sampling.
- With CFG (Classifier-Free Guidance, a common trick to improve image fidelity): FID 1.70 after 80 epochs and 1.29 after 800 epochs—near state-of-the-art.
- Fast learning:
- Good results after relatively few training epochs (e.g., 80), showing the method learns quickly.
- Works across model families:
- The compact code integrates smoothly with both diffusion models and normalizing flows, improving speed and quality in both.
- Keeps semantic understanding:
- Even after compression, the code still preserves detailed relationships between image parts (like matching the “head” region across different animal photos).
- It supports tasks like linear probing and image–text retrieval, showing the understanding features remain useful.
Why it matters:
- Fewer changes, simpler systems, and faster training make it easier for researchers and engineers to build high-quality image generators.
- Reusing large pre-trained encoders without heavy redesign saves time and compute resources.
What does this mean for the future?
- Easier and more efficient generative models:
- If “one layer is enough” to adapt strong vision features into generator-friendly codes, many future systems could be simpler and cheaper to train.
- Better multi-purpose vision:
- Because the compact code still remembers semantic meaning, the same setup can help both understanding tasks (like recognizing objects) and generation tasks (like making images from text).
- Broad compatibility:
- This method works with different encoders (like DINO and SigLIP) and different generators (diffusion and flows), so it’s a flexible building block for many image AI projects.
In short, the paper shows a clean, minimal way to bridge the gap between “understanding images” and “creating images.” With just one attention layer and two decoders, you can get fast, high-quality generation while keeping the brainy parts of pre-trained models intact.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be concrete and actionable for future research.
- Formal justification for why a single self-attention layer is sufficient. Quantify information retention and redundancy removal (e.g., mutual information, CKA across layers) between pretrained features, compressed latents
z, and reconstructed featuresx̂. - Sensitivity to the choice of pretrained encoders. Evaluate FAE across a broader spectrum (MAE, CLIP/ViT, DeiT, ConvNeXt, Swin, multimodal encoders) and encoder scales/data domains to test generality and failure modes when the pretrained representation is weaker or out-of-domain.
- Latent dimensionality trade-offs. Systematically map generation quality, reconstruction fidelity, and semantic preservation vs.
dim(z)(e.g., 16–128), including compute/memory costs, training stability, and convergence speed; derive an automatic criterion for selectingdim(z). - Prior and KL regularization. Specify and ablate the latent prior
p(z)and the KL weightβ. Test learned priors (e.g., VampPrior, flow-based priors) and analyze howβshifts the reconstruction–generation trade-off and semantic preservation. - Feature decoder architecture. Ablate depth/width, attention types, positional encodings (RoPE variants), normalization, and residual patterns; quantify how these choices affect reconstruction quality and downstream understanding (linear probing, retrieval).
- Pixel decoder training details and robustness. Clarify the datasets used, augmentation regime, and optimizer; ablate the noise level
σand schedule used for “Gaussian embedding decoder,” and measure pixel-level reconstruction metrics (PSNR, SSIM, LPIPS, rFID) comparing FAE vs. VA-VAE/RAE. - Joint vs. staged training. Investigate end-to-end training that jointly optimizes the single-layer encoder, feature decoder, pixel decoder, and generator; develop strategies (e.g., frozen-backbone schedules or consistency losses) to avoid catastrophic forgetting while improving alignment.
- Sampling efficiency–quality curves. Beyond fixing 250 sampling steps (SDE/ODE), characterize quality vs. steps for different samplers and parameterizations (
ε-,v-,x0-prediction), including wall-clock time, throughput, and memory, to substantiate the claimed efficiency. - High-resolution scalability. Extend experiments from 256×256 to 512/1024+; evaluate multi-scale or hierarchical latents and feature reconstruction fidelity at higher resolutions; analyze whether a single attention layer remains adequate at larger scales.
- Text-to-image evaluation breadth. Complement COCO FID with CLIP score, TIFA, HPSv2, compositionality tests, prompt adherence, and human evaluation; study alignment robustness for long, complex prompts and rare/novel concepts.
- Robustness and domain transfer. Test semantic preservation and generation under distribution shifts (ImageNet-A/O/R, Stylized ImageNet), occlusions, strong augmentations, and geometric/photometric perturbations; quantify failure modes.
- Generator-family coverage. Evaluate compatibility with autoregressive transformers and additional normalizing flows; analyze whether FAE’s low-dimensional latents systematically improve training stability across these families.
- Timestep shift mechanism. Provide an explicit formulation (loss weighting, schedule, and trajectory changes), theoretical motivation, and comprehensive ablations to explain why it narrows performance gaps across latent dimensions and accelerates convergence.
- Token grid and spatial mapping. Justify the choice of 16×16×32 latent grids and patch size/stride; ablate overlapping tokens, variable strides, and grid shapes on fine-grained detail recovery and generation fidelity.
- Register tokens usage. The paper mentions a “register version” of FAE without describing what registers are, how they are integrated, and their impact; add a clear specification and ablation.
- Quantitative semantic preservation. Beyond visualizations, quantify relational geometry retention (e.g., CKA across layers, patch-level matching accuracy, part-level correspondence metrics) and evaluate multiple understanding tasks (segmentation, detection, dense matching).
- Fairness and reproducibility. Standardize baselines and training budgets (epochs, data size, batch size), report compute (FLOPs/GPU-hours), memory, and all configs; some current comparisons mix different datasets/epochs, impeding fair conclusions.
- Extension beyond images. Validate FAE on video (temporal tokens), 3D (point clouds, NeRF latents), and audio spectrograms; study whether a single attention layer can generalize across modalities and sequence lengths.
- Dependence on pretrained representation quality. Analyze how FAE behaves when the upstream encoder is suboptimal (smaller models, limited data, domain mismatch); quantify performance degradation and potential remedies (light fine-tuning, adapters).
- Bridging rFID/tokenizer fidelity gap. The paper notes lagging reconstruction/tokenizer fidelity vs. VA-VAE; explore adding explicit image-level reconstruction losses, multi-layer feature matching, or perceptual distillation to close this gap without harming generation.
- Noise-injection calibration. Calibrate embedding noise
σto diffusion noise schedules or learned per-layer noise; ablate whether matching the generative noise statistics improves robustness and sampling quality. - Synergy with alignment objectives. Although FAE avoids complex alignment losses, test whether lightweight auxiliary objectives (e.g., feature-level contrastive alignment, teacher–student distillation across timesteps) further improve stability or quality.
Practical Applications
Overview
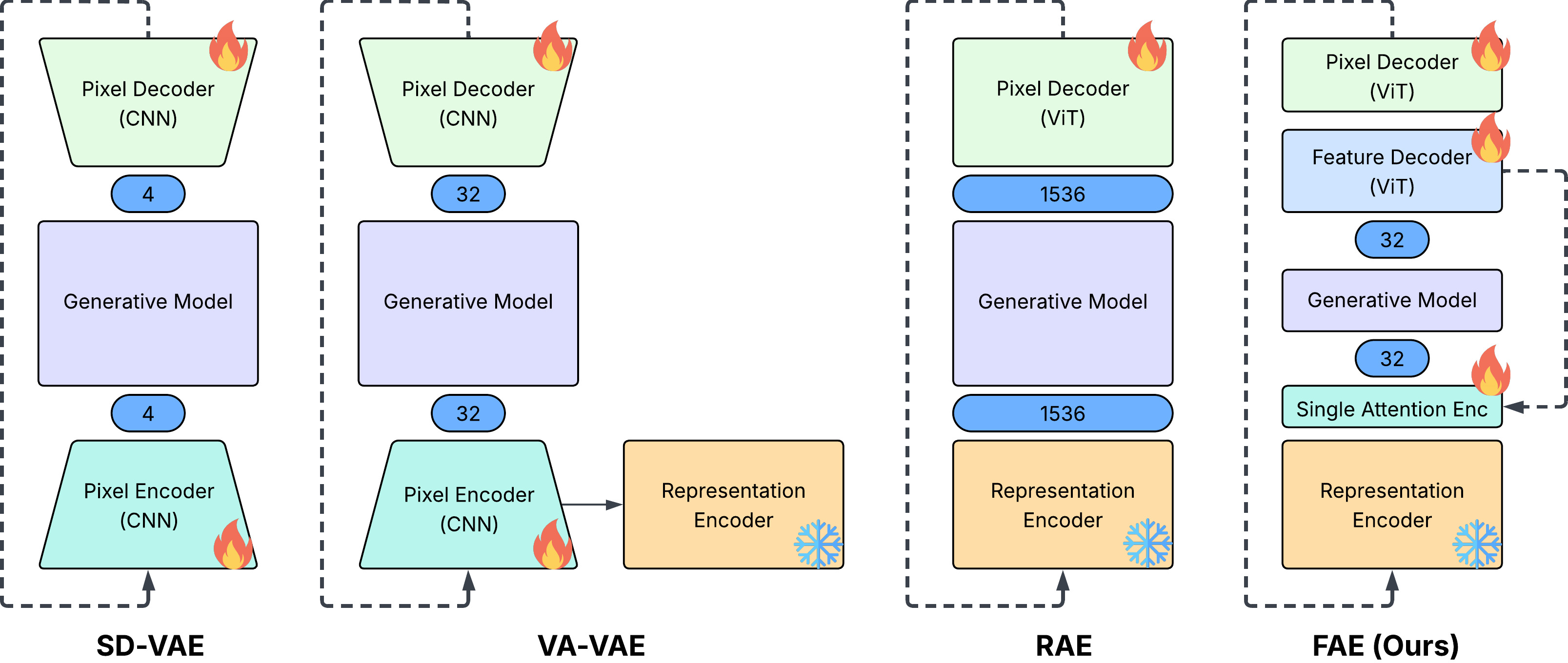
Based on the paper “One Layer Is Enough: Adapting Pretrained Visual Encoders for Image Generation,” the key practical contribution is a minimal, robust way to convert high-dimensional features from strong self-supervised encoders (e.g., DINOv2, SigLIP2) into low-dimensional, generation-ready latents using only a single attention layer, plus a two-stage “double-decoder” that first reconstructs the original feature space and then translates features to pixels. This yields a compact latent interface that:
- Preserves semantic structure useful for understanding tasks.
- Trains faster and more stably for generators (diffusion, flows).
- Is architecture-agnostic and easy to plug into existing pipelines.
Below are actionable applications, organized by time horizon.
Immediate Applications
These can be deployed now with modest engineering effort using current tools and data scales cited in the paper.
- Sector: Software/AI Platforms
- Use case: Drop-in replacement for VAEs in latent diffusion/flow pipelines to reduce training cost and improve convergence.
- Tools/products/workflows:
- Replace SD-VAE-like tokenizers with FAE latents (e.g., 16×16×32 for 256×256 training).
- Train SiT/DiT or STARFlow directly on FAE latents without architecture changes; keep CFG/timestep schedulers.
- Precompute latents z for datasets to accelerate repeated training runs and A/B experiments.
- Assumptions/dependencies:
- Access to pretrained visual encoders (e.g., DINOv2-g/14, SigLIP2) with compatible licenses.
- Pixel decoder training per domain, following Stage Ia/Ib in the paper.
- Existing diffusion/flow codebases (DiT/SiT/LightningDiT, STARFlow).
- Sector: Creative industries (advertising, media, game art)
- Use case: Faster training and fine-tuning for class-conditional and text-to-image models under constrained budgets.
- Tools/products/workflows:
- Fine-tune generators on brand/product imagery using compact FAE latents for rapid iteration.
- Reuse a single Gaussian embedding pixel decoder across multiple domains and adapt with light fine-tuning.
- Assumptions/dependencies:
- Text encoder quality (e.g., T5) and limited data (e.g., CC12M) may cap absolute SOTA; guided sampling (CFG) recommended.
- Sector: Mobile/Edge (on-device ML, AR/VR prototyping)
- Use case: Memory-efficient latent interface and smaller feature tensors for on-device image synthesis prototypes.
- Tools/products/workflows:
- Run the single-layer attention encoder on-device to compress camera frames into z for local editing/filters.
- Offload heavier generative steps to edge servers while passing compact z to reduce bandwidth.
- Assumptions/dependencies:
- Current sampling (≈250 steps) may still be heavy for full on-device generation; best suited for hybrid edge/offload.
- Sector: Data platforms and MLOps
- Use case: Semantic-preserving feature compression for storage, indexing, and retrieval.
- Tools/products/workflows:
- Store FAE latents instead of full-resolution images for internal analytics or model training caches.
- Use reconstructed features for zero-shot retrieval (COCO T→I/I→T parity with SigLIP2 reported).
- Assumptions/dependencies:
- Internal governance on storing compressed representations of potentially sensitive images.
- Monitoring of fidelity vs. task performance; slight drops vs. original encoder are possible.
- Sector: Enterprise ML (synthetic data)
- Use case: Cost-effective synthetic dataset generation for downstream training (classification, detection).
- Tools/products/workflows:
- Train class-conditional generators on FAE latents to create balanced/rare classes.
- Validate with linear probing and retrieval on reconstructed features before deployment.
- Assumptions/dependencies:
- Need domain-specific validation for bias/coverage; ensure synthetic data labeling and governance.
- Sector: Content safety and moderation
- Use case: Latent-space pre-filters and semantic checks that operate on compact, semantically faithful z.
- Tools/products/workflows:
- Build NSFW/violent-content classifiers on FAE z or reconstructed features to gate generation requests.
- Audit patch-level correspondences (preserved by FAE) to enable part-level safety checks.
- Assumptions/dependencies:
- Safety classifiers must be trained/evaluated in the same latent/reconstruction space.
- Sector: Academia/Research
- Use case: Rapid prototyping for generative model research and teaching.
- Tools/products/workflows:
- Use FAE to unify diffusion and flow experiments on the same latent interface.
- Demonstrate ablation lessons (single-layer beats deep encoders for adaptation) in coursework.
- Assumptions/dependencies:
- Public availability of pretrained encoders and standard datasets (ImageNet, COCO, CC12M).
- Sector: E-commerce
- Use case: Fast re-styling and upscaling of product images with semantic consistency.
- Tools/products/workflows:
- Train pixel decoders conditioned on reconstructed features for style transfer/editing workflows.
- Assumptions/dependencies:
- Requires domain-tuned pixel decoder; text alignment depends on text encoder quality.
Long-Term Applications
These require further research, scaling, or productization (e.g., fewer sampling steps, stronger text alignment, broader safety coverage).
- Sector: Mobile/Edge and Consumer Devices
- Use case: Real-time or near-real-time on-device generation for photo/video apps.
- Tools/products/workflows:
- Integrate FAE latents with distilled diffusion or flow samplers (few steps) or with efficient samplers and schedulers.
- Hardware-aware implementations of the single attention encoder + feature decoder.
- Assumptions/dependencies:
- Requires step-reduction/distillation or flow models optimized for mobile NPUs/GPUs.
- Sector: Multimodal systems (vision-language)
- Use case: Stronger text-to-image alignment and controllability via joint latent-space training.
- Tools/products/workflows:
- Co-train FAE with modern text encoders; explore cross-attention or shared token spaces.
- Develop editing tools that manipulate semantic patches (leveraging preserved patch-level correspondences).
- Assumptions/dependencies:
- Larger, cleaner multimodal corpora; controllable generation objectives; safety alignment.
- Sector: Video and 3D/NeRF/Graphics
- Use case: Extending FAE to video latents and 3D asset generation for simulation, VFX, and robotics.
- Tools/products/workflows:
- Temporal FAEs that preserve spatiotemporal semantics; plug into flow/diffusion video generators.
- Latent conditioning for 3D/NeRF pipelines to generate textures and environmental assets.
- Assumptions/dependencies:
- Temporal consistency objectives; large-scale video data; efficient decoders.
- Sector: Healthcare
- Use case: Privacy-preserving synthetic augmentation and feature storage for medical imaging.
- Tools/products/workflows:
- Train domain-specific FAEs (radiology, pathology) to create compact latents for federated training and synthetic augmentation.
- Assumptions/dependencies:
- Rigorous clinical validation, bias assessment, and regulatory approvals; strong privacy guarantees.
- Sector: Federated and Privacy-preserving ML
- Use case: Sharing or learning from compact latents instead of raw images.
- Tools/products/workflows:
- On-device FAE encoders to send z or gradients to servers; server-side generation or training on z.
- Assumptions/dependencies:
- Formal privacy analysis (z may still be reconstructable); differential privacy or secure aggregation may be needed.
- Sector: Policy and Standards
- Use case: Standardized latent interchange formats to reduce vendor lock-in and improve auditability.
- Tools/products/workflows:
- Define schemas and benchmarks for semantic-preserving latents; establish energy/performance reporting standards for training on z.
- Latent-space watermarking and provenance tracking embedded in z or reconstructed features.
- Assumptions/dependencies:
- Multi-stakeholder agreement (academia, industry, standards bodies); legal frameworks for synthetic content labeling.
- Sector: Content safety and forensics
- Use case: Latent-level watermarking, provenance, and misuse detection for generative media.
- Tools/products/workflows:
- Encode traceable signatures in z that persist through pixel decoding; robust detectors operating on reconstructed features.
- Assumptions/dependencies:
- Research on robustness to editing/compression; policy adoption of provenance standards.
- Sector: Robotics and Simulation
- Use case: Asset and environment generation with controllable semantics and low compute.
- Tools/products/workflows:
- Use FAE latents to rapidly craft scene variations for sim2real transfer and perception stress-testing.
- Assumptions/dependencies:
- Validation that generated content improves downstream control/perception; task-specific generators.
- Sector: Enterprise Search and Knowledge Management
- Use case: Cross-modal retrieval and semantic search over large image libraries using compact representations.
- Tools/products/workflows:
- Index z or reconstructed features for scalable DAM systems; integrate with text encoders for multimodal search.
- Assumptions/dependencies:
- Careful evaluation of retrieval accuracy vs. original encoders; governance for sensitive content.
Common Dependencies and Risks Across Applications
- Pretrained encoder availability and licensing (DINOv2, SigLIP2); commercial use may require additional rights.
- Pixel decoder quality and domain fit; often needs fine-tuning for new content/style domains.
- Text-to-image performance is limited by text encoder strength and data scale; larger corpora may be required for SOTA.
- Safety: latent preservation of semantics is a double-edged sword—great for retrieval and control, but also implies reconstruction risk; add privacy and safety layers.
- Compute: while training is faster in z-space, diffusion still needs sampling steps; adoption of few-step samplers or flows improves inference viability.
- Legal/regulatory: synthetic content labeling, watermarking, and bias audits are recommended for production.
In summary, the paper’s minimal FAE design enables a practical, modular “semantic latent interface” between strong SSL vision encoders and multiple classes of generators. It supports immediate gains in training efficiency and portability for current image generation pipelines, and it opens longer-term paths to standardized, semantically faithful, and computation-efficient multimodal generation across devices and sectors.
Glossary
- AutoRegressive (AR): A generative modeling paradigm that predicts tokens step-by-step in sequence, conditioning on previously generated tokens. "AutoRegressive (AR)"
- Classifier-free guidance (CFG): A sampling technique that steers generative models toward conditioning (e.g., class or text) by interpolating between conditional and unconditional predictions. "For generation with CFG, we use ODE and runs 250 steps."
- DINOv2: A self-supervised Vision Transformer representation model trained on large-scale data to produce robust visual features. "DINOv2~\citep{dinov2}"
- DiT: Diffusion Transformer; a transformer-based architecture for denoising in diffusion models. "DiT~\citep{dit}"
- Diffusion models: Generative models that iteratively denoise corrupted inputs to synthesize samples from complex data distributions. "diffusion models \citep{ho2020ddpm, saharia2021image,ldm} have significantly advanced the quality and flexibility of visual generation"
- Double-decoder: A design that separates feature reconstruction from pixel synthesis by using one decoder for features and another for images. "This ``double-decoder'' design lets us preserve the semantics of the frozen encoder while giving the pixel decoder the flexibility needed for high-fidelity image generation."
- Feature Auto-Encoder (FAE): The proposed framework that compresses pretrained visual features into a compact latent for generation and reconstructs them with lightweight decoders. "we propose \model{} (Feature Auto-Encoder), a simple-yet-effective framework"
- FID: Fréchet Inception Distance; a metric that measures similarity between generated and real image distributions via statistics of Inception features. "attains a near–state-of-the-art FID of 1.29 (800 epochs)"
- Inception Score (IS): A generation quality metric that evaluates both the confidence and diversity of class predictions from a pretrained Inception network. "gFID & sFID & IS & Pre. & Rec."
- KL regularization term: The Kullback–Leibler divergence penalty in VAE training that encourages the latent distribution to match a prior. "a standard VAE objective consisting of an reconstruction term and a KL regularization term:"
- Latent Diffusion Models: Diffusion models that operate in a compressed latent space learned by an autoencoder, improving efficiency. "Latent Diffusion Models"
- Latent space: A lower-dimensional representation where generative models perform denoising or transformation instead of raw pixel space. "operate in compressed latent spaces to balance training efficiency and sample quality"
- LightningDiT: A DiT variant incorporating architectural improvements (e.g., RMSNorm, RoPE, SwiGLU) for faster, more stable training. "LightningDiT~\citep{vavae}"
- Linear probing: Evaluating representation quality by training a linear classifier on frozen features for a downstream task. "ImageNet Linear Probing top-1 accuracy comparison"
- Normalizing flow: A family of generative models that transform simple base distributions into complex ones via invertible mappings. "normalizing flow based models such as TARFlow~\citep{zhai2024normalizing} and STARFlows~\citep{gu2025starflow,gu2025starflowv}"
- ODE sampler: An ordinary differential equation-based sampler used to deterministically integrate reverse diffusion dynamics. "we use ODE and runs 250 steps."
- Patch embeddings: Vector representations of image patches produced by a Vision Transformer encoder. "operates across patch embeddings to remove redundant global information"
- Perceptual loss: A training objective that compares high-level features (e.g., from a pretrained network) of generated and real images to improve visual fidelity. "the perceptual loss aligns high-level features with the ground-truth images"
- REPA: A representation alignment method that ties diffusion hidden features to pretrained ViT embeddings to enhance training stability and fidelity. "REPA~\citep{repa} proposes to align noisy hidden features of diffusion transformers with clean image embeddings from a pretrained ViT"
- RoPE: Rotary Positional Embedding; a positional encoding technique for transformers that enables better extrapolation and relative positioning. "Rotary Positional Embedding (RoPE)~\citep{rope}"
- RMSNorm: Root Mean Square Layer Normalization; a normalization variant that can improve stability and efficiency in transformer training. "RMSNorm~\citep{rmsnorm}"
- SDE sampler: A stochastic differential equation-based sampler used in diffusion models for stochastic reverse-time integration. "For generation without CFG \citep{cfg}, we use SDE \citep{sde} and runs 250 steps."
- Self-supervised learning (SSL): A paradigm that trains models on proxy tasks using unlabeled data to learn transferable representations. "Self-supervised learning (SSL) has become a cornerstone for learning general visual representations without manual labels."
- SigLIP2: A vision-language encoder producing dense visual and text features with strong semantic understanding and localization. "SigLIP2~\citep{siglip2}"
- SiT: A transformer-based latent diffusion architecture used for scalable image generation. "SiT~\citep{sit}"
- SwiGLU: A gated activation function variant used in transformers that can improve training stability and performance. "SwiGLU activations~\citep{swiglu}"
- Timestep shift: A training trick that adjusts the diffusion time weighting or schedule to improve convergence and generation quality. "\model\ w/ Timestep Shift"
- Variational Autoencoder (VAE): A probabilistic autoencoder that learns a latent distribution for data, enabling reconstruction and generative sampling. "variational autoencoders (VAEs)"
- Vision Transformer (ViT): A transformer architecture for images that processes sequences of patch embeddings to learn global visual features. "Vision Transformers (ViTs)~\citep{dosovitskiy2020vit}"
- Zero-shot: Evaluating or adapting a model to a task without task-specific training using only pretrained representations. "zero-shot evaluated on MS-COCO using 30K example."
Collections
Sign up for free to add this paper to one or more collections.