SSDD: Single-Step Diffusion Decoder for Efficient Image Tokenization
Abstract: Tokenizers are a key component of state-of-the-art generative image models, extracting the most important features from the signal while reducing data dimension and redundancy. Most current tokenizers are based on KL-regularized variational autoencoders (KL-VAE), trained with reconstruction, perceptual and adversarial losses. Diffusion decoders have been proposed as a more principled alternative to model the distribution over images conditioned on the latent. However, matching the performance of KL-VAE still requires adversarial losses, as well as a higher decoding time due to iterative sampling. To address these limitations, we introduce a new pixel diffusion decoder architecture for improved scaling and training stability, benefiting from transformer components and GAN-free training. We use distillation to replicate the performance of the diffusion decoder in an efficient single-step decoder. This makes SSDD the first diffusion decoder optimized for single-step reconstruction trained without adversarial losses, reaching higher reconstruction quality and faster sampling than KL-VAE. In particular, SSDD improves reconstruction FID from $0.87$ to $0.50$ with $1.4\times$ higher throughput and preserve generation quality of DiTs with $3.8\times$ faster sampling. As such, SSDD can be used as a drop-in replacement for KL-VAE, and for building higher-quality and faster generative models.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper introduces SSDD, which stands for Single-Step Diffusion Decoder. It’s a new way for computers to turn a small, compressed version of an image back into a full picture quickly and with high quality. It’s designed to help image generators (like AI that creates pictures) work faster without making the pictures look fake or blurry.
What the researchers wanted to figure out
- How can we decode images from compact “tokens” (tiny summaries of images) in just one step while keeping the pictures sharp and realistic?
- Can we avoid using tricky training methods like GANs (which are powerful but hard to train) and still get state-of-the-art quality?
- Can a diffusion-based decoder be both fast and good enough to plug into popular image generators and make them run faster?
How they did it (explained simply)
Think of an image tokenizer like a zip file for pictures:
- The encoder compresses a picture into a small code (tokens).
- The decoder unzips it back into a full image.
SSDD improves the decoder side. Here’s the approach, with everyday analogies:
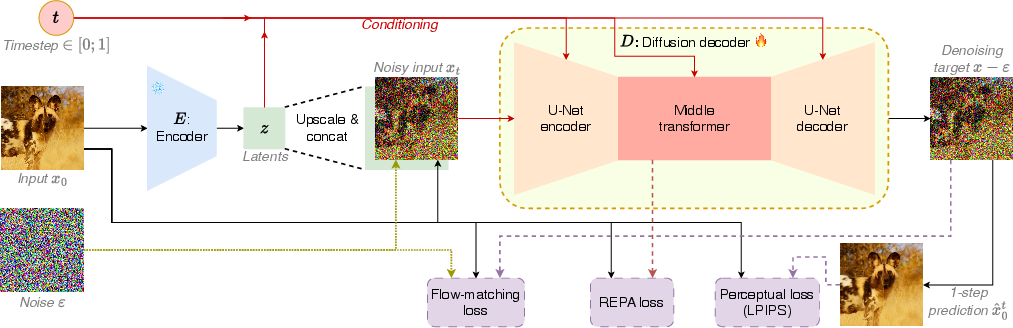
- Diffusion decoding: Imagine you have a noisy, fuzzy version of a picture. A diffusion model learns how to clean it step by step until it looks real. SSDD trains this “cleaning” process, but later compresses it so it can do the cleaning in a single jump.
- Flow matching: Instead of guessing the final picture all at once, the model learns the direction from noise to the clean image (like following a GPS route from “blurry” to “clear”). This makes training stable and effective.
- No GAN needed: GANs are like a tough art teacher who constantly criticizes your drawings. They can improve realism, but they’re hard to handle. SSDD avoids GANs entirely by combining:
- A perceptual loss (LPIPS): compares images in a way that’s closer to how people see, not just pixel-by-pixel.
- A feature regularizer (REPA): keeps the model’s internal “thinking” consistent and stable, like good study habits.
- Smarter architecture: SSDD mixes two powerful ideas:
- U-Net (great at seeing local details like edges and textures).
- Transformer blocks (great at understanding global patterns).
- You can think of this like having both a magnifying glass for details and a wide-angle lens for overall structure.
- Single-step distillation (teacher–student idea): First, a “teacher” model learns to clean images in several steps (multi-step diffusion). Then a “student” model is trained to copy the teacher’s results in one step. It’s like learning to solve a long math problem in your head after seeing how it’s done on paper.
- Shared encoders: SSDD can work with standard encoders used by many image models today. That means it fits well with existing systems without retraining everything from scratch.
What they found and why it matters
- High quality, much faster: SSDD produces more realistic reconstructions than popular decoders (like KL-VAE), while running very fast. On a standard benchmark:
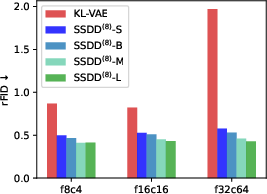
- It improved a realism score (FID for reconstructions, or rFID) from about 0.87 to 0.50 with higher throughput.
- When used inside a full image generator, it enabled up to 3.8× faster image creation with similar or better quality.
- One step, not many: After distillation, SSDD can decode in a single step with only a tiny drop in quality compared to multi-step diffusion—this is a big win for speed.
- No adversarial training: It matches or beats state-of-the-art results without GANs, making training simpler and more stable.
- Works even when images are heavily compressed: SSDD keeps quality higher than older decoders when the image is squeezed into very small tokens, which is important for fast, large-scale models.
- Better downstream generation: When plugged into a strong image generator (DiT), SSDD improved the final image quality (lower gFID) and increased generation speed.
Note on metrics:
- FID/rFID: lower is better; measures how “real” images look overall.
- LPIPS/DreamSim: lower is better; measure visual similarity in a human-like way.
- PSNR/SSIM: higher is better; measure pixel-level match (these can look good even when images feel less natural to humans). SSDD focuses more on what looks real to people.
Why this could be important
- Faster creative tools: Single-step high-quality decoding can make AI image tools snappier for artists, designers, and apps.
- Easier to scale: No GAN training means fewer stability issues and easier training at large sizes.
- Better compression for generation: By working well with stronger compression, SSDD helps big models run faster and cheaper.
- A cleaner foundation: SSDD shows diffusion decoders can be both practical and top-quality, which could guide the next wave of image and video generators.
In short, SSDD shows you can get the best of both worlds: the realism of diffusion models and the speed of one-step decoders—without the headaches of adversarial training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues and open questions that emerge from the paper. Each item highlights what is missing, uncertain, or left unexplored, in ways that could guide follow-up research.
- Dataset and domain generalization:
- Results are limited to ImageNet-1k at 128–512 resolutions; no evaluation on other domains (faces, medical, satellite, artwork) or out-of-distribution robustness.
- No assessment at higher resolutions (e.g., 1K–4K) where local attention windows and upsampled conditioning could become limiting.
- Human perceptual evaluation:
- Reliance on rFID, LPIPS, and DreamSim without human studies; the correlation of these metrics with perceived quality across diverse content remains unvalidated.
- No error bars or statistical significance analyses of FID/LPIPS across seeds or runs.
- Low-level fidelity and pixel-accurate tasks:
- SSDD sacrifices PSNR/SSIM compared to some baselines; the impact on tasks requiring pixel fidelity (e.g., compression benchmarks, forensic/medical use-cases, precise image editing, steganography) is unquantified.
- No rate–distortion analysis (e.g., bits per pixel, RD curves) despite positioning as a tokenizer; compression efficiency vs. quality is not reported.
- Conditional diversity and stochasticity:
- The single-step distilled decoder’s conditional diversity (multiple plausible reconstructions for a fixed latent z) is not measured (e.g., conditional coverage, precision/recall, intra-z diversity).
- It is unclear whether single-step decoding collapses stochastic variation versus multi-step decoding; no controllability of diversity (e.g., via noise amplitude “temperature”) is presented.
- Distillation design and generality:
- The distillation uses t=1 alignment to an 8-step teacher; no study of varying N, schedules, or t-values during distillation for better speed–quality–diversity trade-offs.
- Limited evidence on how distillation scales with compression strength (e.g., f16c4 vs. f32c64) or larger teacher step counts; does the “minimal quality drop” hold universally?
- Ambiguity in the description of the LPIPS target during distillation (teacher outputs vs. ground-truth) may affect reproducibility and needs clarification.
- Architecture constraints:
- The fixed 17×17 local attention window may limit long-range dependencies at large resolutions; no ablation on window size, global tokens, or hybrid global-local attention.
- Only one latent-transformer “middle block” is used; scaling laws across deeper transformer stacks or full-transformer U-Nets are not explored.
- Conditioning mechanism:
- Conditioning by upsampling z to H×W and concatenation could be bandwidth-inefficient at high f; no comparison to cross-attention, FiLM, or learned spatial adapters.
- No analysis of how conditioning depth and location (e.g., early vs. late fusion) affect performance and stability.
- Training objectives and schedules:
- Flow matching with σmin=0 and logit-normal t-sampling is fixed; no comparison to alternative flows/schedules (e.g., EDM, VP/VE SDEs, Rectified Flow schedules).
- Loss weight sensitivity (λLPIPS, λREPA) and robustness across scales/datasets are unstudied.
- The benefits and limitations of REPA regularization are not dissected (e.g., dependence on DINOv2 backbone/layers, transferability beyond ImageNet semantics).
- GAN-free claim scope:
- While GAN-free training matches/adapts to the reported setting, conditions under which adversarial losses might still help (e.g., extremely high compression, texture-rich domains) are not characterized.
- Shared encoder limitations:
- The “near-optimal” claim for a shared encoder is weakly quantified; the performance gap versus fully joint training per decoder size is not systematically measured.
- Interoperability across heterogeneous encoders is lightly tested (KL-VAE/DiTo), but a universal decoder that robustly handles multiple latent conventions is not demonstrated.
- Downsampling and compression extremes:
- Although f2×c is held constant in one analysis, behavior at more extreme compression (e.g., f=32 with very low c) is not evaluated for generation tasks; reconstruction-only evidence may not transfer.
- Downstream generative modeling scope:
- Only class-conditional DiT at 256 is studied; no evaluation with text-to-image models, video generation, or masked/conditional editing pipelines where decoders can materially affect controllability.
- Co-adaptation effects between the latent model and SSDD (e.g., training schedules, compute parity, overfitting to decoder biases) are not analyzed.
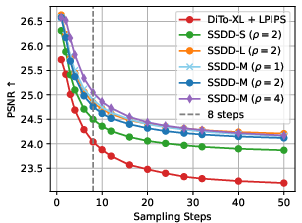
- Perception–distortion controllability at inference:
- SSDD fixes N=8 and ρ=2 for the teacher; mechanisms to continuously adjust the perception–distortion trade-off at inference (e.g., noise scaling, guidance-like knobs) are not provided.
- Speed and resource reporting:
- Throughput comparisons lack standardized hardware specs, batch sizes, and memory usage; latency and energy efficiency (especially on edge devices) are not reported.
- Training compute, distillation overhead, and total cost vs. VAEs/diffusion decoders are unreported.
- Failure modes and robustness:
- No qualitative or quantitative analysis of typical failure cases (e.g., over-sharpening, texture hallucinations, fine text/small objects, color fidelity, artifacts under high compression).
- Robustness to corruptions/perturbations (noise, blur, JPEG, color shifts) is not evaluated.
- Theoretical understanding:
- No theoretical explanation for why multi-step diffusion behavior can be compressed into a single-step generator with minimal quality loss; bounds or conditions for success are missing.
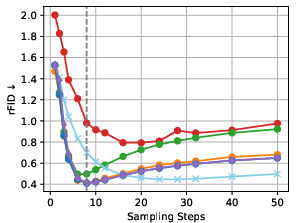
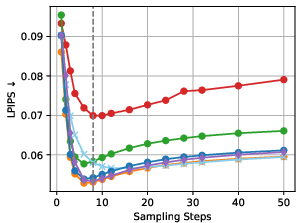
- The non-monotonic relationship between steps and perception metrics is noted but not formally analyzed beyond heuristics; predictive models of this trade-off are absent.
- Multiscale training and transfer:
- Two-stage training (128→target) is presented, but the optimality vs. full-resolution training and its limits across very high resolutions remain untested.
- Fairness and ethics:
- No analysis of bias propagation from DINOv2 features (REPA) or potential demographic/attribute-specific performance disparities.
- Memorization/privacy risks of using more generative decoders (e.g., unintended detail hallucination that resembles training images) are not assessed.
- Evaluation breadth:
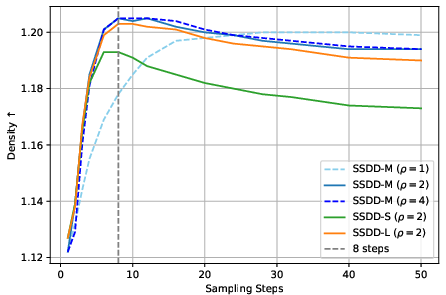
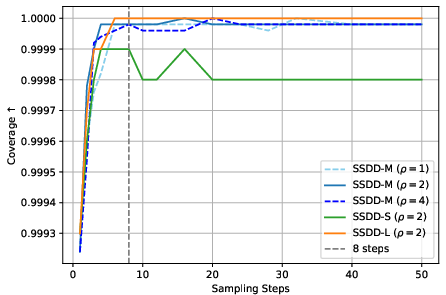
- Generation quality is assessed primarily with gFID; complementary measures (Precision/Recall, Density/Coverage, CLIP-Score for alignment, human preference tests) are absent.
- No ablations comparing SSDD to state-of-the-art single-step distillation baselines (e.g., consistency models, rectified-flow distillations) under identical encoder/compute constraints.
- Editability and invertibility:
- Impact of a generative (non-deterministic) decoder on deterministic latent editing workflows and exact inversion (pixel-level reproducibility) is not studied.
- Universality across latent shapes:
- While f and c are varied, generalization to non-grid latents (e.g., 1D/token-sequences, hierarchical latents) is not explored, despite relevance to modern AR/LLM-style vision models.
Glossary
- AdaGN (Adaptive group-normalization): A conditioning mechanism that modulates normalization layers using time or other signals in diffusion models. "We embed time using adaptive group-normalization (AdaGN) \citep{diffusion_beats_gan_NEURIPS2021_49ad23d1} as the second normalization layer in ResNet blocks."
- AdaLN (Adaptive layer normalization): A conditioning mechanism that adapts layer normalization parameters based on conditioning inputs (e.g., latents or time). "We replace the first GroupNorm of ResNet blocks with AdaGN, % and the first LayerNorm of transformer blocks by AdaLN \citep{dit_scalable_diffusion_Peebles_2023_ICCV}."
- Autoencoder: A model that compresses inputs into latent representations and reconstructs them back to the original space. "For generative modeling, tokenizers are usually trained as autoencoders."
- Autoregressive modeling: A generative approach that models data by predicting each element conditioned on previous ones. "Current state-of-the-art image generation models, whether they are based on diffusion~\citep{sd1_Rombach_2022_CVPR}, flow matching~\citep{sd3_pmlr-v235-esser24a} or autoregressive modeling~\citep{vqgan_taming_transformers_high_res,var_NEURIPS2024_9a24e284}, rely on tokenizers..."
- Classifier-free guidance (CFG): A sampling technique that improves conditional generation quality by interpolating between conditional and unconditional predictions. "evaluating the generation FID (gFID) without classifier-free guidance~(CFG)~\citep{cfg_ho2021classifierfree} or, if specified, with a CFG of 1.375."
- Consistency models: Distilled generators designed for few-step or single-step sampling that match a teacher diffusion model’s behavior. "Consistency models~\citep{consistency_pmlr-v202-song23a,improved_consistency_song2024improved,luo2023latentconsistencymodelssynthesizing} distill pre-trained diffusion model capabilities into new few-step tailored generator models."
- Density and Coverage: Metrics that assess how well generated samples cover the data distribution and how densely they populate it. "Metrics commonly used to evaluate distribution shift of generative models include Fréchet Inception Distance (FID)~\citep{FID_metric_NIPS2017_8a1d6947}, or Density and Coverage~\citep{density_coverage_pmlr-v119-naeem20a}."
- DINOv2-B: A pretrained vision transformer model used to extract robust features for alignment or evaluation. "We use DINOv2-B~\citep{dinov2_oquab2024dinov} reference features for REPA..."
- DiT (Diffusion Transformer): A transformer-based architecture for diffusion in latent space, offering scalability in generative modeling. "We train Diffusion Transformer models~\citep{dit_scalable_diffusion_Peebles_2023_ICCV} on ImageNet-1k at resolution..."
- Distribution shift: The divergence between the distribution of original data and that of reconstructions or generated samples. "(ii) Distribution shift: expressed as $d(P_x,P_{\hat{x})$, with being a measure of the divergence between reference and reconstructed distributions."
- Distortion–Perception trade-off: A fundamental trade-off where minimizing pixel-level distortion can harm perceptual realism and vice versa. "As shown by \citet{Blau_2018_CVPR}, there exists a fundamental trade-off between these two different notions of reconstruction quality (referred to as Distortion and Perception by them)..."
- DreamSim: A perceptual similarity metric derived from deep features for high-level comparison of images. "Distortion can be quantified by low-level similarity metrics such as MSE, MAE, PSNR and SSIM, or by high-level metrics based on features found in trained deep neural networks, such as LPIPS~\citep{lpips_Zhang_2018_CVPR} and DreamSim~\citep{dreamsim_fu23arxiv}."
- EMA (Exponential Moving Average): A training stabilization technique maintaining a smoothed copy of model weights. "and the commonly-used stronger performing ft-EMA VAE~\citep{dit_scalable_diffusion_Peebles_2023_ICCV}, which we refer to as SD-VAE."
- Flow matching: A training objective that estimates the velocity field transporting noise to data, enabling efficient diffusion-like generative modeling. "We train our model using the optimal transport flow-matching loss~\citep{flow_matching_lipman2023flow} with ."
- Fréchet Inception Distance (FID): A metric comparing distributions of Inception features between real and generated images. "Metrics commonly used to evaluate distribution shift of generative models include Fréchet Inception Distance (FID)~\citep{FID_metric_NIPS2017_8a1d6947}..."
- gFID (generation FID): FID measured on samples produced by a generative model rather than reconstructions. "train DiT-XL/2 models for 400k steps and evaluating the generation FID (gFID) without classifier-free guidance~(CFG)..."
- GAN loss: An adversarial objective used to improve realism by training a discriminator alongside the generator. "Additionally, stable scaling of GAN losses is non-trivial~\citep{biggan_brock2018large}."
- GEGLU (Gated GELU) activation: An activation function variant that gates GELU for improved transformer performance. "Each transformer block uses the GEGLU activation function~\citep{geglu_shazeer2020gluvariantsimprovetransformer}..."
- KL regularization: A Kullback–Leibler divergence penalty that shapes the latent distribution in VAEs. "Common tokenizers such as the KL-VAE from~\citet{sd1_Rombach_2022_CVPR} are optimized with L1 reconstruction loss, LPIPS~\citep{lpips_Zhang_2018_CVPR}, and a GAN discriminator~\citep{goodfellow14nips}, to which a KL-regularization of the latent space is added."
- KL-VAE: A VAE-based tokenizer trained with KL divergence regularization and perceptual/adversarial losses. "Common tokenizers such as the KL-VAE from~\citet{sd1_Rombach_2022_CVPR} are optimized with L1 reconstruction loss, LPIPS~\citep{lpips_Zhang_2018_CVPR}, and a GAN discriminator~\citep{goodfellow14nips}, to which a KL-regularization of the latent space is added."
- Logit-normal distribution: A probability distribution used to sample diffusion times biased toward endpoints after a logit transform. "Following \citet{sd3_pmlr-v235-esser24a}, we sample during training using the logit-normal distribution \citep{atchison1980logistic} with location and scale ."
- LPIPS (Learned Perceptual Image Patch Similarity): A feature-based perceptual similarity metric correlating with human judgment. "We therefore add the LPIPS \citep{lpips_Zhang_2018_CVPR} loss $L_{\LPIPSFN}=\LPIPSFN(x,\hat{x}_0)$..."
- Multi-head attention: A transformer mechanism that attends to information from multiple representation subspaces in parallel. "Each transformer block uses the GEGLU activation function~..., and multi-head attention~\citep{attention_is_all_you_need_NIPS2017_3f5ee243}."
- Optimal transport: A mathematical framework for transporting one distribution to another with minimal cost; here used in the flow-matching objective. "We train our model using the optimal transport flow-matching loss~\citep{flow_matching_lipman2023flow}..."
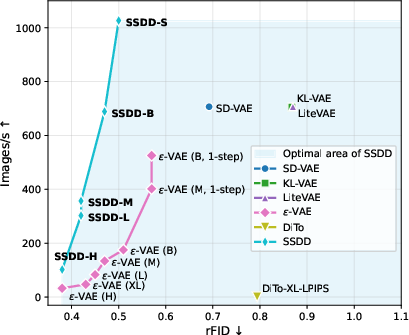
- Pareto-front: The set of optimal trade-offs between two competing objectives where improving one worsens the other. "Left: Speed-quality Pareto-front for different state-of-the-art f8c4 feedforward and diffusion autoencoders."
- Pixel-space diffusion decoder: A diffusion-based generator that operates directly on pixels rather than latents. "Pixel-space diffusion decoders mainly leverage the same convolutional U-Net architectures~\citep{evae_zhao2025epsilonvaedenoisingvisualdecoding} that were found successful in early pixel-space diffusion models~\citep{diffusion_beats_gan_NEURIPS2021_49ad23d1}."
- PSNR (Peak Signal-to-Noise Ratio): A distortion metric measuring pixel-level reconstruction fidelity relative to noise. "Distortion can be quantified by low-level similarity metrics such as MSE, MAE, PSNR and SSIM..."
- REPA loss: A representation alignment regularizer that aligns intermediate model features with reference features to stabilize training. "we further stabilize and accelerate our training by adding the REPA loss~\citep{repa_yu2025representation}, denoted as $L_{\REPAFN}$."
- Relative positional embedding: A mechanism encoding relative positions between tokens to inject spatial inductive bias into attention. "we learn a relative positional embedding table~\citep{relative_pos_shaw2018selfattentionrelativepositionrepresentations} for each self-attention layer, with visual tokens only attending to tokens up to a distance of $8$..."
- ResNet blocks: Residual network blocks composed of convolutional layers with skip connections, used here within the U-Net. "using four levels of two convolutional ResNet blocks and three convolution downsampling / upsampling layers"
- rFID (reconstruction FID): FID computed between original images and their reconstructions to quantify distribution shift in autoencoders. "For reconstruction, we assess the distribution shift using the reconstruction Fréchet Inception Distance~(rFID)~\citep{FID_metric_NIPS2017_8a1d6947}."
- Single-step distillation: A training strategy that transfers multi-step diffusion behavior into a one-step decoder for fast sampling. "(3) A single-step distillation method for SSDD with minimal quality impact, making it both the highest quality and fastest diffusion decoder..."
- Tokenizer: A module that compresses images into compact latent codes for efficient generative modeling. "Current state-of-the-art image generation models... rely on tokenizers as a key component to reduce the high-dimensional visual signal to compact latent representations."
- U-Net: A convolutional encoder–decoder architecture with skip connections commonly used for image-to-image tasks and diffusion. "Diffusion decoders~\citep{dae_Preechakul_2022_CVPR,...} introduce an alternative decoder architecture usually based on U-Net models~\citep{unet_2015}..."
- U-ViT: A hybrid architecture combining U-Net structure with transformer blocks for diffusion in pixel space. "We base our architecture on the U-ViT~\citep{hoogeboom23simple} with several modifications."
- Velocity field: The vector field defining the direction and magnitude of transport from noise to data in flow matching. "our decoder is trained to predict the velocity field with the L2 loss."
Practical Applications
Immediate Applications
The following applications can be deployed now using SSDD’s single-step diffusion decoder, GAN-free training recipe, and shared-encoder compatibility.
- Faster, drop-in decoder upgrades for existing latent diffusion pipelines
- Sectors: software, media/entertainment, cloud AI services
- Use case: Replace KL-VAE or multi-step diffusion decoders in Stable Diffusion/DiT-style systems with SSDD to reduce decoding latency and compute by 3–4× while improving generative rFID/LPIPS/DreamSim and preserving image quality at high compression.
- Tools/products/workflows: SSDD decoder library integrated via ONNX/TensorRT; shared encoder compatibility with f8c4/f16c4; one-step sampling; scheduler tuned for perception.
- Assumptions/dependencies: Access to the encoder latent format (e.g., KL-VAE f8c4); SSDD weights and code; performance validated on the target domain beyond ImageNet.
- Lower-cost, more stable tokenizer training for new generative models
- Sectors: academia, software/AI product R&D, cloud ML platforms
- Use case: Train tokenizers without adversarial losses using flow matching + LPIPS + REPA, simplifying training, improving stability/scalability, and avoiding brittle GAN objectives.
- Tools/products/workflows: Training recipes with FM loss, perceptual alignment (LPIPS), REPA feature regularization (DINOv2), multi-scale fine-tuning; U-ViT-based decoder architecture.
- Assumptions/dependencies: Availability of compute for pretraining; DINOv2 features for REPA; correct scheduler/timestep sampling; generalization to the target dataset.
- Real-time or on-device image generation and editing
- Sectors: consumer mobile apps, creative tooling, AR/VR
- Use case: Single-step decoding enables on-device inpainting, super-resolution, style transfer, and filter application with lower latency and memory footprint.
- Tools/products/workflows: Mobile SDKs with SSDD-S/M decoders; hardware acceleration via NPU/GPU; workflows for per-image latent caching and instant reconstruction.
- Assumptions/dependencies: Efficient model quantization; domain adaptation from ImageNet; user-acceptable perception-focused quality over pixel-perfect fidelity.
- Generative image compression for storage and serving
- Sectors: cloud storage/CDNs, social platforms, digital asset management
- Use case: Store latents (e.g., f16c4) instead of full-resolution images; reconstruct on demand with SSDD for reduced storage and bandwidth while preserving perceptual quality.
- Tools/products/workflows: Latent cache store; server-side SSDD decoding; interfaces for reconstruction budgets (quality/speed trade-offs).
- Assumptions/dependencies: Acceptance of generative reconstructions (lower PSNR/SSIM but better rFID/LPIPS); compliance and forensic requirements; domain-specific fine-tuning.
- Faster training and inference for diffusion transformers using higher compression
- Sectors: AI research, MLOps, cloud inference platforms
- Use case: Use f16c4 latents with SSDD-L/H decoders to reduce feature-map sizes and accelerate end-to-end generation throughput by up to 3.8× without quality loss.
- Tools/products/workflows: Training pipelines with f16c4 encoders; SSDD one-step decoders; generation FID monitoring; CFG-sensitive scheduling.
- Assumptions/dependencies: Upstream model compatibility with the chosen latent resolution; validation of perception metrics for the target content.
- Shared-encoder strategy for modular generative stacks
- Sectors: platform engineering, foundation model builders
- Use case: Train and freeze a single encoder per compression setting (f,c), and swap decoders (S→H) as needed to balance speed and quality without retraining the upstream generative model.
- Tools/products/workflows: Encoder registry; multi-resolution augmentation; decoders scaled from SSDD-S to SSDD-H using the same latents.
- Assumptions/dependencies: Encoder generalization across resolutions; organizational discipline to version encoders/decoders and track metrics.
- Energy, cost, and throughput gains for large-scale inference
- Sectors: cloud providers, policy/compliance, sustainability teams
- Use case: Replace multi-step diffusion decoders with SSDD single-step to cut GPU-hours and carbon footprint, enabling greener AIGC pipelines at scale.
- Tools/products/workflows: Cost/energy dashboards; per-model CO2 estimates; policy targets for inference efficiency; batch scheduling optimized for one-step decoding.
- Assumptions/dependencies: Availability of SSDD deployment artifacts; measurement frameworks that value perceptual/distribution metrics, not just PSNR.
- Safe applications in healthcare and science for non-diagnostic tasks
- Sectors: healthcare, life sciences
- Use case: Use SSDD for patient education visuals, anonymized mock-ups, or dataset augmentation (not diagnostics) where perceptual realism is valued over exact pixel fidelity.
- Tools/products/workflows: Controlled pipelines with domain-specific pretraining; clear disclaimers; QA procedures focusing on distributional metrics.
- Assumptions/dependencies: Regulatory acceptance; clear separation from diagnostic workflows; rigorous bias and artifact assessment.
- Dataset distillation and latent indexing for rapid experimentation
- Sectors: academia, enterprise ML research
- Use case: Cache compressed latents for large image datasets to accelerate prototyping, training runs, and retrieval-based generation.
- Tools/products/workflows: Latent indexing services; pipelines for fast reconstruction with SSDD; retrieval augmentation against latent spaces.
- Assumptions/dependencies: Coverage of target image distributions; storage for latent repositories; robust mapping between latents and metadata.
Long-Term Applications
The following applications require further research, scaling, domain adaptation, standardization, or hardware support.
- Standardized generative image/video codecs
- Sectors: telecom, web standards, consumer electronics, CDNs
- Use case: Evolve SSDD into a standardized codec replacing parts of JPEG/AVIF/HEVC pipelines with generative decoders, targeting substantial bitrate savings at similar perceived quality.
- Tools/products/workflows: Bitstream specifications; hardware accelerators; reference implementations; perceptual/distributional quality standards.
- Assumptions/dependencies: Broad industry consensus; robust fairness and artifact audits; regulatory alignment on generative compression.
- Real-time generative video compression and streaming
- Sectors: AR/VR, live streaming, remote collaboration
- Use case: Extend SSDD to temporally consistent video decoders that maintain quality at low bitrates and low latency for immersive applications.
- Tools/products/workflows: Temporal modeling modules; motion-aware latents; streaming protocols; client-side single-step decoders.
- Assumptions/dependencies: New architectures for temporal coherence; motion conditioning; strong empirical validation on video datasets.
- Camera ISP integration and edge AI pipelines
- Sectors: smartphones, drones, robotics, automotive
- Use case: Use single-step generative decoders for super-resolution, denoising, HDR reconstruction, and semantic enhancement directly in the imaging pipeline on NPUs.
- Tools/products/workflows: Specialized training on sensor-domain data; quantized SSDD models; offline/online calibration; safety guards for hallucinations.
- Assumptions/dependencies: Strong domain adaptation; hardware constraints; predictability and robustness under environmental shifts.
- Multimodal foundation model tokenization
- Sectors: foundation models, enterprise AI platforms
- Use case: Extend shared-encoder/decoder concepts to cross-modal tokenizers (image, video, audio) enabling unified, efficient latents for multimodal generation and reasoning.
- Tools/products/workflows: Cross-modal REPA-like alignments; shared latent spaces; multimodal training pipelines; task-specific decoders.
- Assumptions/dependencies: Advances in multimodal representation alignment; new loss formulations; careful evaluation across modalities.
- Scientific imaging and large-scale data archiving
- Sectors: astronomy, microscopy, remote sensing
- Use case: Compress petabytes of scientific imagery with perception-first decoders, combined with metadata constraints to preserve relevant signals while reducing storage costs.
- Tools/products/workflows: Domain-calibrated loss terms; artifact detection; hybrid pipelines (lossless channels for critical measurements + generative visuals for context).
- Assumptions/dependencies: Community consensus on acceptable generative artifacts; rigorous validation protocols; mixed-fidelity storage designs.
- Federated and privacy-preserving ML with latent transport
- Sectors: finance, healthcare, regulated industries
- Use case: Share latents instead of raw images for federated training and inference, enhancing privacy while retaining generative utility.
- Tools/products/workflows: Secure latent exchange formats; differential privacy overlays; audit trails; reconstruction risk assessments.
- Assumptions/dependencies: Regulatory approval; robust de-anonymization safeguards; empirical guarantees against leakage via decoding.
- Policy and standards for perception-centric evaluation
- Sectors: policy/governance, standards bodies, procurement
- Use case: Shift evaluation norms from PSNR/SSIM to perceptual and distributional metrics (LPIPS, DreamSim, rFID/gFID) to better reflect user experience and generative fidelity.
- Tools/products/workflows: Benchmarks and certification suites; procurement guidelines; model reporting focused on energy + perceptual quality trade-offs.
- Assumptions/dependencies: Adoption across industry and academia; clear guidance to avoid misuse in sensitive applications; transparent metric calibration.
- Robustness, safety, and watermarking for generative decoders
- Sectors: platform trust & safety, digital forensics
- Use case: Develop watermarking/verification mechanisms for reconstructions, plus guardrails detecting excessive distributional shift or hallucinations in critical contexts.
- Tools/products/workflows: Invisible watermarking integrated into decoding; shift monitors; domain-specific thresholds; incident response tooling.
- Assumptions/dependencies: Reliable watermark schemes for generative content; adversarial robustness; coordination with forensic stakeholders.
- Automated co-design of compression and downstream generative tasks
- Sectors: enterprise ML, MLOps
- Use case: Jointly optimize the encoder (f,c), the downstream model, and the SSDD decoder for the target application (e.g., product imagery, maps, or designs) to minimize cost while maximizing task-specific quality.
- Tools/products/workflows: NAS/AutoML for tokenizer-decoder-task pipelines; perception-distortion budget management; data-centric iteration loops.
- Assumptions/dependencies: End-to-end training frameworks; task-aligned metrics; reliable transfer to production.
Notes on assumptions and dependencies across applications
- SSDD favors perceptual and distributional fidelity over exact pixel similarity. Applications requiring pixel-accurate reconstructions (e.g., medical diagnostics, forensics) need domain-specific validation or hybrid pipelines.
- Domain generalization beyond ImageNet will require fine-tuning and potentially custom feature alignment (REPA) backbones.
- Real-world deployments benefit from hardware acceleration (ONNX/TensorRT, NPU/GPU), quantization, and robust monitoring of perception-centric metrics.
- Shared encoders reduce retraining costs but require disciplined model versioning and compatibility tracking.
- Regulatory and policy adoption hinges on transparent metrics, energy accounting, watermarking, and clear risk boundaries for generative reconstructions.
Collections
Sign up for free to add this paper to one or more collections.

